Author: Denis Avetisyan
Researchers have developed a novel deep learning framework to improve the resolution of 4D Flow MRI data, even when data characteristics differ between training and real-world scans.
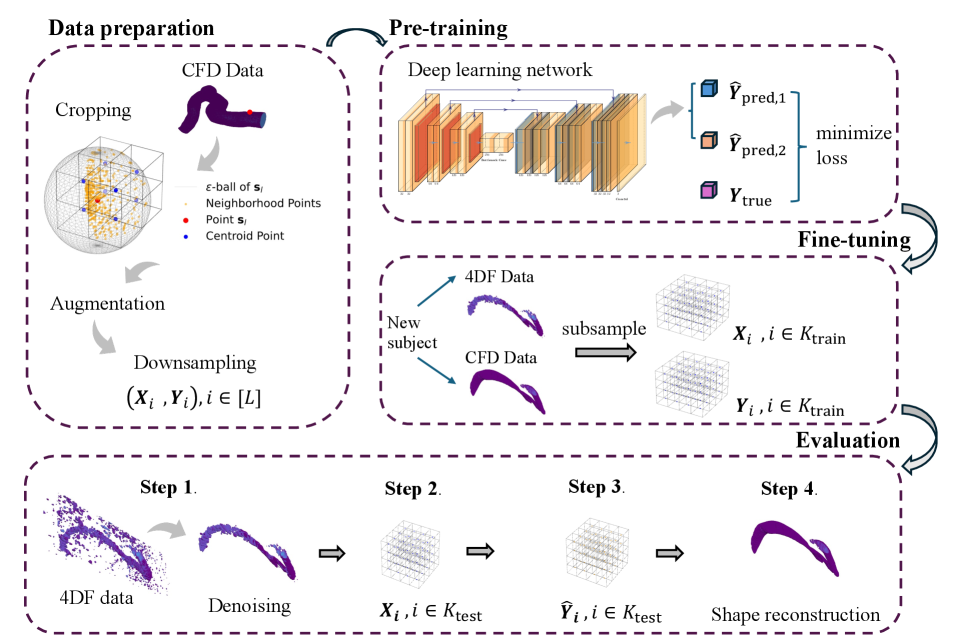
This work introduces a distributional super-resolution method that effectively addresses domain shift in 4D Flow MRI reconstruction using deep learning techniques.
Conventional super-resolution techniques struggle when applied to real-world medical imaging due to discrepancies between training data and clinical acquisition protocols. This limitation is addressed in ‘Distributional Deep Learning for Super-Resolution of 4D Flow MRI under Domain Shift’, which introduces a novel framework to enhance the resolution of 4D Flow MRI by explicitly modeling data distributions. Our approach, trained initially on computational fluid dynamics simulations and refined with limited paired MRI data, demonstrably outperforms traditional deep learning methods in resolving domain shift. Could this distributional learning strategy unlock improved image reconstruction across diverse and clinically relevant 4D Flow MRI applications, ultimately enhancing diagnostic accuracy and personalized hemodynamic assessments?
The Inherent Challenge: Resolution Limits in 4D Flow MRI
Conventional four-dimensional flow magnetic resonance imaging (4D Flow MRI) faces an inherent challenge in balancing image detail with practical scan durations. Achieving high resolution – the ability to discern fine structures and subtle flow patterns – necessitates acquiring a significantly larger volume of data, directly increasing the time a patient spends in the scanner. This trade-off presents a considerable hurdle, as excessively long scan times can lead to motion artifacts, patient discomfort, and reduced clinical throughput. Consequently, many studies compromise on resolution to maintain feasible scan times, potentially obscuring critical hemodynamic information needed for accurate diagnosis and treatment planning of cardiovascular diseases. The pursuit of faster acquisition methods, or more efficient data processing techniques, remains a central focus in advancing the clinical utility of 4D Flow MRI.
The challenge in visualizing blood flow with 4D Flow MRI isn’t simply about image clarity; it’s fundamentally linked to data acquisition. Capturing the intricate, three-dimensional nature of blood movement-especially in regions with turbulent or highly variable flow-requires an immense volume of data. Often, practical constraints like patient comfort and scan time necessitate a compromise, resulting in incomplete datasets. This insufficiency manifests as blurred visualizations, where fine details of flow patterns are lost and complex hemodynamics are misrepresented. Consequently, quantitative analysis becomes unreliable, potentially leading to misdiagnosis or suboptimal treatment planning, as subtle but critical flow features – indicators of disease progression or successful intervention – remain obscured.
