Author: Denis Avetisyan
Researchers have discovered a key pattern in the gradients of large language models and developed a new optimizer designed to exploit this structure for faster, more efficient training.
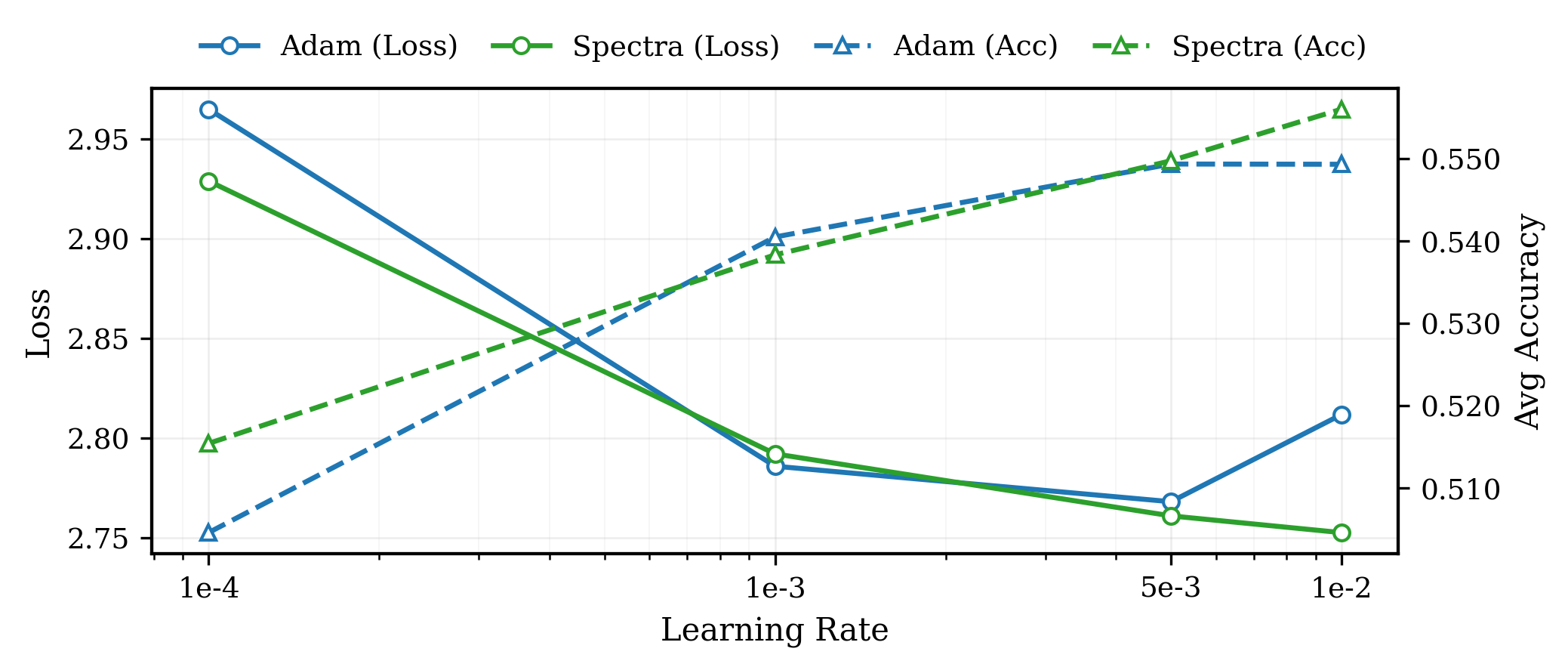
Spectra selectively attenuates dominant gradient spikes while mitigating the effects of spectral anisotropy, improving convergence and performance in large language models.
Despite advances in large language model training, optimizing convergence speed and performance remains a key challenge due to the highly anisotropic nature of gradient signals. This paper, ‘Spectra: Rethinking Optimizers for LLMs Under Spectral Anisotropy’, reveals a persistent separation between dominant low-rank “spike” and long-tail spectral components within LLM gradients, hindering efficient learning. We introduce Spectra, a novel optimizer that selectively attenuates the dominant spike while preserving the informative spectral tail, achieving faster convergence and improved downstream accuracy. Could this spike-aware approach unlock further gains in LLM training efficiency and generalization ability?
