Author: Denis Avetisyan
A new study reveals that text-to-image models leave subtle fingerprints in their creations, allowing researchers to reliably identify them even when prompts are unknown.
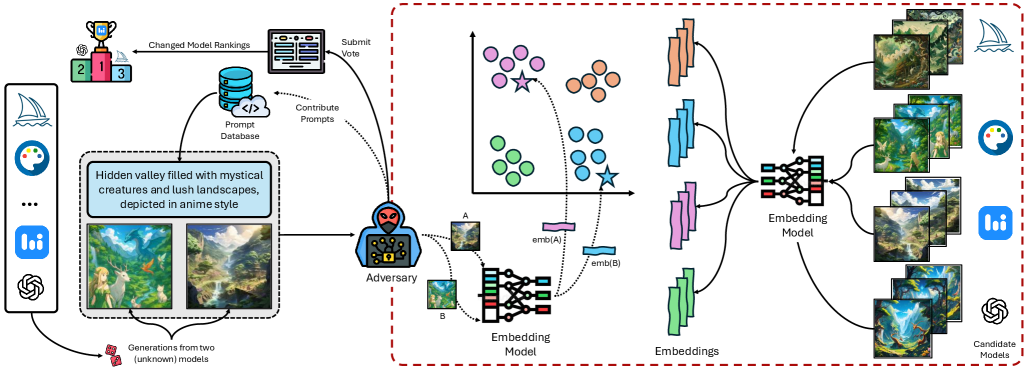
Researchers demonstrate high-accuracy model deanonymization on public leaderboards by analyzing patterns within generated image embeddings.
Despite the growing reliance on anonymized leaderboards to fairly evaluate text-to-image (T2I) models, this work, ‘Identifying Models Behind Text-to-Image Leaderboards’, demonstrates a fundamental vulnerability in these systems. We show that generations from different T2I models form distinct, identifiable clusters within image embedding space, enabling accurate deanonymization without access to prompts or training data. This is achieved through a centroid-based method applied to a dataset of 150,000 images from 22 models and 280 prompts, revealing systematic model-specific signatures and highlighting prompts that exacerbate this vulnerability. Do these findings necessitate a re-evaluation of current anonymization defenses and the development of more robust security measures for T2I leaderboards?
The Shifting Landscape of Innovation: Leaderboards and the Illusion of Anonymity
The proliferation of online leaderboards has become a defining characteristic of progress in text-to-image model development. These platforms, often community-driven, facilitate rapid innovation by providing a standardized and public arena for evaluating model performance. Instead of relying solely on subjective assessments or limited benchmarks, developers actively compete to achieve top rankings, pushing the boundaries of image generation quality and creative potential. This competitive environment incentivizes the swift implementation of new techniques and architectures, as demonstrated by the accelerated pace of improvement in areas like photorealism, artistic style transfer, and prompt adherence. The transparent nature of these leaderboards also fosters a collaborative spirit, allowing researchers to learn from each other’s successes and failures, ultimately accelerating the overall advancement of the field.
Voting-based leaderboards, increasingly common in the evaluation of text-to-image models, function on the principle of anonymity to mitigate inherent biases and foster equitable comparison. The core idea is that human voters, presented with outputs from various models without knowing their origins, will judge solely on aesthetic appeal and adherence to prompts. This prevents pre-existing brand recognition or developer reputation from influencing the results, ensuring a more objective ranking. By masking the identities of the generating models, the system attempts to isolate the quality of the image itself as the primary determinant of success, creating a fairer competitive landscape and driving innovation through genuinely superior outputs. However, maintaining complete anonymity proves challenging, as subtle stylistic fingerprints or recurring patterns can sometimes reveal a model’s origin, potentially undermining the intended fairness of the evaluation process.
The premise of unbiased evaluation in text-to-image model leaderboards frequently rests on the idea that voters are unaware of the model generating each image, but maintaining true anonymity proves surprisingly difficult. Subtle stylistic quirks, watermarks, or even consistent aesthetic choices can inadvertently reveal a model’s origin to experienced observers, potentially introducing bias into the voting process. This lack of complete anonymity opens the door to strategic manipulation, where individuals or groups might favor models they have a vested interest in, or unfairly penalize others. Consequently, the integrity of these leaderboards – intended to reflect genuine progress in image generation – is compromised, and the resulting rankings may not accurately represent the relative capabilities of each model, creating an uneven playing field for developers and researchers.
