Author: Denis Avetisyan
A new framework uses the logic of network attacks to create more reliable and understandable explanations for how graph neural networks make decisions.
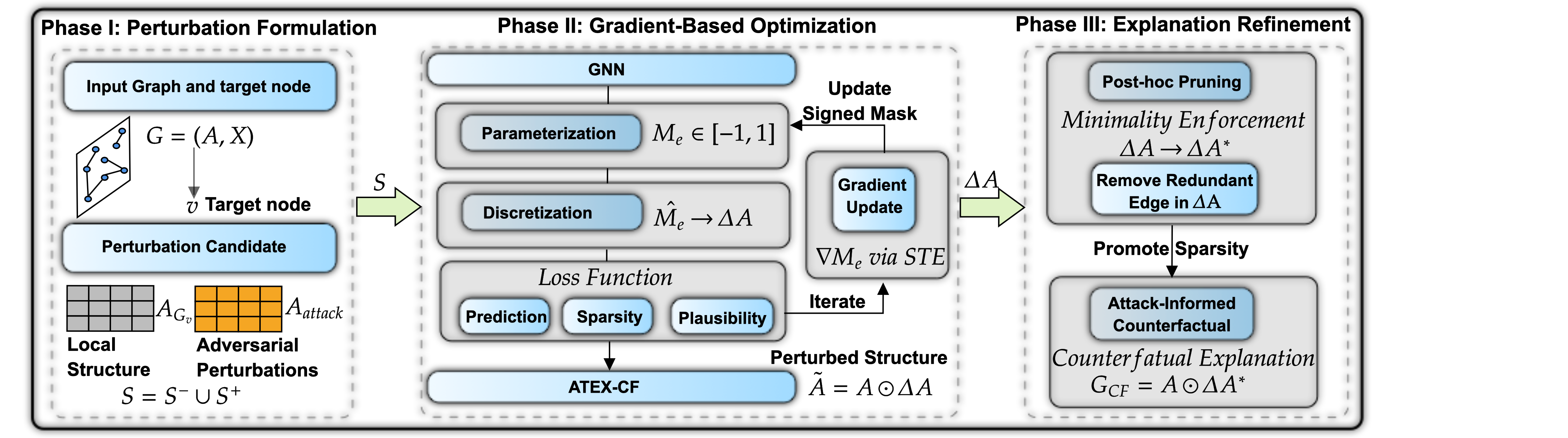
ATEX-CF leverages adversarial perturbations to generate counterfactual explanations for graph neural networks, improving both interpretability and robustness.
Despite the increasing deployment of graph neural networks (GNNs), interpreting their predictions remains a significant challenge. This paper introduces ‘ATEX-CF: Attack-Informed Counterfactual Explanations for Graph Neural Networks’, a novel framework that unifies adversarial attack strategies with counterfactual explanation generation to identify minimal graph alterations that change a model’s output. By jointly optimizing for fidelity, sparsity, and plausibility-and leveraging both edge additions and deletions-ATEX-CF produces more informative and realistic explanations than existing methods. Could this integration of adversarial robustness and counterfactual reasoning unlock a new era of trustworthy and interpretable GNNs?
The Fragility of Connection: Understanding Graph Neural Network Vulnerabilities
The expanding deployment of Graph Neural Networks (GNNs) across crucial applications – from drug discovery and social network analysis to fraud detection and recommendation systems – is accompanied by growing concern regarding their susceptibility to even minor alterations in the underlying graph structure. Unlike traditional neural networks operating on grid-like data, GNNs are inherently sensitive to changes in connections, meaning that seemingly insignificant additions, deletions, or modifications to a graph’s edges can drastically reduce predictive performance. This fragility stems from the message-passing mechanism at the heart of GNNs, where information propagates through the graph; subtle perturbations can disrupt these pathways, leading to inaccurate or misleading results. Consequently, ensuring the robustness of GNNs against such perturbations is not merely an academic exercise, but a critical requirement for their reliable implementation in real-world scenarios where data integrity and trustworthy predictions are paramount.
Graph Neural Networks, despite their increasing prevalence, exhibit a surprising susceptibility to adversarial attacks that subtly alter the graph’s connections. These manipulations, often imperceptible to human observation, can dramatically reduce a GNN’s accuracy, even when the changes to the graph structure are minimal. Researchers have demonstrated that adding or removing just a few edges can cause misclassification in node classification or graph prediction tasks, highlighting a critical vulnerability for applications in areas like fraud detection, social network analysis, and drug discovery. This fragility raises significant concerns about deploying GNNs in safety-critical systems where even minor perturbations could lead to erroneous conclusions and potentially harmful outcomes, demanding a focus on developing robust defense mechanisms and adversarial training strategies.
