Author: Denis Avetisyan
Deep learning is rapidly transforming our ability to instantly identify objects in images and videos, powering applications from autonomous vehicles to advanced robotics.
This review analyzes recent advancements in deep learning architectures, datasets, and practical challenges in the field of real-time object detection.
Despite advancements in computer vision, achieving robust and efficient real-time object detection remains a significant challenge across diverse applications. This paper, ‘A Study on Real-time Object Detection using Deep Learning’, provides a comprehensive analysis of deep learning methodologies employed to address this need, examining prevalent model architectures like \mathcal{N}=4 convolutional neural networks, YOLO, and transformer-based approaches. The study synthesizes insights from benchmark datasets and application-specific evaluations, demonstrating the performance trade-offs inherent in different detection strategies. Looking forward, what novel architectures and training paradigms will be necessary to unlock the full potential of real-time object detection in complex and dynamic environments?
From Handcrafted Features to Intelligent Perception
Early computer vision systems depended heavily on engineers meticulously designing features – edges, corners, textures – to help algorithms identify objects within images. This approach, while initially successful, proved remarkably inflexible and prone to failure when confronted with variations in lighting, viewpoint, or even simple occlusions. These handcrafted features required extensive tuning for each specific task and struggled to generalize across diverse datasets. A system trained to recognize a cat in a brightly lit studio, for example, might fail spectacularly when presented with a feline in dim lighting or partially hidden behind an object. This inherent brittleness significantly limited the scope and reliability of early computer vision applications, necessitating a shift toward more adaptable and robust methodologies.
The emergence of object detection represents a foundational leap in computer vision, moving beyond simple image classification to pinpointing and categorizing multiple objects within a single visual scene. This capability, achieved through advancements in deep learning architectures like convolutional neural networks, allows machines to ‘see’ and interpret images with a level of precision previously unattainable. Modern object detection systems now demonstrate an overall accuracy of 92% on challenging benchmark datasets such as COCO and Pascal VOC, signifying a robust performance across diverse visual contexts. This increased accuracy isn’t merely incremental; it unlocks entirely new applications, from detailed analysis of medical imagery to the reliable operation of autonomous vehicles, fundamentally altering how machines interact with and understand the visual world.
The practical implications of robust object detection extend far beyond simple image recognition, driving innovation across diverse fields. Autonomous vehicles critically rely on identifying and classifying objects – pedestrians, cyclists, other vehicles, traffic signals – in real-time to navigate safely and efficiently. Similarly, in advanced medical imaging, object detection algorithms assist clinicians in identifying anomalies such as tumors or fractures with greater speed and precision, potentially improving diagnostic accuracy and patient outcomes. This widespread utility, however, necessitates continuous refinement of detection capabilities; current systems, while achieving impressive accuracy, still face challenges in handling occlusions, varying lighting conditions, and rare or unusual objects, prompting ongoing research into more resilient and adaptable algorithms.