The inability to fully resolve complex blood flow patterns with conventional 4D Flow MRI significantly impacts the precision of hemodynamic assessments, which are vital for both understanding and treating cardiovascular disease. Detailed evaluation of blood flow parameters – such as wall shear stress, turbulence, and flow stagnation – is crucial for identifying regions prone to atherosclerosis, aneurysmal formation, or thrombus development. Furthermore, accurate hemodynamic modeling informs the planning of complex interventions like stent placement or valve repair, allowing clinicians to optimize device selection and predict post-procedural outcomes. Without sufficient resolution, these critical analyses become compromised, potentially leading to misdiagnosis, suboptimal treatment strategies, and ultimately, poorer patient outcomes. Therefore, overcoming these limitations represents a major focus in the advancement of cardiovascular imaging and personalized medicine.
Super-Resolution: A Logical Path to Enhanced Detail
Super-resolution techniques address the challenge of recovering high-resolution (HR) imagery from low-resolution (LR) inputs, a process fundamentally limited by information loss during downsampling or initial capture. These methods do not create new information, but rather statistically infer plausible HR details based on patterns learned from training data. The core principle involves mapping LR input features to corresponding HR outputs, effectively increasing pixel density and enhancing perceived detail. Applications span diverse fields including medical imaging, satellite imagery analysis, and video enhancement, where obtaining native HR data is impractical or cost-prohibitive. Performance is typically evaluated using metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), quantifying the fidelity of the reconstructed HR image compared to a ground truth HR reference.
Convolutional neural networks (CNNs) are increasingly utilized for super-resolution tasks due to their ability to learn hierarchical representations of image data. Architectures like U-Net and its 3D variant are particularly effective; U-Net employs an encoder-decoder structure with skip connections to preserve fine-grained details during upscaling, while 3D U-Net extends this capability to volumetric data. These networks are trained on paired low- and high-resolution images, learning to map low-resolution features to their high-resolution counterparts. The learned filters within the CNNs effectively capture complex relationships, enabling the reconstruction of high-frequency details that are lost in the downscaling process. Performance is often evaluated using metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), demonstrating quantifiable improvements over traditional interpolation-based methods.
Deep learning-based super-resolution techniques leverage convolutional neural networks to establish a non-linear mapping function between low-resolution (LR) input images and their corresponding high-resolution (HR) counterparts. This learning process involves training the network on paired LR/HR datasets, enabling it to predict high-frequency details absent in the low-resolution input. The network learns to identify and replicate complex patterns and textures present in the HR training data, effectively upscaling the LR image while minimizing artifacts and maximizing perceptual quality. This learned mapping allows for the reconstruction of fine details and textures, resulting in a significant enhancement of image clarity and detail beyond what traditional interpolation methods can achieve.
Mitigating Domain Shift: Ensuring Robust Generalization
Domain shift presents a significant obstacle when deploying deep learning models in medical imaging because discrepancies often exist between the data used for training and the data encountered in clinical practice. These discrepancies can manifest as differences in image acquisition protocols, patient populations, scanner manufacturers, or image resolutions. Consequently, a model trained on one dataset may exhibit reduced performance when applied to data from a different distribution, limiting its generalizability and clinical utility. Addressing this requires techniques to improve model robustness to variations in input data, ensuring reliable performance across diverse clinical settings.
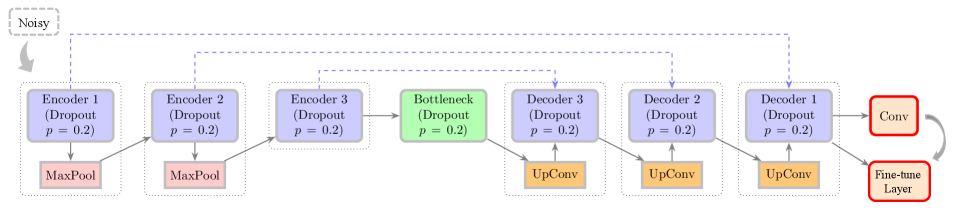
Distributional Deep Learning (DDL) offers a formalized approach to mitigating the effects of domain shift in deep learning models. Unlike traditional methods that assume training and testing data are identically distributed, DDL explicitly models the distribution of input data and accounts for variations between datasets. This is achieved by representing data as probability distributions rather than single points, allowing the model to learn features that are invariant to these distributional differences. By incorporating distributional information into the learning process, DDL enhances model robustness and improves generalization performance when applied to new, unseen data originating from different distributions, ultimately leading to increased accuracy and reliability in applications like medical imaging where data acquisition protocols can vary significantly.