The Anisotropic Landscape of Learning
The remarkable capacity of Large Language Models to learn from data is accompanied by a peculiar characteristic of their training process: highly anisotropic gradient signals. Unlike the more intuitive scenario of updates distributed evenly across all parameter dimensions, LLM training often concentrates learning efforts in specific directions, creating an optimization landscape that is far from uniform. This anisotropy means that the gradients – the signals guiding parameter adjustments – are not isotropic, or equal in all directions, but instead exhibit a strong directional bias. Consequently, the model’s parameters are updated more vigorously along certain axes than others, leading to an uneven exploration of the vast parameter space and potentially hindering the capture of nuanced semantic variations that lie outside these dominant update directions. The implications of this skewed landscape extend to both the efficiency of training and the ultimate robustness of the resulting model.
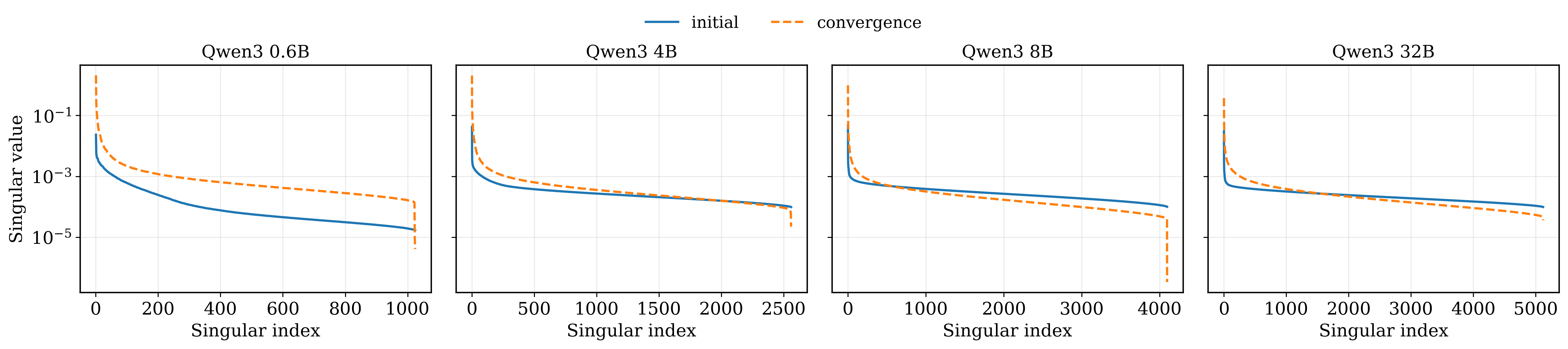
The optimization process within large language models isn’t uniform; instead, it exhibits a pronounced anisotropy reflected in the gradient spectrum. Analysis reveals a dominant ‘low-rank spike’ – a concentration of gradient updates along a surprisingly limited number of directions in the model’s vast parameter space. This means that while millions of parameters exist, the majority of learning signals are channeled into refining only a small subset of them. The implications are significant, as this skewed update distribution suggests that the model prioritizes certain semantic variations while potentially neglecting others, effectively creating a biased representation of the training data and hindering its ability to generalize effectively across diverse inputs. The phenomenon effectively limits the dimensionality of effective learning, despite the high-dimensional nature of the model itself.
The optimization of large language models often prioritizes updates along a few dominant directions, creating a skewed learning process. This phenomenon results from a concentrated ‘low-rank spike’ in the gradient spectrum, effectively overshadowing contributions from less frequent, but potentially crucial, semantic variations residing in the ‘tail spectrum’. Consequently, the model’s ability to generalize to nuanced or uncommon inputs may be hindered, as updates are disproportionately allocated to reinforcing already-strong connections rather than exploring the broader parameter space. This suppression of learning in the tail spectrum suggests that a significant portion of the model’s capacity for capturing linguistic diversity remains underutilized, prompting research into techniques that can redistribute optimization effort and improve generalization performance.
A thorough comprehension of the spectral bias inherent in large language model training opens avenues for crafting markedly improved optimization strategies. Current methods, while achieving impressive results, often prioritize updates along a dominant ‘low-rank’ direction, potentially neglecting the vast ‘tail spectrum’ encompassing nuanced semantic information. By acknowledging this uneven gradient landscape, researchers can develop techniques – such as targeted regularization or adaptive learning rates – designed to redistribute optimization effort. Such approaches could foster more efficient learning, enhance generalization capabilities, and ultimately yield large language models that are not only powerful but also more robust and adaptable to diverse linguistic patterns. Addressing this spectral bias represents a critical step toward unlocking the full potential of these increasingly prevalent artificial intelligence systems.