The Power of Learned Features: Convolutional Networks Unveiled
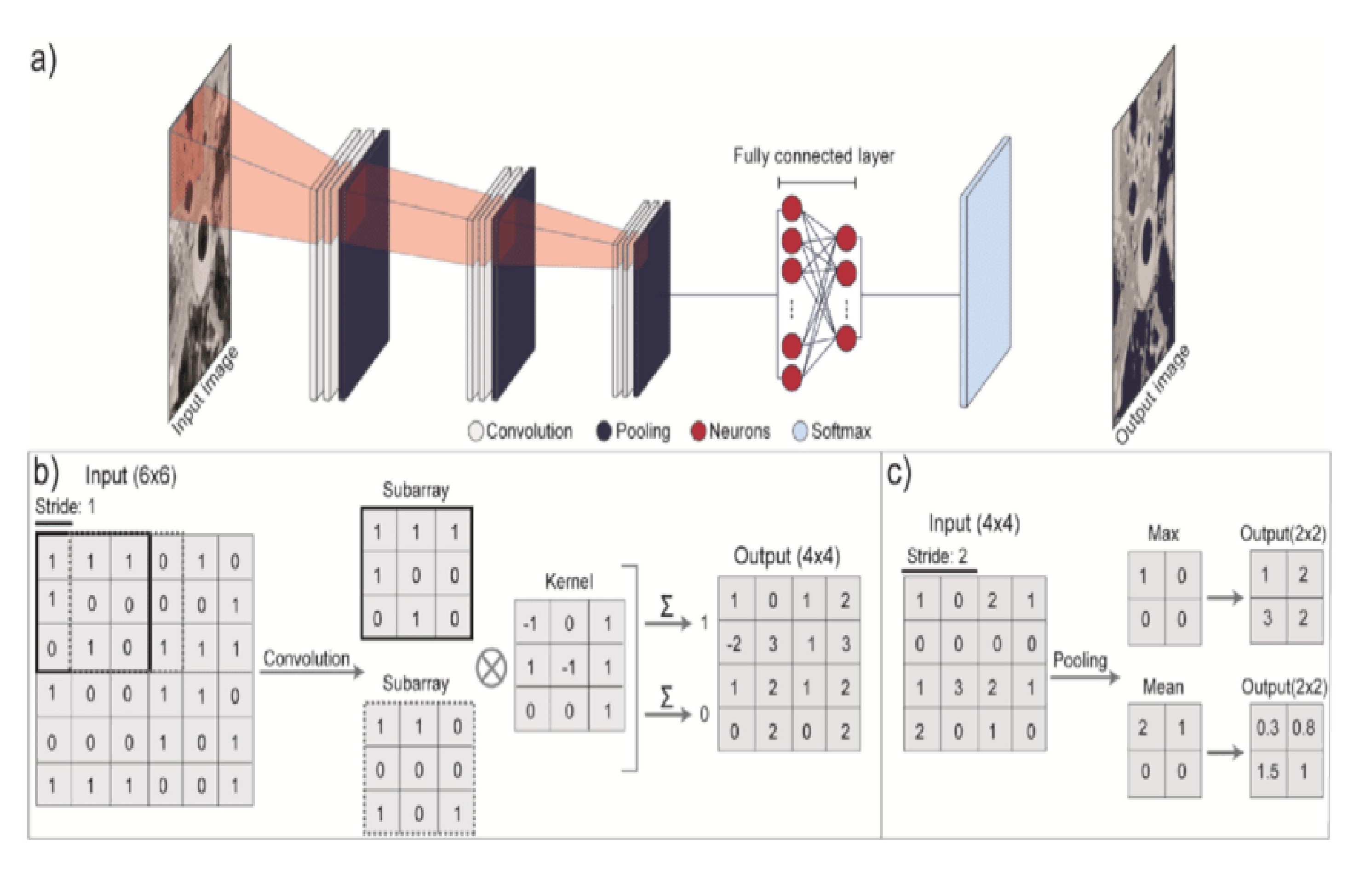
Deep Learning, and specifically Convolutional Neural Networks (CNNs), automate feature extraction by learning hierarchical representations directly from raw image data. Traditional image processing required manual definition of features like edges, corners, or textures; CNNs bypass this step. They achieve this through convolutional layers that apply filters to the input image, detecting local patterns. These patterns are then combined in subsequent layers to identify more complex features. The network learns the optimal filter weights during training, effectively discovering the most relevant features for a given task without explicit programming. This automated feature extraction significantly reduces the need for human intervention and allows the network to adapt to a wider range of image variations and complexities.
Convolutional Neural Networks (CNNs) process images through a series of interconnected layers. The Convolution Operation utilizes filters, or kernels, to scan the input image, extracting features like edges and textures by performing element-wise multiplication and summation. These feature maps are then downsampled by the Pooling Layer, reducing dimensionality and computational complexity while retaining important features. Finally, the Fully Connected Layer takes the output of the convolutional and pooling layers and applies weights to identify patterns and classify the image; multiple fully connected layers can be used to refine the classification process. This sequential processing allows CNNs to automatically learn hierarchical representations of visual data.