Data augmentation and the incorporation of pre-additive noise models are utilized to improve the generalization capability of deep learning models in medical imaging. Data augmentation increases the effective size and diversity of the training dataset by applying transformations to existing data, thereby exposing the model to a wider range of potential inputs. Pre-additive noise models introduce realistic noise patterns during training, simulating the variations commonly found in clinical data. Both techniques mitigate overfitting by reducing the model’s reliance on specific features present in the training set, and enhancing its ability to perform accurately on unseen, real-world data. This approach promotes robustness to variations in image acquisition parameters, patient anatomy, and other factors contributing to domain shift.
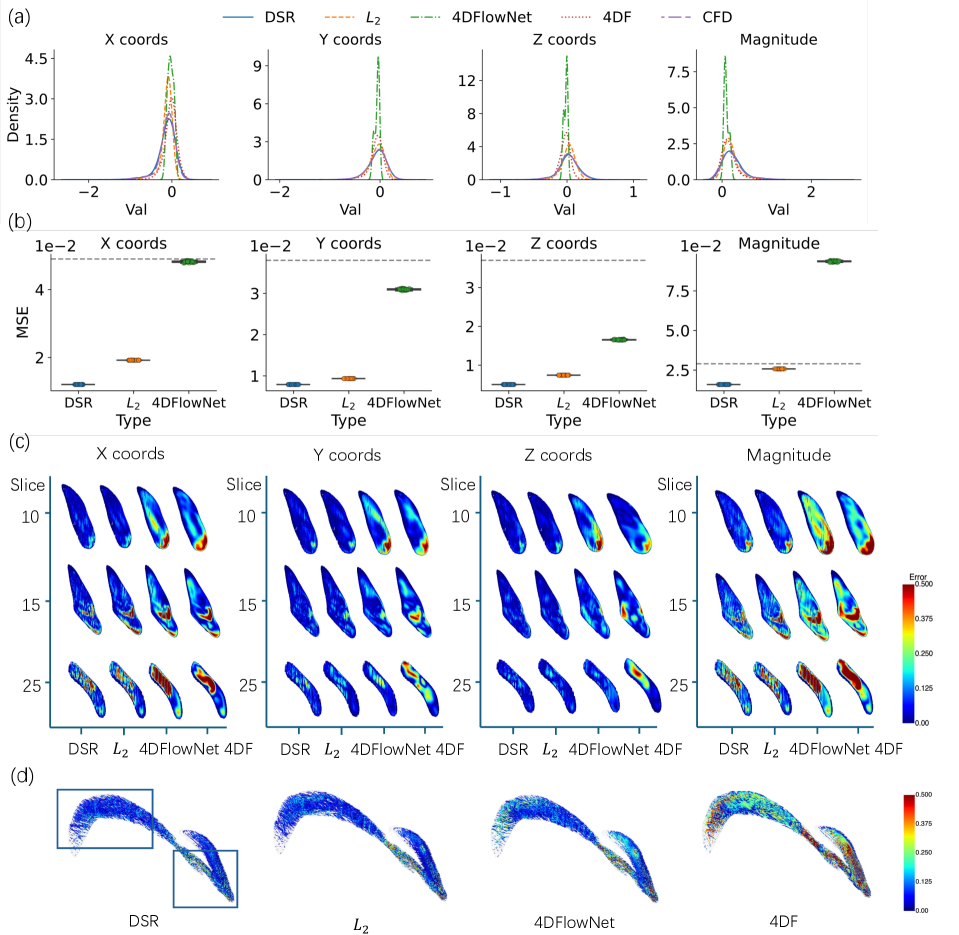
The Distributional Super-Resolution (DSR) framework exhibits enhanced performance in 4D flow (4DF) data super-resolution, as quantified by the Mean Squared Error (MSE). Comparative analysis demonstrates that DSR achieves a lower MSE than both L2L regression and the 4DFlowNet method. This reduction in MSE indicates improved accuracy in reconstructing high-resolution 4DF data from lower-resolution inputs, suggesting the framework’s effectiveness in mitigating data limitations common in medical imaging applications. The quantitative results provide evidence for DSR’s superior performance in this specific task.
