Author: Denis Avetisyan
A novel reinforcement learning framework directly optimizes advertising text for both conversion rates and quality, promising a significant lift in campaign performance.
This paper introduces RELATE, a system achieving a 9.19% increase in Click-Through Conversion Value Rate (CTCVR) in a live production environment through reward-shaped reinforcement learning.
Optimizing advertising text for both user engagement and advertiser value remains a challenge due to the typical decoupling of text generation and performance alignment. To address this, we introduce ‘RELATE: A Reinforcement Learning-Enhanced LLM Framework for Advertising Text Generation’, a novel reinforcement learning framework that unifies these processes within a single, end-to-end model. RELATE directly optimizes for conversion-oriented metrics alongside compliance constraints, achieving a 9.19\% increase in click-to-conversion rate in a production environment. Can this approach of directly integrating downstream objectives into text generation unlock further gains in advertising effectiveness and broader applications in content creation?
The Imperative of Nuance in Advertising Text
The foundation of successful online marketing rests upon the ability to craft advertising text that resonates with individual consumers, yet conventional approaches frequently fall short of this goal. Historically, advertising copy has relied on broad generalizations and standardized messaging, failing to acknowledge the diverse preferences and motivations driving online behavior. This lack of nuance diminishes engagement, as advertisements struggle to capture attention amidst a crowded digital landscape. Consequently, businesses are increasingly recognizing that truly effective advertising demands a shift towards hyper-personalization-content tailored not just to demographic segments, but to the unique characteristics and immediate needs of each potential customer-a feat proving challenging with existing techniques.
The assumption that larger language models automatically translate to superior advertising copy is increasingly challenged by observed performance. While scaling model size often improves general language capabilities, it frequently results in outputs that lack the specificity and originality needed to capture audience attention. This phenomenon stems from the tendency of these models to favor statistically common phrasing and broadly appealing, yet ultimately bland, language. Consequently, advertising text generated through simple scaling can become remarkably generic, failing to differentiate a product or service and ultimately diminishing its impact on key performance indicators. The pursuit of higher-quality advertising requires more than just computational power; it demands strategies that prioritize nuanced messaging and genuine personalization.
The performance of digital advertising, as measured by key indicators like Click-Through Rate (CTR) and Click-to-Conversion Rate (CTCVR), has reached a plateau, suggesting current strategies are failing to capture audience attention and drive meaningful action. This stagnation isn’t simply a matter of market saturation; it reveals a fundamental limitation in how advertising text is generated and deployed. While increased scale in content creation was once believed to be the answer, these metrics demonstrate that quantity does not equate to quality, and that a fresh approach to optimization is urgently needed. The potential for significant gains remains substantial; even incremental improvements in CTR and CTCVR can translate to considerable revenue increases, making the pursuit of innovative methods a critical endeavor for marketers seeking to maximize campaign effectiveness and return on investment.
RELAATE: A Reinforcement Learning Framework for Precision
RELAATE is a new framework designed to improve the performance of advertising text generation through the application of Reinforcement Learning (RL). Unlike traditional methods that rely on static datasets and pre-defined rules, RELAATE utilizes an RL agent to actively learn and optimize ad copy based on observed outcomes. This approach allows for the creation of more effective and engaging advertising content by iteratively refining text generation strategies. The framework’s core innovation lies in its ability to move beyond passive text creation and embrace an adaptive learning process focused on maximizing key performance indicators within a dynamic advertising landscape.
Relaate’s architecture centers on the integration of the Qwen3-8B Large Language Model (LLM) with the Generalized Reward-based Policy Optimization (GRPO) reinforcement learning algorithm. Qwen3-8B serves as the policy network, responsible for generating advertising text based on given prompts. GRPO is employed to optimize this policy by iteratively refining the text generation process based on reward signals. The LLM provides the capacity for complex language modeling, while GRPO enables learning from feedback and adapting the generated text to maximize specified performance indicators. This combination allows Relaate to move beyond static text generation and actively learn to produce more effective advertising copy.