Training Convolutional Neural Networks (CNNs) utilizes iterative optimization algorithms, primarily backpropagation and gradient descent, to minimize the difference between predicted outputs and known correct values within a labeled dataset. Backpropagation computes the gradient of the loss function with respect to each network weight, indicating the direction and magnitude of adjustment needed. Gradient descent then updates these weights proportionally to the negative of this gradient, moving the network towards a state of lower error. This process is repeated across the entire dataset, often in multiple epochs, with the goal of converging on a set of weights that yield accurate predictions on unseen data. The size and quality of the labeled dataset are critical factors influencing the network’s performance and generalization capability; larger, more diverse datasets generally lead to more robust and accurate models.
Architectures for Real-Time Vision: A Comparative Landscape
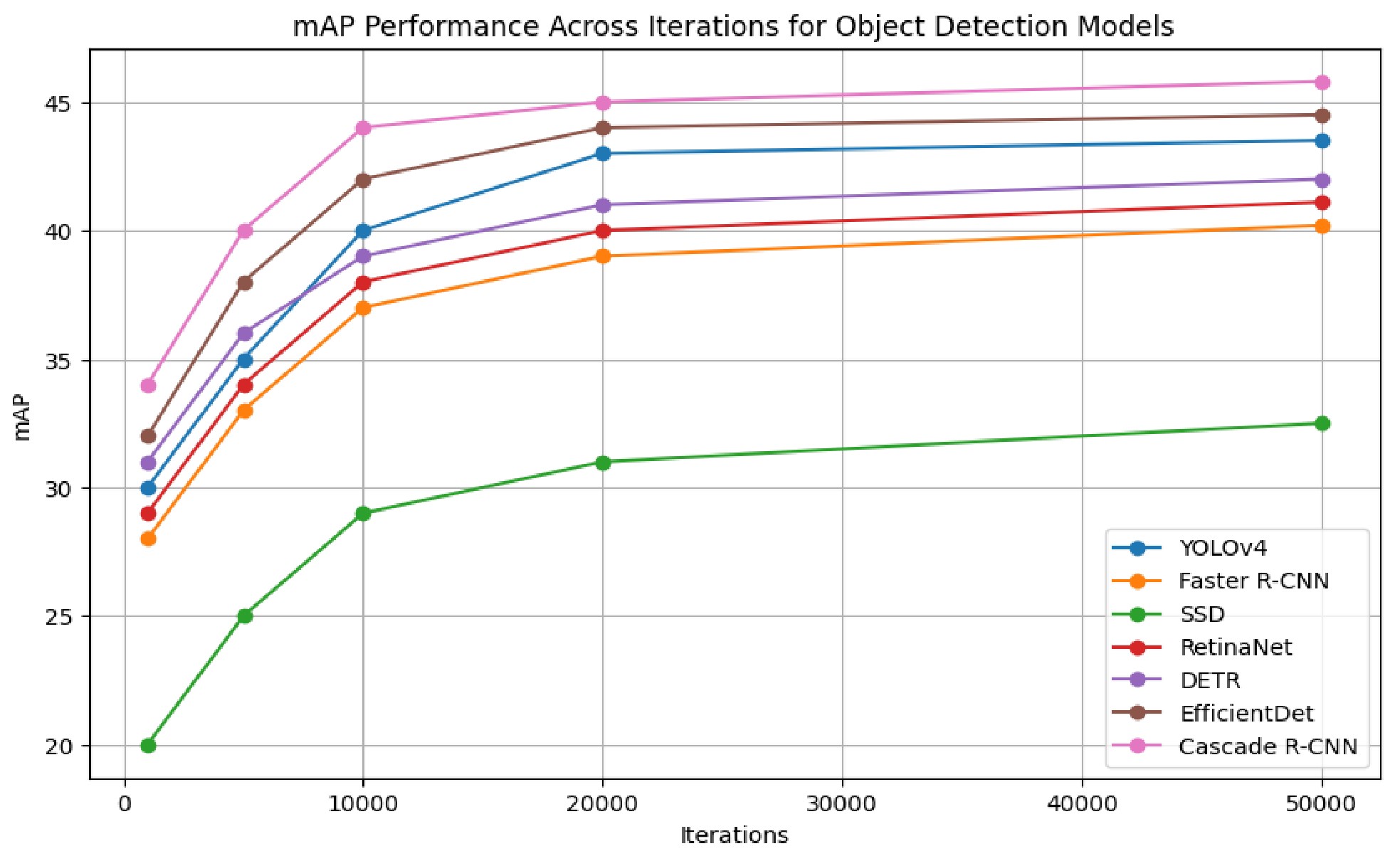
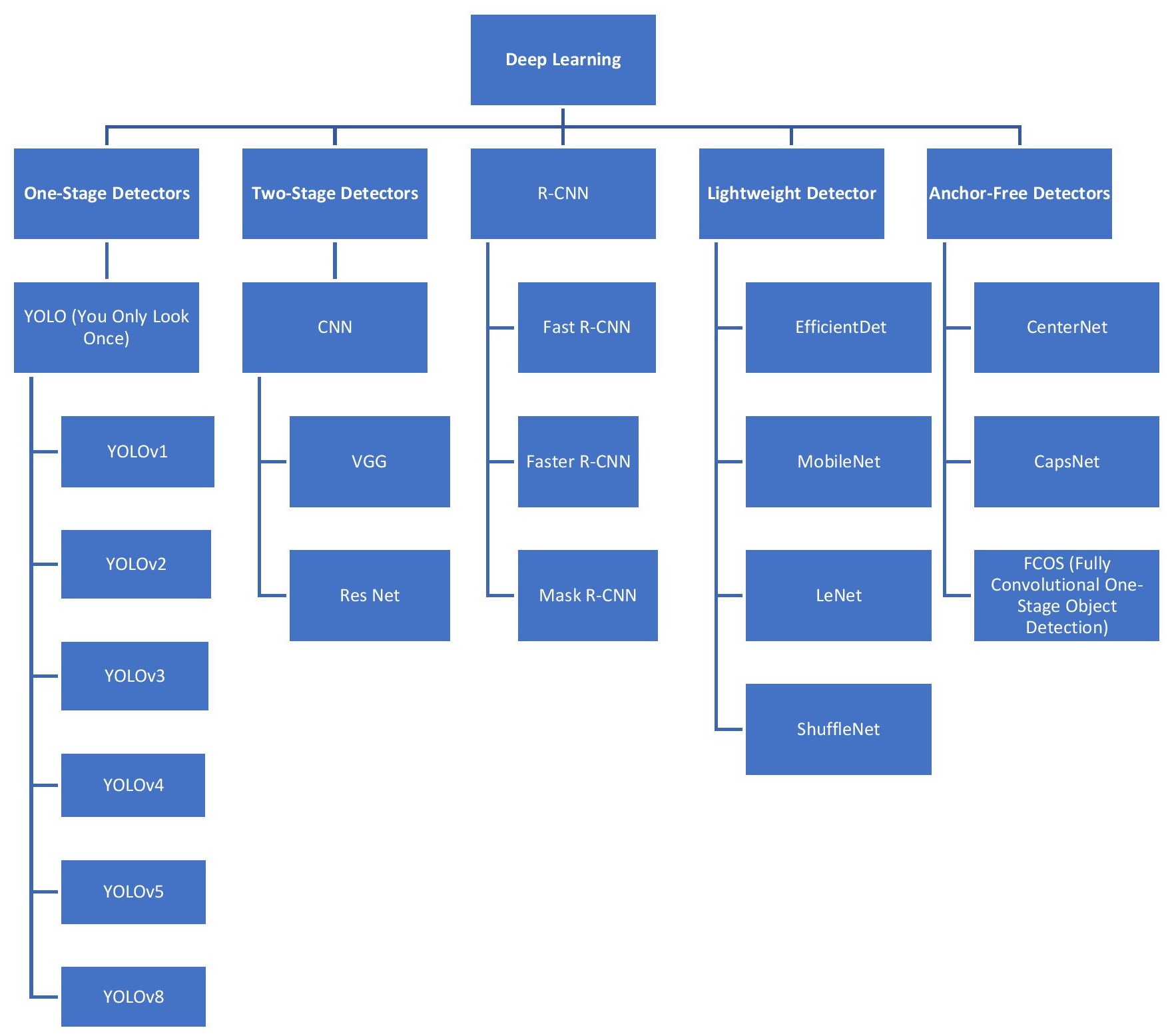
Both YOLO (You Only Look Once) and Single Shot Detector (SSD) achieve real-time object detection by formulating the detection process as a regression problem. This unified approach differs from methods like Faster R-CNN which involve a two-stage process of region proposal followed by classification. By directly predicting bounding box coordinates and class probabilities from the entire image in a single pass, these architectures significantly reduce computational complexity. This enables processing speeds necessary for real-time applications such as autonomous vehicles, video surveillance, and robotics, typically exceeding 30 frames per second on commodity hardware. The trade-off is often a slight decrease in average precision compared to two-stage detectors, but the speed advantage is prioritized for practical deployment in time-critical scenarios.
