Author: Denis Avetisyan
New research reveals that privacy-preserving machine learning techniques can significantly degrade performance on datasets where some classes are far more common than others.
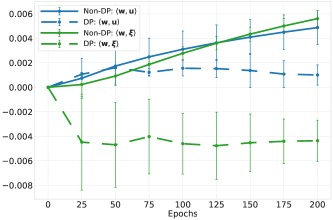
Differentially Private training hinders generalization on long-tailed datasets by suppressing the memorization of noise patterns crucial for feature learning.
While deep learning models achieve high accuracy by memorizing training data, this practice introduces significant privacy risks mitigated by differentially private training algorithms like DP-SGD. This work, ‘Understanding the Impact of Differentially Private Training on Memorization of Long-Tailed Data’, investigates how DP-SGD affects memorization, revealing that it disproportionately hinders generalization performance on long-tailed datasets-those with many rare samples. Specifically, our analysis demonstrates that gradient clipping and noise injection jointly impede a model’s ability to effectively learn and retain informative, yet underrepresented, patterns. Can we develop more nuanced DP strategies that preserve privacy while safeguarding the memorization of critical information in long-tailed data distributions?
The Long Tail and the Veil of Privacy
A pervasive characteristic of many real-world datasets is the presence of long-tailed distributions, a phenomenon where a small number of classes account for the vast majority of instances, while the remaining classes are significantly underrepresented. This imbalance poses a substantial challenge to machine learning algorithms, as models tend to become heavily biased towards the dominant classes, achieving high accuracy on these frequent examples but exhibiting poor performance on the rarer, yet often critically important, classes. Consequently, predictive models trained on such data may fail to generalize effectively, leading to inaccurate or unreliable results when encountering instances from the underrepresented classes-a particular concern in fields like medical diagnosis, fraud detection, and ecological monitoring, where identifying rare events is paramount. The inherent bias stems from the model optimizing for overall accuracy, inadvertently prioritizing the frequent classes to minimize loss, and effectively ignoring the subtle patterns present in the minority classes.
Contemporary machine learning increasingly relies on datasets containing sensitive personal information, driving a parallel need for privacy-preserving techniques during model development. Traditional training methods often require direct access to raw data, creating vulnerabilities to breaches and raising ethical concerns about data misuse. Consequently, research is actively exploring alternatives like federated learning, differential privacy, and homomorphic encryption. These approaches aim to enable model training on decentralized or obfuscated data, minimizing the risk of exposing individual records while still achieving acceptable performance. The development of robust and scalable privacy-preserving methods is not merely a technical challenge, but a crucial step towards building trustworthy and responsible artificial intelligence systems.
The confluence of data imbalance and stringent privacy regulations creates a particularly thorny problem for machine learning practitioners. Models trained on datasets where certain classes are severely underrepresented often exhibit markedly reduced performance on those minority classes – a phenomenon exacerbated when privacy-preserving techniques, such as differential privacy or federated learning, are applied. These techniques, while vital for data security, can further diminish the already limited signal from underrepresented groups, leading to disproportionately large performance drops. Consequently, achieving both accuracy and privacy requires innovative approaches that specifically address the challenges posed by long-tailed distributions, moving beyond methods designed for balanced datasets and necessitating a careful trade-off between model utility and data protection.
Masking the Signal: A DP-SGD Approach
Differentially Private Stochastic Gradient Descent (DP-SGD) mitigates privacy risks during machine learning model training by injecting calibrated noise into the gradient calculations at each iteration. This process introduces randomness, obscuring the contribution of individual data points to the overall gradient update. The magnitude of the added noise is controlled by the privacy parameter ε, with smaller values indicating stronger privacy guarantees but potentially reduced model accuracy. Specifically, noise is sampled from a probability distribution-typically a normal distribution-with a standard deviation proportional to the clipping norm and inversely proportional to ε. This ensures that the algorithm satisfies ε-differential privacy, bounding the maximum difference in the probability of observing any given output when training on datasets differing by only one record.
Gradient clipping is a core component of DP-SGD, functioning by limiting the sensitivity of the gradient computation to any single data point. During training, before noise is added for privacy, each individual gradient vector is normalized to have a maximum L_2 norm, denoted as C. This clipping operation prevents any single example from disproportionately influencing the model update, effectively bounding the contribution of individual data points to the overall gradient. By limiting this sensitivity, gradient clipping directly enhances the privacy guarantees provided by the subsequent addition of noise, as the noise needs to mask only a bounded contribution from each data point rather than an unbounded one. The clipping threshold, C, is a hyperparameter that must be carefully tuned; a smaller value provides stronger privacy but may hinder model convergence, while a larger value weakens privacy but can improve convergence speed.