The increasing deployment of Graph Neural Networks (GNNs) in critical applications – from drug discovery to social network analysis – necessitates a thorough understanding of their inherent vulnerabilities. A system’s trustworthiness isn’t solely defined by its average performance, but also by its predictable behavior under adverse conditions; subtle manipulations to a graph’s structure can trigger significant performance drops, raising concerns about reliability in real-world scenarios. Consequently, research focused on identifying and mitigating these weaknesses isn’t merely academic, but a practical imperative for building resilient machine learning systems. This pursuit involves developing novel defense mechanisms, robust training strategies, and rigorous evaluation benchmarks to ensure that GNNs can maintain their accuracy and integrity even when confronted with malicious or unexpected data perturbations, ultimately fostering greater confidence in their deployment and impact.
Unveiling the ‘Why’: The Logic of Counterfactual Explanations
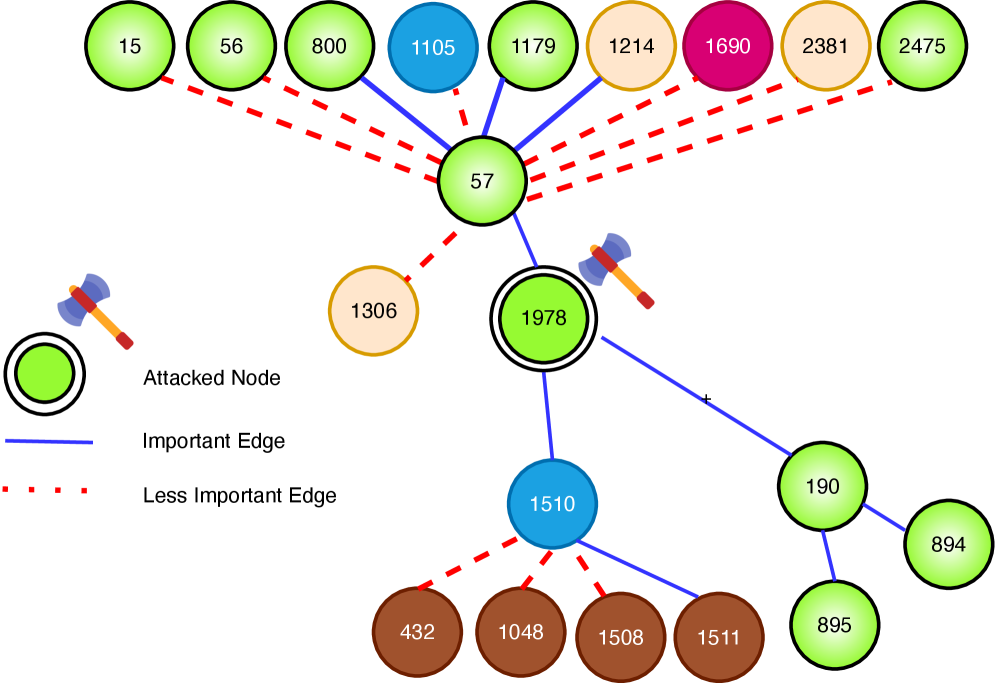
Counterfactual explanations for Graph Neural Network (GNN) predictions function by identifying the smallest modifications to an input graph that would result in a different outcome. This process differs from simply highlighting influential features; instead, it pinpoints specific nodes or edges whose alteration – through addition, removal, or attribute change – would flip the model’s prediction. The generated counterfactual serves as a “what if” scenario, demonstrating the critical factors driving the GNN’s decision for a given instance. These explanations are not about general feature importance across the entire dataset, but rather a localized analysis focused on the specific input graph and its resulting prediction. The goal is to provide actionable insights into the model’s reasoning by revealing the minimal changes needed to achieve a desired alternative outcome.
Unlike feature importance methods which isolate individual node or edge attributes as influential, counterfactual explanations in Graph Neural Networks (GNNs) identify specific, interconnected substructures responsible for a given prediction. This moves beyond assessing the impact of isolated features to reveal how relationships between nodes and edges contribute to the outcome. By pinpointing minimal alterations to these substructures – such as changing a single edge or node attribute within a connected component – counterfactual explanations demonstrate which network patterns are critical for the model’s decision-making process. This allows for a more nuanced understanding of the model’s reasoning, highlighting not just what influenced the prediction, but how the graph’s topology and attributes combined to produce it.