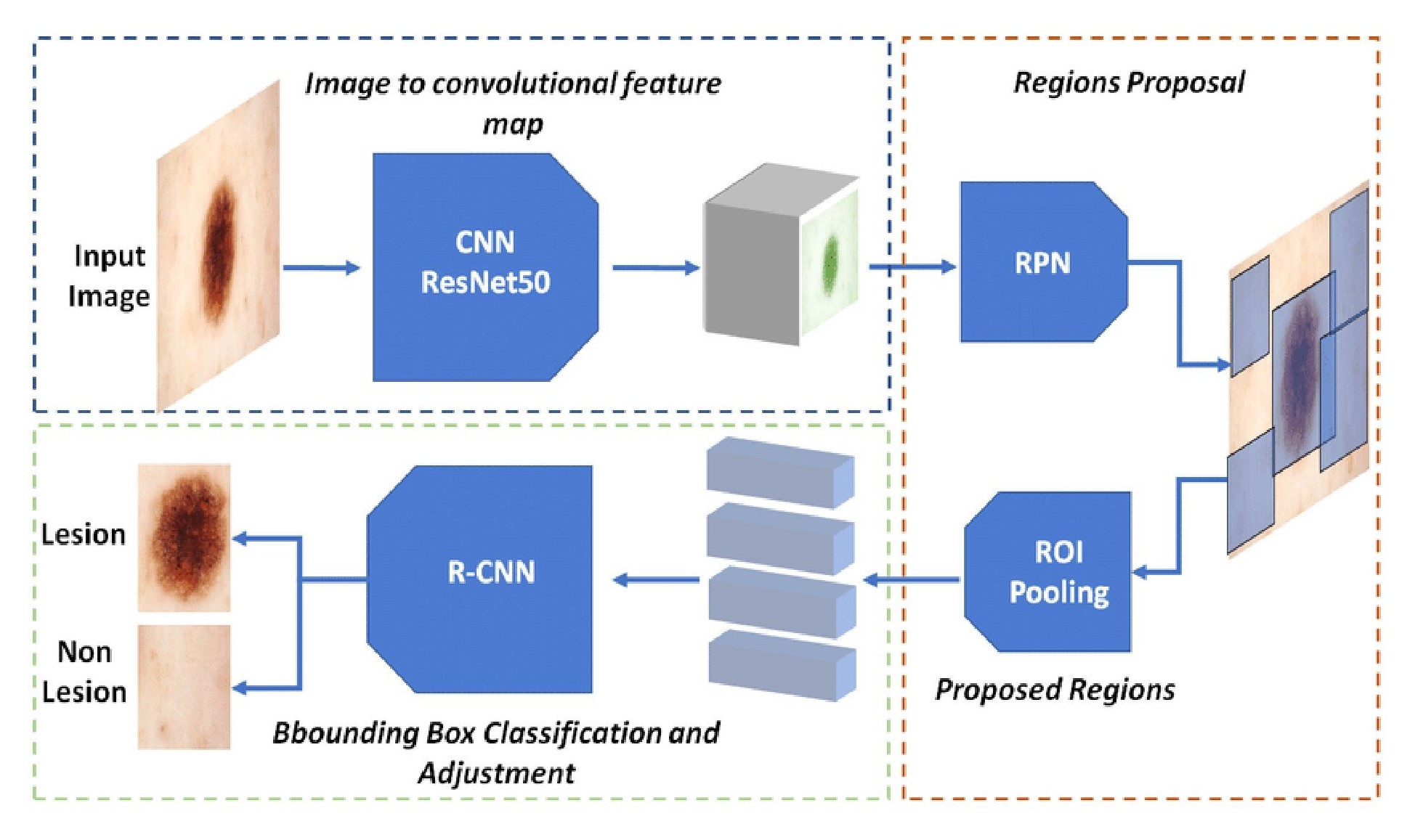
Faster R-CNN achieves improved object detection accuracy through the incorporation of a Region Proposal Network (RPN). The RPN operates as a fully convolutional network that simultaneously predicts object boundaries and objectness scores across a given input image. Rather than relying on computationally expensive, hand-engineered features or selective search algorithms to propose regions of interest, the RPN learns to directly generate these proposals, significantly reducing processing time and improving the quality of suggested regions. These proposals are then classified and refined by the subsequent stages of the Faster R-CNN pipeline, leading to more accurate object localization and classification results.