Unveiling the Mechanisms of Spectral Bias
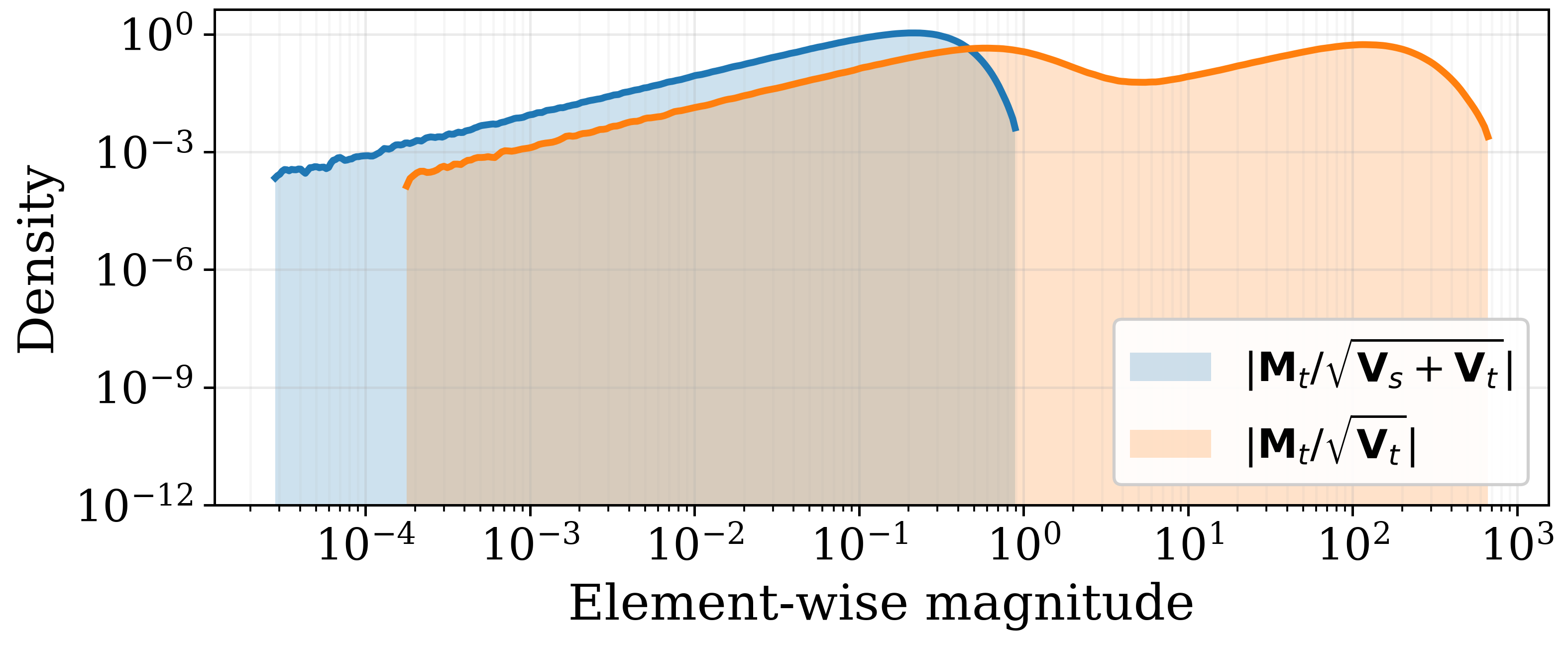
The AdamW optimizer, commonly used in deep learning, utilizes second-moment accumulation – specifically, estimates of the first and second moments of the gradients – to adapt learning rates for each parameter. This process can contribute to spike-dominated updates because the accumulated second moments, representing an exponentially decaying average of squared gradients, can exhibit high variance, particularly for parameters with infrequent or small gradients. Consequently, updates to these parameters are occasionally disproportionately large, manifesting as spikes in the update vector. The weight decay component of AdamW, while improving generalization, does not fundamentally alter this behavior inherent in the second-moment accumulation process itself, and can even exacerbate it in certain scenarios by further emphasizing the influence of these accumulated statistics.