The utility of counterfactual explanations is directly tied to their characteristics of sparsity and plausibility. Sparsity refers to the minimization of alterations made to the original input graph; explanations requiring fewer changes are generally preferred as they highlight the most critical factors influencing the prediction. Plausibility ensures that the suggested changes represent realistic modifications within the domain of the graph data; alterations that are improbable or nonsensical diminish the explanation’s value and interpretability. A balance between these two properties – minimal, yet realistic changes – is essential for generating effective and trustworthy counterfactual explanations.
ATEX-CF: Integrating Attack Semantics for Robust Explanations
ATEX-CF is a newly developed framework designed to improve counterfactual explanation generation by directly integrating the underlying mechanics of adversarial attacks. Unlike traditional methods that treat counterfactuals as simple perturbations, ATEX-CF analyzes how attacks modify the graph structure to induce misclassifications. This allows the framework to identify minimal and semantically meaningful changes that, when applied to the input, would alter the model’s prediction. By explicitly modeling attack semantics, ATEX-CF aims to produce explanations that are not only accurate but also robust against potential adversarial manipulations, addressing a key limitation of existing explanation techniques.
ATEX-CF improves counterfactual explanation generation by directly modeling the mechanisms of adversarial attacks on graph-structured data. The framework analyzes how attacks modify the graph’s features or structure to induce misclassifications. This understanding allows ATEX-CF to prioritize minimal changes that specifically address the attack vectors, rather than generating arbitrary perturbations. By identifying the most impactful modifications from an attacker’s perspective, the resulting counterfactuals offer more relevant and effective explanations, highlighting the precise features or relationships that, if altered, would change the model’s prediction and defend against the specific attack.
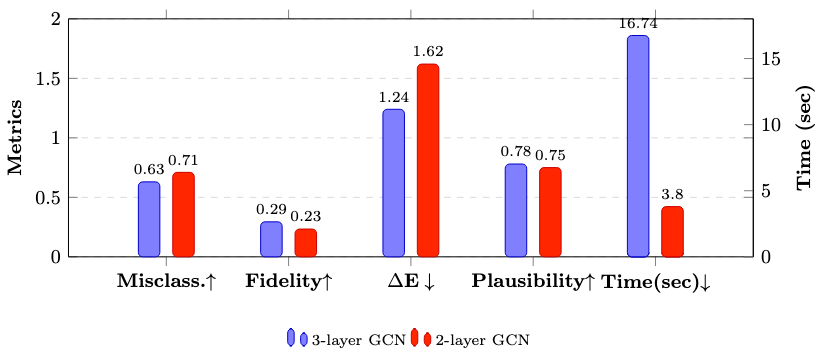
The ATEX-CF framework generates explanations that exhibit increased robustness against adversarial attacks, a result validated by performance on benchmark datasets. Specifically, ATEX-CF achieves a misclassification rate of 0.83 when tested on the BA-Shapes dataset and a rate of 0.90 on the ogbn-arxiv dataset. These results demonstrate that ATEX-CF consistently outperforms alternative explanation methods in scenarios where input data is subject to manipulation designed to cause incorrect model predictions. The higher misclassification rate, in this context, indicates a greater ability to identify meaningful changes for explanation even under attack.
Evaluations of the ATEX-CF framework demonstrate superior performance in generating explanations compared to existing methods, as measured by explanation quality and robustness metrics. Specifically, ATEX-CF achieved a plausibility score of 0.76 when tested on the Chameleon dataset. This metric assesses the degree to which the generated explanations align with human understanding and expectations regarding feature importance. The observed score indicates a higher level of alignment and trustworthiness in the explanations produced by ATEX-CF compared to those generated by alternative approaches.
The Interplay of Structure and Sensitivity: Shaping Explainable GNNs
The effectiveness of counterfactual explanations in graph-structured data hinges significantly on the inherent organization of the network itself. Specifically, the principle of homophily – the tendency of nodes to connect with others similar to themselves – profoundly influences what constitutes a plausible and actionable change. In networks exhibiting strong homophily, minimal alterations to a node’s attributes or connections are often sufficient to shift the model’s prediction, leading to concise and readily understandable counterfactuals. Conversely, in graphs lacking such patterns, achieving a change in prediction may necessitate more extensive and less intuitive modifications, potentially rendering the explanation less helpful. Therefore, a successful counterfactual explanation strategy must account for the graph’s topology, recognizing that alterations respecting the existing network structure are both more likely to be effective and more meaningful to the end-user.