Feature Pyramid Networks (FPNs) address the challenge of detecting objects at varying scales within an image by constructing a multi-scale feature hierarchy. Traditional convolutional neural networks often struggle with smaller objects due to the loss of spatial resolution as data progresses through deeper layers. FPNs mitigate this by combining low-resolution, semantically strong features with high-resolution, semantically weak features through a top-down pathway and lateral connections. This creates a feature pyramid where each level is responsible for detecting objects of a specific scale, effectively improving performance on small object detection without significantly increasing computational cost. The resulting pyramid allows the network to leverage both strong semantic features from deeper layers and precise localization information from shallower layers across all scales.
Non-Maximum Suppression (NMS) is a post-processing technique utilized in object detection to refine bounding box predictions. Due to the overlapping nature of detected objects and the potential for multiple predictions for a single instance, NMS identifies and eliminates redundant bounding boxes. The algorithm operates by selecting the bounding box with the highest confidence score and iteratively suppressing all other boxes that exhibit a significant overlap – typically measured by Intersection over Union (IoU) exceeding a predefined threshold (e.g., 0.5). This process ensures that only the most accurate and representative bounding box remains for each detected object, improving the overall precision of the object detection system and reducing false positives.
Quantifying Perception: Metrics and Validation
Intersection over Union (IoU) is calculated as the area of overlap between a predicted bounding box and its corresponding ground truth box, divided by the area of their union. IoU = \frac{Area_{overlap}}{Area_{union}} The resulting value ranges from 0 to 1, where 0 indicates no overlap and 1 signifies a perfect match. A higher IoU score indicates greater accuracy in the bounding box prediction; a threshold is typically set (e.g., 0.5) to determine whether a detection is considered a true positive. IoU is a foundational metric used in evaluating object detection models and is crucial for assessing the precision of localization.
Mean Average Precision (mAP) is a widely used metric for evaluating object detection models, providing a single value representing performance across multiple object classes. It is calculated by determining the Average Precision (AP) for each class – based on the precision-recall curve – and then averaging these AP values. Crucially, mAP calculations incorporate an Intersection over Union (IoU) threshold; a prediction is considered correct only if its IoU with a ground truth box exceeds this threshold, typically ranging from 0.5 to 0.95. Variations in mAP scores between state-of-the-art models often result from differences in dataset composition, training procedures, and the specific IoU thresholds used during evaluation; reporting the IoU threshold alongside the mAP value is therefore essential for meaningful comparison. mAP = \frac{\sum_{i=1}^{N} AP_i}{N} , where N is the number of classes and AP_i is the Average Precision for class i.
Comprehensive evaluation of object detection models necessitates testing against diverse datasets reflecting a wide range of conditions, viewpoints, and object instances. This practice is crucial for assessing a model’s ability to generalize beyond the training data and maintain performance in real-world scenarios. Utilizing datasets with varied demographics, lighting conditions, and occlusions helps identify potential biases-such as disproportionate performance across different object categories or underrepresented groups-and limitations in the model’s robustness. Failure to evaluate on diverse datasets can lead to overly optimistic performance estimates and deployment of models that fail in unforeseen circumstances, highlighting the importance of rigorous, representative testing protocols.