Numerical methods used in spectral processing, specifically iterative techniques like Newton-Schulz iteration, introduce computational errors termed ‘numerical variance’. This variance arises from the finite precision of floating-point arithmetic and the accumulation of rounding errors during iterative calculations. While present across the spectrum, the impact of numerical variance is not uniform; it disproportionately affects the tail spectrum – the region representing low-magnitude singular values. This is because these low-magnitude values are closer to the limits of numerical precision, making them more susceptible to even small errors. Consequently, directions associated with these tail spectrum components exhibit increased sensitivity to noise and reduced reliability, potentially distorting the true underlying signal.
Relative variance serves as a quantifiable metric for assessing the reliability of directions within the tail spectrum of a gradient descent optimization process. Specifically, it measures the variance of a given direction’s contribution to the gradient, normalized by the direction’s singular value; a higher relative variance indicates greater sensitivity to noise and potentially less consistent updates along that direction. This metric is derived from the observation that directions associated with smaller singular values – characteristic of the tail spectrum – inherently exhibit amplified noise due to their diminished signal strength, making their contributions to optimization less stable and more susceptible to perturbation. Consequently, directions with high relative variance are considered less trustworthy for consistent progress toward an optimal solution.
Spectral analysis, particularly employing Singular Value Decomposition (SVD), provides a foundational method for characterizing the distribution of variance within a gradient update’s spectral components. SVD decomposes the gradient update matrix into orthogonal vectors – singular vectors – and associated singular values representing the magnitude of variance along each corresponding direction. By analyzing the singular value spectrum, researchers can identify dominant directions of update and assess the reliability of less prominent, ‘tail’ spectrum components. Quantitatively, the singular values themselves provide a direct measure of the variance explained by each corresponding singular vector, while the ratio between successive singular values can highlight potential conditioning issues or the presence of low-rank structure within the gradient update. This allows for precise identification and quantification of spectral characteristics, informing understanding of optimization behavior and potential biases like spectral bias.
Spectra Optimizer: Rebalancing the Gradient Landscape
The Spectra Optimizer is a novel optimization algorithm engineered to address issues arising from dominant low-rank spikes in gradient updates, a common phenomenon in large language model training. These spikes can destabilize training and reduce convergence speed. Spectra attenuates the impact of these spikes by explicitly identifying and down-weighting the dominant subspace within the gradient. Simultaneously, the algorithm is designed to preserve information contained in the remaining, typically lower-magnitude, components of the gradient – the ‘tail spectrum’ – which contribute to finer-grained parameter updates and potentially improved generalization. This targeted approach aims to achieve a more balanced optimization process by mitigating the influence of disproportionately large updates while retaining the signal from less prominent, but still valuable, gradient components.
The Spectra Optimizer utilizes warm-started power iteration to efficiently estimate the low-rank spike subspace, reducing computational cost by initializing the iteration with a prior estimate of the dominant singular vectors. This contrasts with standard power iteration which begins from a random initialization. Simultaneously, RMS normalization is employed to calibrate the step size during optimization; this dynamically adjusts the learning rate based on the root mean square of recent gradients, preventing excessively large updates that can arise from the spike and ensuring stable convergence. The combination of these techniques allows for a more focused and efficient optimization process, particularly in models susceptible to dominant low-rank updates.
The Spectra Optimizer addresses optimization instability caused by disproportionately large updates originating from dominant low-rank components – termed ‘spikes’ – within the gradient. Conventional optimizers can be significantly influenced by these spikes, leading to erratic training and reduced convergence speed. Spectra mitigates this by reshaping the update direction, effectively attenuating the contribution of the spike subspace while preserving information from less dominant spectral components. This reshaping process calibrates the step size based on the relative magnitude of gradient components, promoting a more balanced optimization trajectory and preventing excessive adjustments driven by the spike, ultimately leading to improved stability and faster convergence.
Performance evaluations of the Spectra Optimizer demonstrate substantial improvements over existing methods. On the LLaMA3-8B model, Spectra achieves a 30% reduction in training time, a 49.25% decrease in optimizer state memory usage, and a 1.62% improvement in average downstream accuracy when compared to AdamW. Further testing on LLaMA3-8B indicates a 1.5% reduction in final loss. On the Qwen3-0.6B model, Spectra exhibits a 0.7% faster step time and a 5.1x increase in throughput compared to the Muon optimizer.