Differentially Private Stochastic Gradient Descent (DP-SGD) demonstrates compatibility with established neural network architectures, notably the Two-Layer CNN, facilitating its implementation in existing machine learning pipelines. This integration is achieved through standard backpropagation with the addition of gradient clipping and noise injection, requiring minimal architectural modifications. Empirical results indicate that models trained with DP-SGD on the Two-Layer CNN achieve a quantifiable privacy-utility trade-off, maintaining acceptable accuracy levels while satisfying differential privacy guarantees. The relative ease of integration with common architectures lowers the barrier to entry for researchers and practitioners seeking to deploy privacy-preserving machine learning solutions without extensive redesign of existing systems.
The Fragility of Features: A Matter of Representation
Effective feature learning is a core component of modern machine learning model performance, as it allows algorithms to automatically identify and extract the most salient information from raw data, rather than relying on manually engineered features. This automated discovery process is particularly beneficial when dealing with complex datasets where relevant features are non-obvious or high-dimensional. Models capable of robust feature learning generally exhibit improved generalization performance, meaning they perform better on unseen data, and require less domain expertise for successful implementation. The quality of learned features directly impacts the model’s ability to discriminate between classes or predict outcomes accurately; therefore, advancements in feature learning techniques are frequently linked to state-of-the-art results across various machine learning tasks.
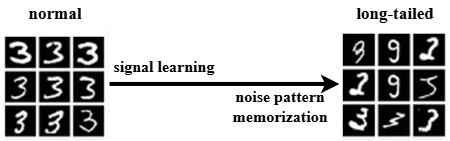
Long-tailed data distributions, characterized by a few classes with many examples and numerous classes with few, present challenges for feature learning. Models trained on such datasets often exhibit a bias towards dominant classes, allocating disproportionately more learned features to represent them. This can result in overfitting to the majority classes while underperforming on the tail, or minority, classes due to insufficient representation. The model effectively learns features that are highly predictive of the dominant classes but lack generalizability to the less frequent ones, leading to decreased performance on overall dataset accuracy and a skewed representation of the underlying data distribution.
Noise pattern memorization refers to the phenomenon where a machine learning model does not simply learn the underlying signal from training data, but instead learns and reproduces the noise inherent in that data. This is particularly problematic in imbalanced datasets, where the model may prioritize memorizing noise associated with minority classes due to their limited representation. Consequently, the model’s generalization performance degrades, as it struggles to differentiate between true signal and spurious noise. Recent research demonstrates that Differentially Private Stochastic Gradient Descent (DP-SGD) can effectively suppress noise memorization, mitigating this issue and improving model robustness, especially when training on datasets with imbalanced class distributions.
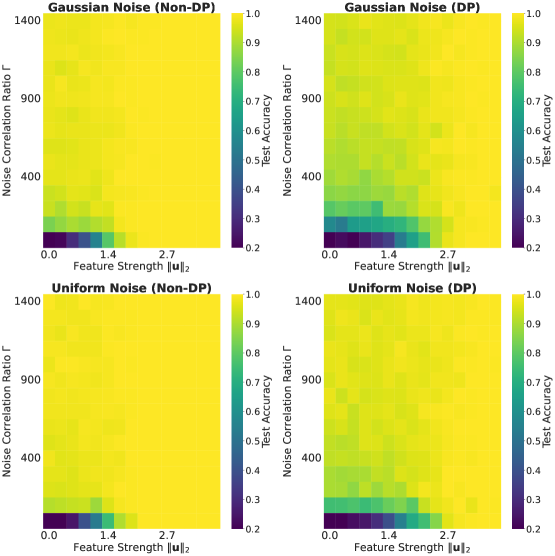
Dissecting the Influence: Quantifying the Impact
Understanding how individual data points and inherent noise impact machine learning models is crucial for building robust and reliable systems. Researchers are increasingly employing metrics like the Noise Correlation Ratio and Influence Score to quantify these effects. The Noise Correlation Ratio assesses the degree to which noise introduced during training correlates with changes in model predictions, revealing sensitivity to perturbations. Complementarily, Influence Score identifies data points that have the most significant leverage on a model’s output, allowing for the detection of potentially problematic or influential samples. By measuring these factors, it becomes possible to diagnose model vulnerabilities, pinpoint data biases, and ultimately improve generalization performance – particularly in scenarios involving limited or imbalanced datasets where individual data points can disproportionately affect the learning process.