Towards Truly Intelligent Vision: The Future of Object Detection
Current advancements in object detection increasingly prioritize computational efficiency, driven by the demand to deploy these technologies on devices with limited processing power and energy – think smartphones, drones, and embedded systems. Researchers are actively exploring techniques like network pruning, quantization, and knowledge distillation to reduce model size and complexity without significantly sacrificing accuracy. These methods streamline the architecture, decreasing the number of parameters and operations required for inference. Furthermore, the development of specialized hardware accelerators, designed specifically for deep learning tasks, complements these algorithmic improvements, offering substantial gains in speed and energy efficiency. This pursuit of lightweight models isn’t merely about shrinking file sizes; it’s about democratizing access to intelligent vision, enabling real-time object recognition in a wider range of applications and environments.
Current object detection systems, while remarkably proficient with pre-defined categories under stable conditions, frequently struggle when faced with real-world variability. A significant hurdle lies in their limited capacity to generalize to previously unseen environments – changes in lighting, occlusion, or viewpoint can dramatically reduce accuracy. Even more challenging is the detection of novel objects – items the system hasn’t been trained to recognize. Researchers are actively exploring techniques like meta-learning and few-shot learning to equip these systems with the ability to quickly adapt and learn new concepts from limited examples, mirroring the flexibility of human vision. Success in this area is crucial for deploying robust and reliable object detection in dynamic, unpredictable settings like autonomous driving and complex robotics applications, where encountering the unexpected is the norm rather than the exception.
The future of object detection extends beyond simply identifying what is present in an image or video; increasingly, the focus is on understanding the relationships between detected objects and interpreting their context. This is being achieved through a powerful synergy with natural language processing (NLP). By integrating object detection with NLP, systems can not only ‘see’ but also ‘understand’ a scene, enabling more sophisticated interactions. For example, robots guided by such integrated systems could respond to spoken commands like “pick up the red block next to the blue one,” demonstrating contextual awareness. Similarly, augmented reality applications could move beyond overlaying simple labels to providing detailed, conversational information about detected objects and their surroundings, creating truly intelligent and immersive experiences. This convergence promises to unlock new levels of automation, assistance, and engagement across diverse fields, from manufacturing and logistics to healthcare and education.
The pursuit of efficient object detection, as detailed in the study, demands a relentless focus on streamlining complexity. Beauty scales-clutter doesn’t. This principle resonates deeply with Fei-Fei Li’s observation: “AI is not about replacing humans; it’s about augmenting human capabilities.” The research showcases how advancements in model architectures – particularly transformer networks – aim to refine feature extraction and minimize computational overhead. This isn’t merely about achieving faster processing; it’s about creating systems that seamlessly integrate with human perception and enhance, rather than overwhelm, our cognitive abilities. The core idea of optimizing for both accuracy and speed embodies an elegance born from deep understanding.
Where to Next?
The pursuit of real-time object detection, as this work elucidates, has yielded impressive gains. Yet, a certain restlessness persists. The architectures, while increasingly sophisticated, often feel like elaborate solutions to problems of their own making – a proliferation of parameters addressing diminishing returns. The elegance isn’t always apparent; it is frequently obscured by computational cost. A truly insightful advance will not simply detect more objects, faster, but will fundamentally alter how these systems understand the visual world.
Future efforts must move beyond brute-force feature extraction. The current reliance on ever-larger datasets, while producing incremental improvements, feels unsustainable. The field needs to grapple with the problem of generalization – creating systems that perform reliably not just on curated benchmarks, but in the messy, unpredictable reality of everyday life. This demands a shift towards models that prioritize efficiency, robustness, and, crucially, interpretability.
Perhaps the most pressing challenge lies in bridging the gap between perception and cognition. Real-time object detection is, after all, merely a prelude to more complex tasks. The ultimate goal isn’t simply to identify what is present in an image, but to understand why it is there, and what it means. Only then will these systems truly begin to see.
Original article: https://arxiv.org/pdf/2602.15926.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Top 20 Dinosaur Movies, Ranked
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Gold Rate Forecast
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-02-19 19:05