Unveiling the Generators: The Fragile Facade of Anonymity
Deanonymization of generated images relies on the premise that generative models impart unique, albeit subtle, characteristics to the images they produce. These characteristics stem from the model’s architecture, training data, and stochastic processes used during image creation. While visually imperceptible to humans, these ‘fingerprints’ manifest as consistent patterns in the image’s pixel distribution, frequency components, or feature embeddings. By analyzing these patterns, deanonymization techniques can differentiate between images generated by different models, even when those models are trained on similar datasets and generate visually comparable content. The success of these techniques hinges on the ability to extract and quantify these subtle differences, often requiring sophisticated machine learning algorithms and large datasets of generated images for training and comparison.
Image embedding transforms images into numerical vectors, or embeddings, which facilitate quantifiable comparison. Models such as CLIP (Contrastive Language-Image Pre-training) and SigLip achieve this by learning to map images to a high-dimensional space where semantically similar images are located closer to each other. CLIP, trained on a massive dataset of image-text pairs, excels at capturing visual concepts, while SigLip focuses on lip-reading and visual speech representation. These embeddings serve as a condensed, machine-readable representation of the image’s content, enabling the application of machine learning algorithms for tasks like clustering and classification, and ultimately, model identification.
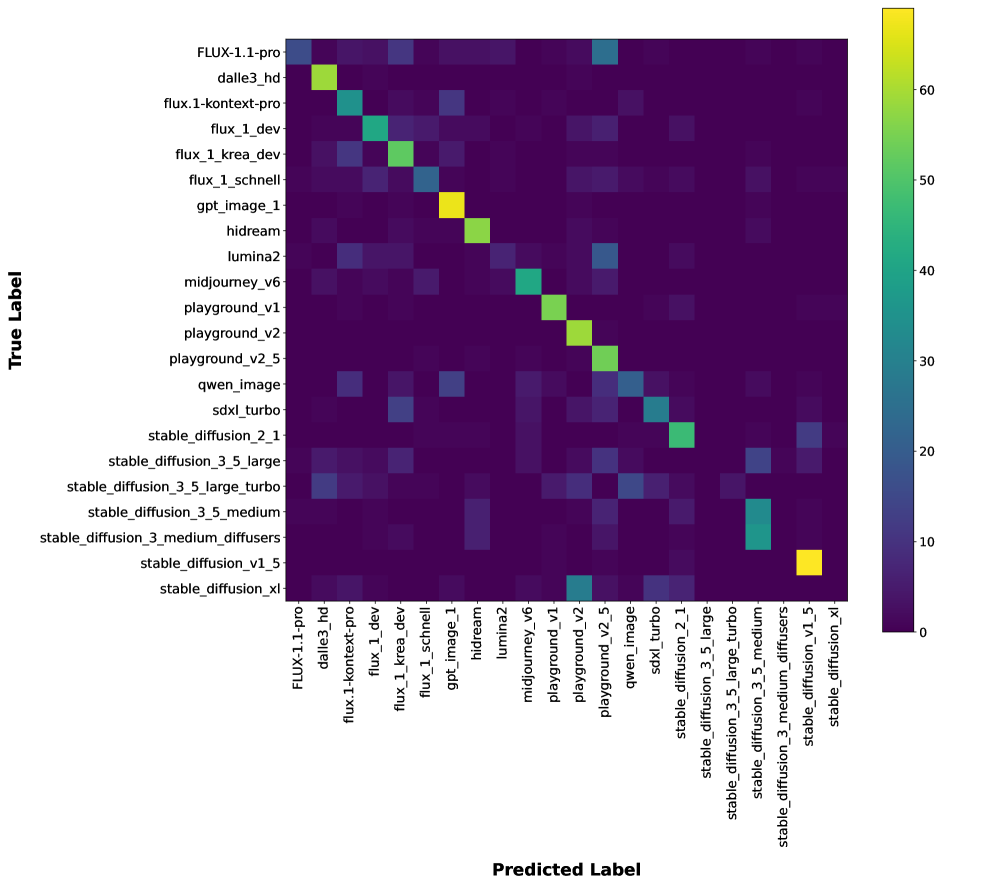
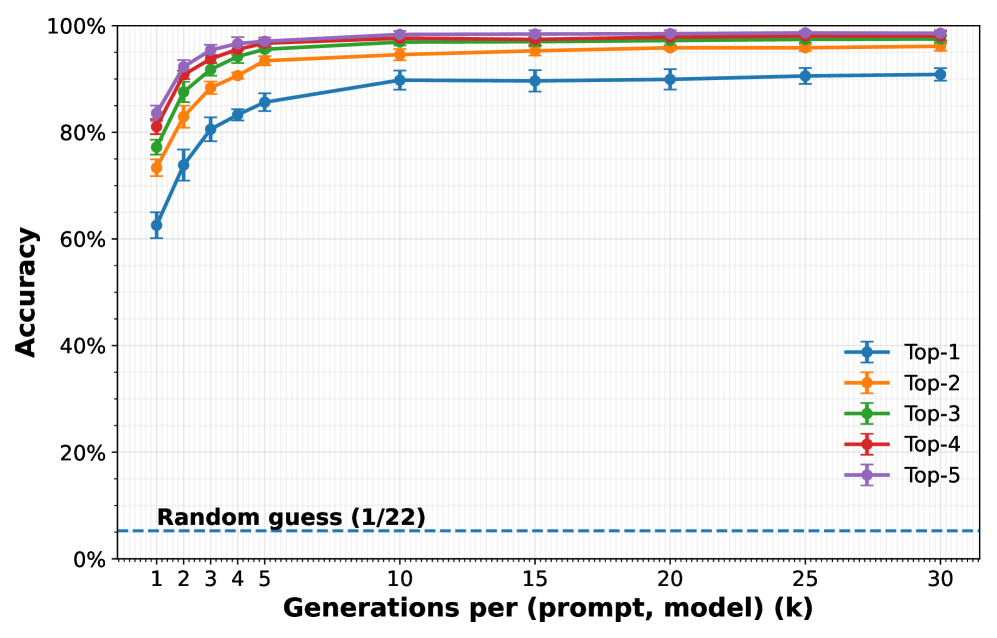
Centroid-based classification leverages the aggregated embedding vectors – or centroids – representing each generative model to determine the origin of a given image. After generating image embeddings using models such as CLIP or SigLip, the embedding of an unknown image is compared to these pre-calculated centroids. Classification