Toward a More Balanced Future for LLM Optimization
The Spectra Optimizer represents a significant advancement in large language model (LLM) training, offering a pathway to greater efficiency and resilience, especially when dealing with complex semantic tasks. Traditional optimization methods often struggle with the spectral imbalance inherent in LLM parameter spaces – a situation where certain parameter directions dominate the learning process, hindering the model’s ability to capture subtle nuances in language. This new optimizer directly addresses this imbalance by dynamically adjusting the learning rate for each parameter based on its corresponding eigenvalue, effectively encouraging a more balanced and informative update across the entire model. Consequently, models trained with the Spectra Optimizer demonstrate improved generalization capabilities and robustness to adversarial examples, while also potentially requiring fewer computational resources to achieve comparable performance levels – a crucial step towards democratizing access to advanced AI technologies.
Addressing the spectral imbalance within large language models presents a significant opportunity to enhance both performance and training efficiency. Traditional optimization methods often fail to adequately account for the distribution of singular values in the model’s weight matrices, leading to a skewed spectrum where a few dominant values overshadow others. This imbalance hinders the model’s ability to capture nuanced semantic relationships and necessitates excessive computational resources for effective training. By explicitly targeting and correcting this spectral distortion, researchers aim to create a more balanced representation, allowing models to learn more effectively with fewer parameters and reduced computational demands. Consequently, a more harmonious spectral profile not only improves model accuracy and generalization but also lowers the barrier to entry for developing and deploying these powerful technologies, fostering innovation and wider accessibility.
Further research endeavors are now directed toward a rigorous examination of the underlying theoretical foundations of spectral optimization, seeking to formally define its convergence properties and limitations across diverse training scenarios. This includes investigating how the technique interacts with various model architectures – extending beyond transformers to recurrent and convolutional networks – and assessing its performance on a broader spectrum of datasets, encompassing those with varying degrees of complexity and dimensionality. Exploration will also focus on adapting the method to different training paradigms, such as federated learning and continual learning, with the aim of establishing a comprehensive understanding of its potential and limitations in real-world applications. Ultimately, these investigations aim to refine spectral optimization into a more predictable and versatile tool for enhancing the efficiency and effectiveness of large language model training.