The robustness of Graph Neural Networks (GNNs) to subtle alterations, and consequently the quality of counterfactual explanations, is deeply intertwined with inherent model characteristics. A significant margin – the difference between a GNN’s confidence in the correct class versus the most likely alternative – dictates how much perturbation is needed to shift a prediction. Smaller margins imply heightened sensitivity to even minor changes in the graph structure. Furthermore, Lipschitz continuity – a measure of how much the GNN’s output changes with respect to changes in its input – governs the stability of predictions. A GNN with lower Lipschitz continuity is more susceptible to perturbations, demanding more substantial edits to achieve a counterfactual outcome. These properties aren’t simply technical details; they fundamentally shape the landscape of plausible explanations, influencing both the size and nature of the modifications required to alter a prediction and defining the boundaries of what constitutes a meaningful counterfactual.
A nuanced understanding of how graph structure and model properties intertwine is driving the development of increasingly precise counterfactual explanations. Researchers are moving beyond generalized explanation techniques to create methods specifically attuned to the characteristics of individual graph datasets and the architectures of the Graph Neural Networks (GNNs) used to analyze them. This targeted approach acknowledges that explanations effective for a densely connected, homophilic network might be wholly inappropriate for a sparse, heterogeneous one, and that a GNN with a shallow decision margin demands a different explanatory strategy than one with high confidence in its predictions. By tailoring explanations to these specific contexts, it becomes possible to generate more robust, concise, and actionable insights – ultimately enhancing trust and interpretability in graph-based machine learning systems.
Evaluations on the BA-Shapes dataset reveal that the ATEX-CF method generates remarkably concise counterfactual explanations, requiring an average edit size of only 1.24 – indicating minimal changes to the graph structure are needed to alter the prediction. Furthermore, a strong correlation – measured by a Graph Embedding Vector (GEV) similarity of 0.88 – exists between the perturbations an attacker would apply to misclassified nodes and the changes highlighted by the ATEX-CF explanations. This high similarity suggests that the identified changes are not merely arbitrary modifications, but rather represent meaningful alterations that directly address the model’s reasoning, enhancing the trustworthiness and interpretability of the counterfactual explanations provided.

The pursuit of clarity in graph neural networks demands a ruthless pruning of complexity, mirroring the principle that a system’s strength lies in its essential components. This work, ATEX-CF, exemplifies this by refining counterfactual explanations through adversarial attacks, effectively identifying and removing superfluous edges. As Barbara Liskov once stated, “Programs must be correct and usable. Correctness is verified by formal methods; usability is verified by users.” ATEX-CF prioritizes both – correctness through robustness against adversarial perturbations and usability through more interpretable explanations achieved by focusing on minimal, impactful edge changes. The framework doesn’t simply add to existing explanations; it distills them, revealing the core connections driving the network’s decisions.
What’s Next?
The pursuit of explanation, particularly for graph neural networks, often feels like adding ornamentation to a fundamentally opaque structure. This work, by framing counterfactuals through the lens of adversarial attack, at least acknowledges the inherent fragility of these systems – a welcome shift. The emphasis on addition as a corrective measure, alongside deletion, is a subtle but vital point. It suggests that understanding isn’t always about stripping away complexity, but about discerning which complexities truly matter. Yet, this remains a local optimization. The true test lies in scaling this approach beyond single-instance explanations.
A persistent challenge is the assumption that a ‘minimal’ counterfactual – the smallest change to achieve a different prediction – is inherently the most interpretable. This feels suspiciously like applying Occam’s Razor without considering the cost of that razor. Future work should investigate whether larger, more nuanced perturbations, even if less elegant, reveal deeper systemic vulnerabilities. The field must resist the urge to prioritize aesthetic simplicity over practical insight.
Ultimately, the efficacy of any explanation hinges not on its internal consistency, but on its utility. Can these attack-informed counterfactuals genuinely improve model robustness? Can they guide meaningful intervention in the underlying graph structure? Until these questions are answered, explanation remains a fascinating exercise in self-deception, a way to feel clever without necessarily knowing more.
Original article: https://arxiv.org/pdf/2602.06240.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Brent Oil Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2026-02-09 18:10