Addressing the challenges posed by long-tailed datasets – where some classes have significantly fewer examples than others – requires innovative approaches to data representation. Researchers are increasingly leveraging data generation models to synthetically expand the representation of minority classes, effectively counteracting class imbalance. These models, often based on generative adversarial networks or variational autoencoders, learn the underlying distribution of existing data and then create new, plausible samples. By strategically augmenting the dataset with these generated instances, the model’s ability to generalize to under-represented classes improves, enhancing overall performance and mitigating biases that would otherwise arise from disproportionate class representation. This technique doesn’t simply increase the quantity of data, but rather intelligently reshapes the dataset to provide a more balanced learning experience for the algorithm.
Differential privacy, achieved through techniques like DP-SGD, inherently presents a utility-privacy tradeoff: bolstering data privacy typically diminishes model accuracy. However, recent research indicates this accuracy loss is not uniform across datasets; specifically, applying DP-SGD to long-tailed datasets-those with uneven class representation-yields a surprisingly reduced performance degradation compared to standard, balanced distributions. This improvement isn’t merely empirical; the study establishes theoretical bounds on test error, demonstrating its dependence on the strength of the underlying signal in the data, the level of correlation between noise added for privacy, and the allocated privacy budget. These bounds offer a quantifiable understanding of the tradeoff, suggesting that, under certain conditions, the benefits of enhanced privacy through DP-SGD can be realized with a minimal impact on model performance, particularly when dealing with the complexities of real-world, imbalanced data.
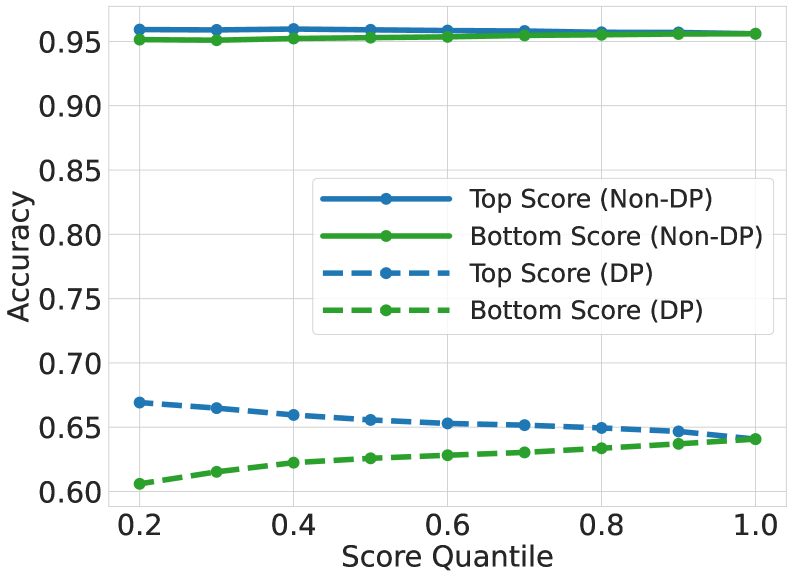
The study illuminates a fascinating paradox: the very mechanisms designed to protect data privacy-differential privacy-can inadvertently impede a model’s ability to learn robust feature representations from long-tailed data. This resonates with Ken Thompson’s observation, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code first, debug it twice.” Just as debugging reveals unforeseen interactions within code, this research unveils how seemingly beneficial privacy constraints interact with data distributions, creating unexpected challenges for generalization. Suppressing memorization of noise patterns, while bolstering privacy, restricts the model’s capacity to discern meaningful signals, effectively increasing the ‘debugging’ required for effective learning.
Beyond the Veil of Privacy
The work presented illuminates a predictable, yet persistently overlooked, tension: the imposition of formal privacy guarantees actively degrades performance on data distributions reflecting the inherent messiness of the real world. Differential Privacy, while elegant in its construction, functions as a controlled demolition of nuance. It flattens the signal, discarding the very noise that, counterintuitively, often is the information. The suppression of memorization on long-tailed datasets isn’t a bug; it’s a feature, revealing that generalization isn’t about perfect abstraction, but about skillfully reconstructing patterns from incomplete and often contradictory evidence.
Future inquiry should not focus on mitigating this performance loss-that is a Sisyphean task. Instead, the field should embrace the inherent trade-offs and investigate how controlled forgetting-a deliberate reduction in model capacity-can be leveraged as a regularization technique, even without formal privacy constraints. Perhaps the true architecture of intelligence lies not in maximizing information retention, but in expertly curating what is discarded.
The challenge, then, is to move beyond the pursuit of provable guarantees and towards a more pragmatic understanding of how models learn to operate within the bounds of uncertainty. It requires acknowledging that the map is not the territory, and that any attempt to perfectly model reality will inevitably fail – and that, in failure, lies the potential for genuine insight.
Original article: https://arxiv.org/pdf/2602.03872.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Brent Oil Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Games That Faced Bans in Countries Over Political Themes
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2026-02-06 04:29