The development of large language models currently demands substantial computational resources, creating barriers to entry for many researchers and organizations. This work suggests a pathway toward mitigating these limitations by enabling more efficient training methodologies. A reduction in computational cost doesn’t simply translate to financial savings; it dramatically lowers the environmental impact associated with training these massive models, fostering a more sustainable approach to artificial intelligence development. Consequently, wider accessibility to LLM technology becomes increasingly feasible, democratizing innovation and allowing a broader range of voices and perspectives to contribute to the ongoing evolution of this powerful tool. Ultimately, this research aims to unlock the full potential of large language models by making them more readily available and environmentally responsible.
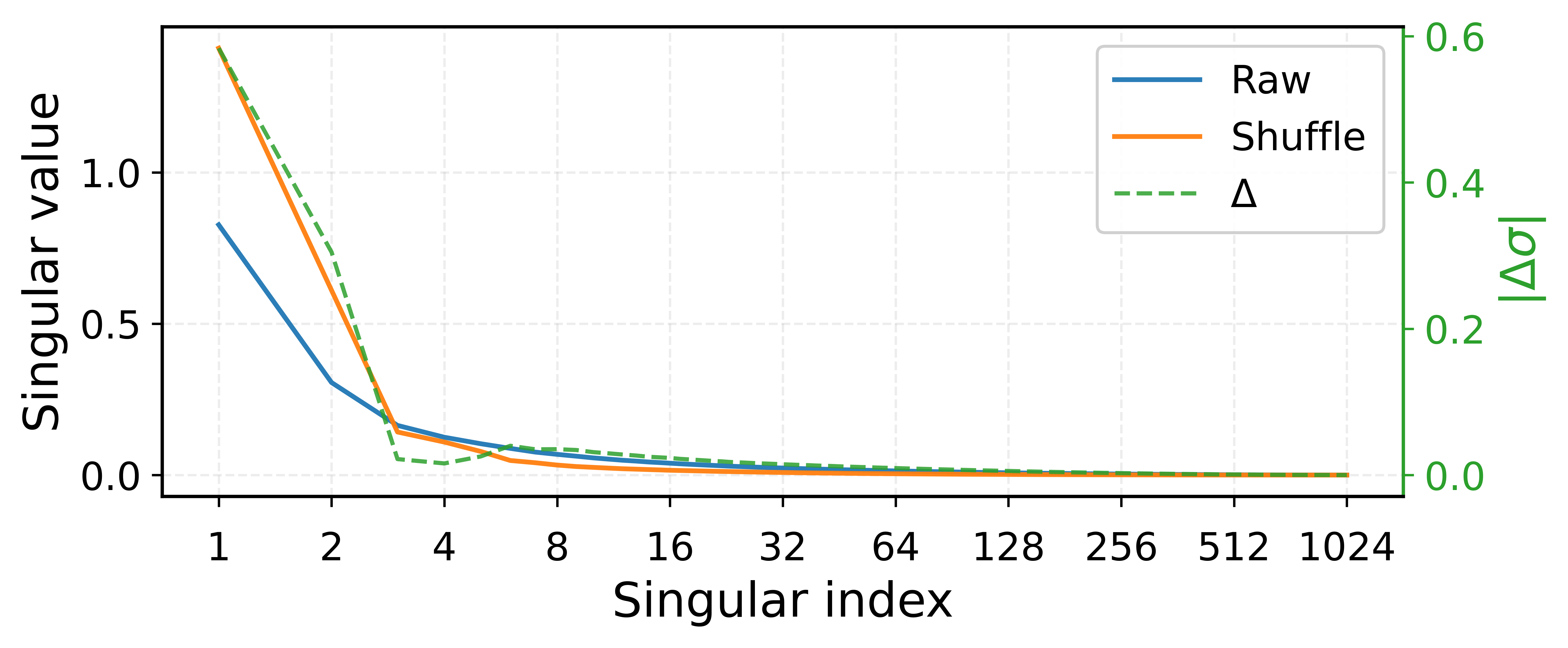
The pursuit of efficient large language model training, as detailed in this work, benefits from a rigorous examination of gradient behavior. The authors’ identification of spectral anisotropy and subsequent development of Spectra demonstrate a commitment to parsimony-reducing complexity to achieve optimal performance. This aligns with Dijkstra’s assertion: “It’s not enough to get it right; you have to understand why it’s right.” The selective attenuation of dominant spikes and avoidance of tail amplification, core tenets of Spectra, aren’t merely algorithmic choices; they represent an understanding of the underlying gradient landscape and a deliberate effort to minimize unnecessary computational expense. The focus on variance reduction directly addresses the challenges presented by stochastic gradients, prioritizing clarity and efficiency in the optimization process.
What Remains?
The identification of spectral anisotropy as a defining characteristic of large language model gradients is not, itself, a resolution. It is merely the sharpening of a previously blurred observation: optimization landscapes are not uniform, and treating them as such introduces unnecessary complication. Future work must address the fundamental question of why these spectral properties consistently manifest. Is this an inherent feature of the scaling laws governing LLMs, or a byproduct of current architectures and training procedures? The answer, predictably, will likely be both.
The immediate path forward is not simply the proliferation of spectral optimizers. While selective attenuation, as demonstrated by Spectra, offers a pragmatic improvement, it is a treatment of symptoms, not a cure. A more elegant solution would involve architectural modifications that intrinsically reduce gradient anisotropy. Perhaps a re-evaluation of attention mechanisms, or the incorporation of explicit regularization terms designed to constrain the spectral distribution. The pursuit of simplicity demands it.
Ultimately, the field must resist the temptation to endlessly refine second-order methods. Such approaches, while theoretically appealing, invariably introduce computational overhead. The true intelligence lies not in mirroring the complexity of the landscape, but in navigating it with minimal intervention. The goal is not to model the problem more accurately, but to eliminate the need for such modeling entirely.
Original article: https://arxiv.org/pdf/2602.11185.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- Here Are the Best TV Shows to Stream this Weekend on Paramount+, Including ‘48 Hours’
- Gold Rate Forecast
- 20 Films Where the Opening Credits Play Over a Single Continuous Shot
- Top gainers and losers
- 10 Underrated Films by Wyatt Russell You Must See
- Best Video Games Based On Tabletop Games
- Top 20 Overlooked Gems from Well-Known Directors
- ‘The Substance’ Is HBO Max’s Most-Watched Movie of the Week: Here Are the Remaining Top 10 Movies
- Brent Oil Forecast
2026-02-15 12:19