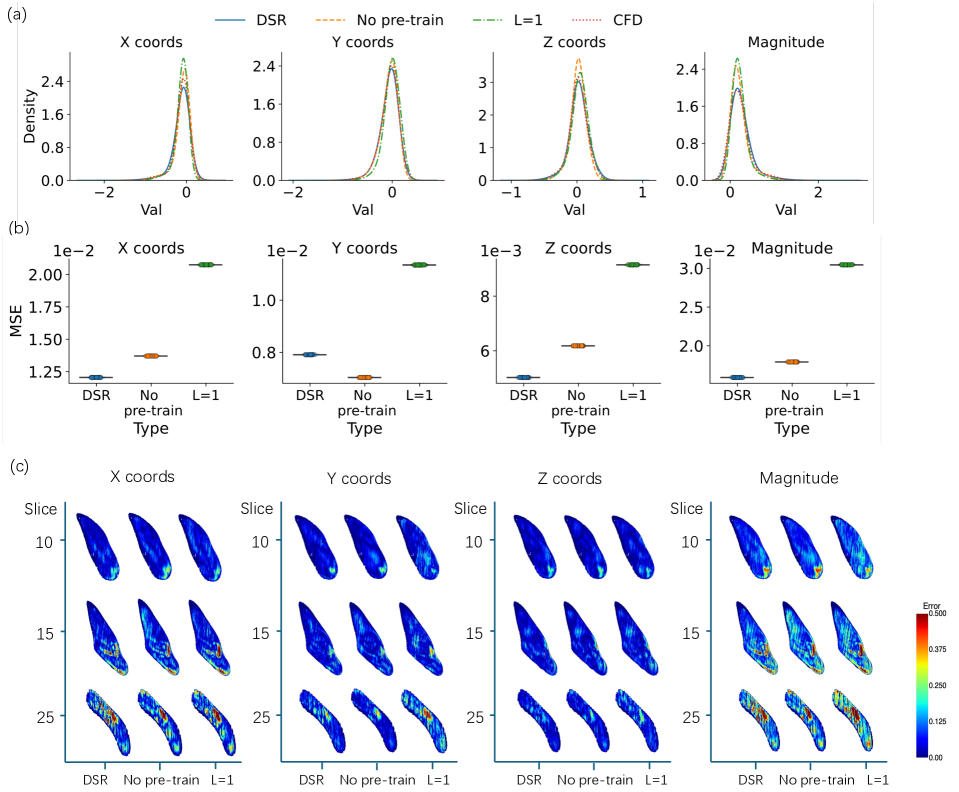
Evaluation results indicate that pre-training the model consistently reduces the Mean Squared Error (MSE), confirming the advantages of utilizing informed initialization strategies. Specifically, models initialized with pre-trained weights exhibited lower MSE values compared to those trained from random initialization. Furthermore, the implementation of multi-stage data augmentation, parameterized by level L, demonstrated a positive correlation between augmentation complexity and performance; a four-stage augmentation process (L=4) yielded a measurable reduction in MSE compared to a single-stage augmentation (L=1). This suggests that increasing data diversity through sequential augmentation techniques contributes to improved model generalization and reduced error rates.
Clinical Translation: Mapping Hemodynamic Risk with Precision
Recent advancements in medical imaging have yielded unprecedented detail in the visualization of blood flow within the brain. High-resolution 4D Flow Magnetic Resonance Imaging, particularly when coupled with super-resolution techniques, now allows clinicians to observe the intricate patterns of blood movement with remarkable clarity. This technology goes beyond simply showing where blood flows; it reveals the subtle complexities of how it flows, capturing swirling vortices, regions of acceleration, and areas of stagnation. By constructing detailed, three-dimensional maps of blood velocity and direction, researchers can analyze the forces exerted on vessel walls – information previously inaccessible through conventional imaging. This detailed hemodynamic mapping is proving invaluable in understanding the origins of vascular disease and assessing the risk associated with conditions like cerebral aneurysms, ultimately paving the way for more precise and personalized interventions.
The propensity for cerebral aneurysms to form and subsequently rupture is intimately linked to the mechanical forces exerted by blood flow on the vessel wall, specifically Wall Shear Stress (WSS). Traditionally, assessing WSS with sufficient accuracy has proven challenging, but advances in medical imaging now offer a more detailed picture. High-resolution 4D Flow MRI, coupled with super-resolution techniques, allows clinicians to visualize and quantify WSS distributions with unprecedented precision. Regions of low or oscillating WSS are now understood to promote endothelial dysfunction, weakening the vessel wall and fostering aneurysm growth. Conversely, areas of high WSS can also contribute to rupture risk. By accurately mapping these stress patterns, researchers and clinicians gain a crucial understanding of aneurysm vulnerability, potentially identifying those at highest risk of catastrophic bleed and paving the way for more targeted interventions.