Reward shaping within the RELAATE framework is a crucial technique used to accelerate learning and improve the quality of generated advertising text. This process involves defining intermediate reward signals that guide the reinforcement learning agent towards desired outcomes, specifically the maximization of key performance indicators (KPIs) such as click-through rate and conversion rate. Rather than solely relying on sparse rewards received after a complete interaction, reward shaping provides denser, more frequent feedback, allowing the agent to learn more efficiently. These intermediate rewards are carefully designed to reflect progress towards optimal text generation, for example, rewarding for grammatical correctness, relevance to the target audience, or the inclusion of compelling calls to action. By strategically constructing these reward signals, RELAATE can overcome the challenges of sparse reward environments and effectively optimize advertising content.
Relaate’s adaptive capability stems from its reinforcement learning loop, which continuously refines content generation based on observed performance metrics. The framework processes feedback – such as click-through rates, conversion data, and user engagement signals – to update its policy. This iterative process allows Relaate to dynamically adjust to shifts in market trends, evolving user preferences, and changes in advertising platform algorithms. Consequently, the system generates increasingly relevant and personalized advertising text, optimizing for improved campaign performance across diverse audience segments and ensuring sustained impact over time.
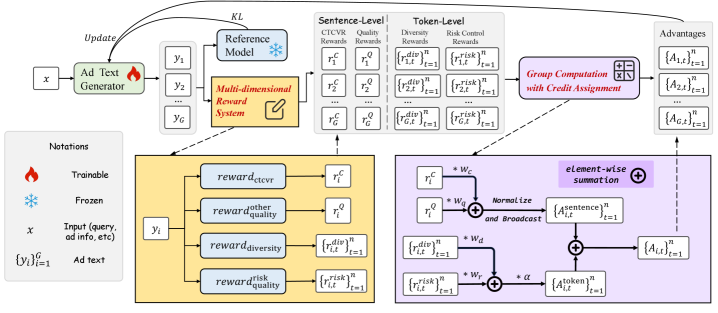
The Precision of Reward: Differentiating Effective Text
The RELAATE reward system incorporates a Diversity Reward component designed to mitigate repetitive text generation. This reward is calculated based on the novelty of generated tokens compared to previously generated sequences within the same batch. Specifically, the reward function penalizes the model for producing tokens that have a high probability of already being present in the current output distribution, thereby incentivizing the exploration of less common, more diverse linguistic options. This mechanism directly addresses the tendency of large language models to converge on predictable phrasing and reduces the likelihood of generating redundant or formulaic advertising copy.
Effective credit assignment within the RELAATE framework is achieved through a dual-level reward system. Token-Level Rewards assess the contribution of individual tokens to the overall quality of generated text, enabling the model to learn which specific words or phrases are most impactful. Complementing this, Sentence-Level Rewards evaluate the quality of entire sentences, providing a higher-level signal that encourages coherent and meaningful output. This combined approach allows for granular identification of both locally important tokens and globally significant sentence structures, improving the model’s ability to generate effective advertising copy by accurately attributing value to different elements of the text.
Contrastive learning enhances the model’s capacity to differentiate between high- and low-quality advertising copy by training it on paired examples. These pairs consist of a positive example – an effective advertisement – and a negative example, often a slightly modified or demonstrably ineffective version of the positive example. The model learns to maximize the similarity between its internal representation of the positive example and minimize the similarity with the negative example. This process establishes a more nuanced understanding of what constitutes effective advertising text, going beyond simple keyword matching or superficial stylistic features, and improving the model’s ability to generate compelling and persuasive content.
Direct Preference Optimization (DPO) is a policy gradient algorithm used to fine-tune large language models by directly optimizing for human preferences. Unlike reinforcement learning from human feedback (RLHF) which requires a separate reward model, DPO reframes the reward maximization problem as a supervised learning problem. This is achieved by utilizing a binary preference dataset – pairs of model outputs where a human has indicated which response is preferred. DPO then trains the language model to maximize the likelihood of the preferred response, effectively learning a policy that aligns with those preferences. The algorithm’s objective function directly correlates preference ratios to the difference in log probabilities of the preferred and dispreferred responses, simplifying the training process and improving sample efficiency compared to traditional RLHF methods.

Beyond Optimization: A Framework for Generative Precision
Rather than simply tweaking pre-existing advertising copy, RELAATE reimagines the process of text generation through a dynamic Generate-Evaluate-Refine framework. This system doesn’t settle for incremental improvements; it proactively creates novel text variations, then rigorously assesses their potential performance based on predicted user engagement. Crucially, the framework doesn’t stop at evaluation; it uses these insights to iteratively refine the generation process, continuously learning which linguistic features and messaging strategies yield the most compelling results. This cyclical approach moves beyond traditional optimization, enabling the creation of advertising text that more effectively resonates with target audiences and unlocks previously unattainable levels of campaign performance.