is then performed by assigning the unknown image to the model associated with the nearest centroid, measured by cosine similarity. In our experiments, this approach achieved a top-1 accuracy of 91%, indicating a high degree of reliability in identifying the generative model responsible for creating a given image based solely on its embedding representation.
The Threat of Strategic Misrepresentation: Exploiting Anonymity’s Weaknesses
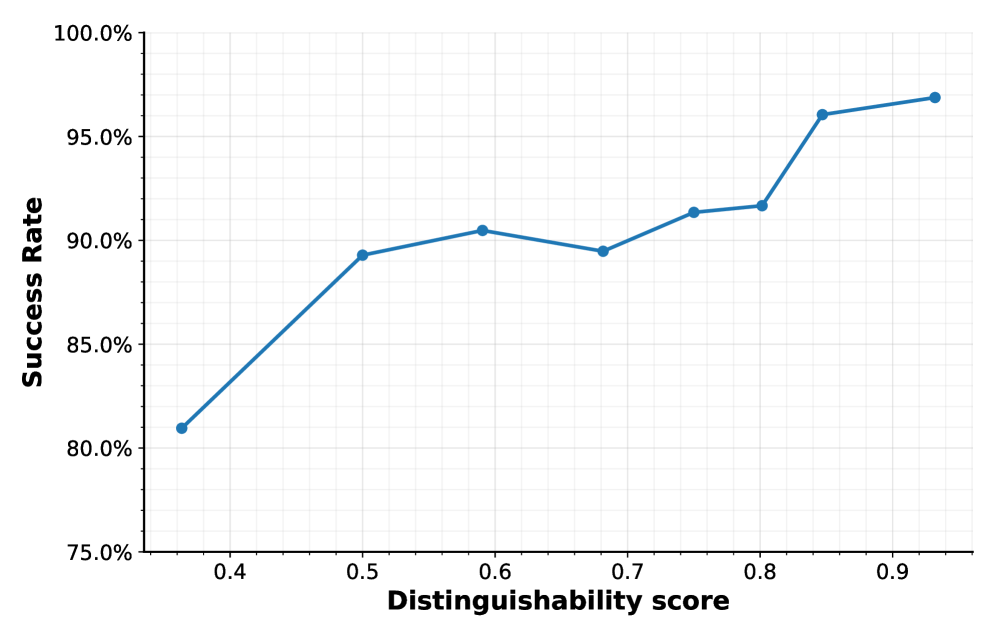
Adversarial attacks targeting model anonymity focus on identifying the specific generative model responsible for a given output. These attacks exploit the subtle characteristics, or “fingerprints,” inherent in each model’s generation process to reverse-engineer its origin. The primary goal is to manipulate leaderboard rankings, where models are often evaluated anonymously to ensure fairness. By successfully deanonymizing a model, an attacker can strategically submit outputs designed to misrepresent its true capabilities, either inflating its apparent performance or deliberately depressing it to disadvantage competitors. This compromises the integrity of the evaluation process and incentivizes deceptive practices, as models are no longer judged solely on merit but also on the attacker’s ability to conceal or misrepresent their identity.
Compromised anonymity in machine learning model evaluations introduces significant risks to the integrity of benchmarking processes. When models can be reliably linked to their creators or training data, fair comparison becomes untenable, as participants may strategically tailor submissions to exploit known weaknesses in evaluation metrics rather than optimize for general performance. This incentivizes misrepresentation, where models are deliberately designed to perform well on the specific evaluation dataset, even if this does not translate to real-world utility. Consequently, leaderboard rankings cease to accurately reflect genuine model capabilities and instead become indicators of adversarial skill in manipulating the evaluation system.