The stability of a cerebral aneurysm – a potentially life-threatening bulge in a blood vessel – is significantly linked to the patterns of blood flow within and around it. Researchers are now leveraging detailed flow visualizations, obtained through advanced MRI techniques, to calculate metrics like the Shear Concentration Index (SCI). This index doesn’t simply measure the average force of blood flow on the aneurysm wall, but rather quantifies the localized areas of high stress created by swirling or rapidly changing flow. A high SCI suggests that certain spots on the aneurysm wall are experiencing disproportionately large and potentially damaging forces, indicating a greater risk of rupture. Consequently, the SCI serves as a crucial tool for risk stratification, enabling clinicians to identify aneurysms that require more aggressive monitoring or intervention, and ultimately, to personalize treatment plans based on a patient’s individual hemodynamic profile.
The refinement of hemodynamic risk assessment, driven by advanced 4D Flow MRI and metrics like the Shear Concentration Index, promises a paradigm shift toward individualized care for patients with cerebral aneurysms. Currently, treatment decisions often rely on generalized risk factors; however, a detailed understanding of blood flow dynamics within each aneurysm allows clinicians to move beyond these broad categorizations. This precision enables the tailoring of interventions – be it conservative monitoring, endovascular coiling, or surgical clipping – to the specific vulnerability profile of the aneurysm itself. Consequently, patients benefit from strategies optimized for their unique anatomy and physiology, potentially minimizing unnecessary procedures and maximizing long-term stability, ultimately leading to improved outcomes and a higher quality of life.
The pursuit of enhanced resolution in 4D Flow MRI, as detailed in this work, necessitates a rigorous approach to both algorithm design and validation. It’s not merely about achieving visually appealing results, but ensuring mathematical consistency across varying data domains. As Yann LeCun aptly stated, “The ability to learn is limited by the quality of the representation.” This rings true in the context of distributional super-resolution; the framework’s success hinges on effectively representing the underlying fluid dynamics and adapting to domain shifts. The DSR framework doesn’t just work on test cases, it aims to establish a provable method for reliable image reconstruction even when faced with discrepancies between training and testing data, thereby upholding a commitment to algorithmic purity.
What’s Next?
The pursuit of super-resolution, even when framed within the rigorous context of distributional learning, ultimately reveals the inherent instability of inverse problems. This work, while demonstrating a measurable advance in 4D Flow MRI reconstruction, does not eliminate the fundamental challenge: inferring high-frequency detail from incomplete or noisy observations. The demonstrated gains, achieved by mitigating domain shift, merely postpone the inevitable confrontation with the limitations of any data-driven model. A future direction must move beyond empirical improvements and focus on provable bounds on reconstruction error, incorporating principles from harmonic analysis and information theory.
Current methodologies rely heavily on the assumption that the training distribution adequately represents the unseen test data. This is, of course, a fragile assumption in medical imaging, where patient populations are inherently diverse. A more robust approach would involve algorithms capable of detecting distributional discrepancies and adapting their reconstruction strategies accordingly-a form of meta-learning applied to the very process of inference. The computational fluid dynamics models used for validation, while valuable, remain approximations of reality; true progress demands a tighter integration of physical modeling and data assimilation.
In the chaos of data, only mathematical discipline endures. The field must resist the temptation to simply accumulate empirical successes and instead prioritize the development of algorithms grounded in a deep understanding of the underlying signal properties and the inherent limitations of observation. Only then can it move beyond the illusion of ‘resolution’ and approach a truly faithful reconstruction of the underlying physiological reality.
Original article: https://arxiv.org/pdf/2602.15167.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Wuchang Fallen Feathers Save File Location on PC
- Gold Rate Forecast
- Brown Dust 2 Mirror Wars (PvP) Tier List – July 2025
- HSR 3.7 breaks Hidden Passages, so here’s a workaround
- Crypto Chaos: Is Your Portfolio Doomed? 😱
- Is Taylor Swift Getting Married to Travis Kelce in Rhode Island on June 13, 2026? Here’s What We Know
- The Best Single-Player Games Released in 2025
- 17 Black Actresses Who Forced Studios to Rewrite “Sassy Best Friend” Lines
- Brent Oil Forecast
2026-02-19 00:26