Relaate distinguishes itself through continuous learning and adaptation, resulting in measurable gains in advertising performance. The system doesn’t simply reach a peak and plateau; instead, it persistently refines its approach, driving sustained improvements in both Click-Through Rate (CTR) and, crucially, Click-to-Conversion Value Rate (CTCVR). Rigorous testing within a large-scale production advertising system has demonstrably confirmed this dynamic capability, revealing a significant 9.19% relative increase in CTCVR – a metric that directly reflects the revenue generated from each click – showcasing the framework’s ability to translate increased engagement into tangible economic benefits.
RELAATE achieves heightened advertising efficacy by synergistically integrating the expansive creative potential of Large Language Models with the focused optimization of Reinforcement Learning. This combination allows the system to move beyond simply mimicking successful ad copy; it proactively generates novel text variations, then rigorously evaluates their likely performance based on real-world data. The Reinforcement Learning component acts as a discerning filter, refining the generated content to prioritize messaging most likely to drive desired conversions. Consequently, RELAATE doesn’t just improve upon existing advertisements, but actively learns to craft uniquely tailored content that resonates with individual users, fostering a level of personalization previously unattainable in automated advertising systems and demonstrably increasing overall campaign value.
Relaate presents a solution designed not merely to address current advertising needs, but to evolve alongside shifting market dynamics and consumer behaviors. The framework’s architecture allows for seamless integration with existing advertising infrastructure, accommodating increasing volumes of data and expanding campaign complexities without significant performance degradation. Businesses can leverage this adaptability to test diverse creative strategies, personalize messaging at scale, and respond rapidly to emerging trends-all while consistently improving key performance indicators. This inherent scalability ensures that advertising investments remain effective, even as campaign objectives and target audiences change, offering a sustainable pathway to maximize return and maintain a competitive edge in the digital landscape.
The pursuit of optimization, as demonstrated by RELATE’s reinforcement learning framework, aligns with a fundamentally mathematical approach to problem-solving. The paper’s focus on maximizing both conversion rates and quality through reward shaping embodies a desire for provable improvement, not merely empirical gains. This resonates with Andrey Kolmogorov’s assertion: “The most important thing in science is not to be afraid of making mistakes, but to learn from them.” RELATE doesn’t simply generate advertising text; it iteratively refines its approach, learning from each interaction to approach an ideal solution, mirroring Kolmogorov’s emphasis on the iterative nature of discovery and the importance of quantifiable results-a principle crucial to the framework’s 9.19% increase in CTCVR.
Beyond the Conversion
The demonstrated gains in constrained text generation, specifically the 9.19% improvement in click-through conversion rate (CTCVR), are merely a symptom. The underlying problem remains: a reliance on empirical validation, rather than provable optimality. While reinforcement learning offers a path beyond static datasets, it still operates within the bounds of observed reward signals. A truly elegant solution would not seek to maximize a metric; it would guarantee a specific performance level, verifiable through mathematical deduction. The current framework, while practically effective, is ultimately a sophisticated curve-fitting exercise.
Future work must address the inherent limitations of reward shaping. The definition of ‘quality’ in advertising text, as currently operationalized, is subjective and prone to bias. A rigorous approach would involve formalizing aesthetic and persuasive principles into quantifiable constraints, thereby shifting the optimization problem from one of approximation to one of satisfaction. The exploration of formal methods, perhaps drawing inspiration from program verification techniques, offers a potential, if challenging, avenue for progress.
Furthermore, the notion of ‘diversity’ as a reward component requires deeper scrutiny. Simply maximizing the dissimilarity between generated texts does not necessarily equate to increased effectiveness. A more nuanced understanding of cognitive biases and user preferences is needed, ideally expressed as formal logical constraints. Until such rigor is achieved, the field will remain tethered to the frustrating reality that ‘it works’ is never sufficient.
Original article: https://arxiv.org/pdf/2602.11780.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- Gold Rate Forecast
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Top gainers and losers
- 10 Underrated Films by Wyatt Russell You Must See
- Best Video Games Based On Tabletop Games
- Top 20 Overlooked Gems from Well-Known Directors
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- Brent Oil Forecast
2026-02-15 13:50