Adversarial attacks targeting model anonymity rely on measurable differences in generated outputs. Inter-Model Variation refers to discrepancies in responses from different language models given the same prompt, while Intra-Model Variation describes inconsistencies in a single model’s outputs when presented with identical inputs. These variations, stemming from stochastic processes within the models, serve as unique fingerprints enabling deanonymization. Empirical results demonstrate that with complete access to all models under evaluation, deanonymization accuracy reaches 99.16%, indicating a high degree of identifiability based solely on generated text.
Preserving Integrity: Strategies for Protecting Anonymity and Ensuring Robust Evaluation
Image perturbation presents a promising strategy for safeguarding privacy by actively disrupting the underlying structure of image embeddings used in deanonymization attacks. This defense mechanism introduces carefully crafted alterations to images, effectively scattering the resulting embedding vectors away from tightly-knit clusters that would otherwise reveal their original identity. By subtly modifying pixel values, the technique aims to increase the difficulty for attackers attempting to match embeddings to known individuals or datasets, thus hindering their ability to re-identify the source of an image. The core principle relies on creating a degree of “noise” within the embedding space, making it significantly harder to pinpoint a specific image within a larger collection, and effectively preserving anonymity despite potential adversarial scrutiny.
To fortify image embeddings against adversarial attacks, a training strategy employing Contrastive Loss is utilized. This technique doesn’t simply teach a model to recognize images, but actively encourages it to produce similar embeddings for slightly modified versions of the same image. By minimizing the distance between embeddings of original and perturbed images during training, the model learns to focus on core visual features rather than pixel-level details. Consequently, small modifications – those typically exploited in deanonymization attempts – have a diminished effect on the resulting embedding, making it more resistant to attack and preserving the anonymity of the represented image. This proactive approach builds robustness directly into the model, offering a powerful defense against subtle manipulations designed to compromise image integrity.
Recent investigations into the economic feasibility of deanonymizing images reveal a surprisingly low cost of approximately $1.08 per image when utilizing commercially available models. However, this vulnerability isn’t insurmountable; adversarial post-processing techniques demonstrably reduce the accuracy of such attacks. The effectiveness of these defenses correlates directly with the magnitude of the applied perturbation – larger modification budgets yield stronger protection against deanonymization efforts. This suggests a trade-off between image quality and privacy, where a carefully calibrated level of intentional distortion can significantly increase the cost and difficulty for malicious actors attempting to re-identify individuals from their image data.

The study reveals a fascinating parallel to the way physical systems leave unique ‘fingerprints.’ Just as a physicist can identify a material by its spectral signature, this research demonstrates that text-to-image models imprint identifiable patterns within the embedding space of generated images. This echoes Geoffrey Hinton’s observation: “The beauty of deep learning is that it allows us to learn complex patterns from data.” The ability to consistently deanonymize models, even against adversarial attacks and varied prompt engineering, underscores the inherent structure within these systems – a structure that, like any natural phenomenon, betrays its origin through careful observation. The work highlights how seemingly random outputs are, in fact, governed by underlying deterministic processes, leaving detectable traces in the generated imagery.
What Lies Ahead?
The demonstrated susceptibility of text-to-image models to deanonymization via inherent generation patterns suggests a fundamental limitation in current architectures. While prompt engineering strives for novelty, these findings reveal a predictable undercurrent, a kind of ‘digital fingerprint’ embedded within the generative process. Future work must carefully examine data boundaries; spurious patterns emerge when training datasets are not rigorously audited for unintentional consistencies. The ease with which models can be distinguished, even without prompt control, necessitates a shift towards methods that actively obfuscate these identifying characteristics.
A particularly intriguing direction lies in exploring the interplay between embedding space structure and generative signatures. It remains unclear whether these patterns are intrinsic to the diffusion process itself, or artifacts of specific training procedures. Developing robust metrics to quantify ‘generational distinctiveness’-beyond simple image similarity-will be crucial. The current emphasis on photorealism should be tempered with consideration for unpredictability; a truly creative system should resist easy categorization.
Ultimately, this work highlights a recurring tension in machine learning: the pursuit of measurable progress often creates new vulnerabilities. While leaderboards serve as convenient benchmarks, they may inadvertently incentivize the development of models that are, paradoxically, less innovative, prioritizing conformity over genuine creative exploration. A healthy dose of skepticism regarding easily quantifiable metrics is warranted.
Original article: https://arxiv.org/pdf/2601.09647.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Brent Oil Forecast
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-16 01:46