Author: Denis Avetisyan
New research sheds light on why large language models confidently generate incorrect statements, and how internal analysis can reveal patterns in these ‘hallucinations’.

This study introduces a benchmark for evaluating factual accuracy and uses internal state analysis with hidden state clustering to identify and visualize tendencies towards generating false citations in large language models.
Despite advances in scale and performance, Large Language Models (LLMs) remain prone to factual hallucination-generating false or misleading information-a critical limitation in high-stakes applications. This paper, ‘Visualizing and Benchmarking LLM Factual Hallucination Tendencies via Internal State Analysis and Clustering’, introduces FalseCite, a novel benchmark dataset, and investigates these tendencies through analysis of internal model states. Our findings reveal that deceptive citations significantly amplify hallucination rates, and that patterns within hidden state vectors-often tracing a distinctive horn-like shape-can partially visualize these behaviors. Can a deeper understanding of these internal states ultimately lead to more robust and reliable LLMs?
The Persistent Illusion: Defining Hallucination in Large Language Models
Large language models, despite their impressive ability to generate human-quality text, are prone to “hallucinations”- instances where the model confidently produces information that is factually incorrect or entirely fabricated. This phenomenon isn’t a matter of simple error; the models don’t typically know they are wrong, presenting these inaccuracies with the same assurance as truthful statements. These hallucinations can range from subtle distortions of existing knowledge to the complete invention of events, people, or data. The underlying cause appears to stem from the probabilistic nature of their training – models predict the most likely continuation of a text sequence, even if that sequence deviates from reality. Consequently, while adept at mimicking language patterns, these models lack a grounded understanding of truth and can generate outputs that, while grammatically correct and contextually relevant, are demonstrably false, posing significant challenges for applications requiring reliable information.
The emergence of inaccuracies, often termed ‘hallucinations’, in large language models presents a significant impediment to their deployment in fields demanding precision and dependability. Beyond simple errors, these confidently-stated falsehoods erode user trust and introduce potentially damaging consequences in applications like medical diagnosis, legal reasoning, or financial forecasting. Consequently, the development of robust evaluation methods is paramount; current benchmarks often prove insufficient to thoroughly assess these tendencies, especially when confronted with complex, nuanced queries. A more rigorous approach to testing, capable of identifying and quantifying the scope of these inaccuracies, is vital to ensure responsible innovation and build confidence in the reliability of these increasingly powerful systems.
Current methods for evaluating large language model accuracy often prove inadequate when identifying the subtle ways these models can ‘hallucinate’ – generate incorrect or misleading information. While benchmarks effectively capture blatant factual errors, they struggle with more nuanced instances, such as plausible-sounding but ultimately fabricated details, or the confident presentation of opinions as established facts. This limitation stems from a reliance on surface-level matching against known datasets, failing to probe the model’s reasoning process or its ability to distinguish between established knowledge and internally generated content. Consequently, a high score on existing benchmarks doesn’t necessarily guarantee reliability, especially in complex tasks requiring critical thinking and source verification, highlighting the need for evaluation tools that assess not just what a model says, but how it arrives at its conclusions.
A crucial step in mitigating the problem of LLM inaccuracies lies in recognizing that “hallucinations” aren’t monolithic; they manifest in distinct ways. Some models confidently assert information demonstrably untrue – a straightforward falsehood presented as fact. However, a more insidious form involves fabrication, where the model not only states an untruth but also constructs supporting details – inventing data, sources, or even entire narratives to bolster the false claim. This fabrication is particularly problematic as it mimics credible reasoning, making the inaccuracy harder to detect and eroding trust in the model’s output. Distinguishing between these types of hallucinations – simple factual errors versus constructed falsehoods – is essential for developing targeted evaluation metrics and, ultimately, more reliable language models.

Constructing a Rigorous Test: Introducing the falseCite Benchmark
The falseCite benchmark consists of 82,000 claims designed to rigorously evaluate the propensity of Large Language Models (LLMs) to hallucinate. Unlike benchmarks solely focused on factual recall, falseCite explicitly assesses both the accuracy of generated statements and the reliability of any accompanying citations. The dataset is constructed to present challenges beyond simple knowledge retrieval, requiring models to demonstrate an understanding of evidence and the ability to discern valid support from fabricated or irrelevant sources. This dual focus on factual correctness and citational support provides a more comprehensive measure of LLM trustworthiness and highlights instances where models confidently assert false information backed by seemingly authoritative, yet fabricated, citations.
The falseCite benchmark constructs challenging evaluation scenarios by generating false statements utilizing existing datasets, specifically the FEVER Corpus and the SciQ Corpus. The FEVER Corpus, containing verified and unverified claims with supporting evidence, provides a foundation for creating claims with known factual inaccuracies. Similarly, the SciQ Corpus, a multiple-choice question answering dataset focused on scientific reasoning, is adapted to generate false statements by manipulating answer choices or claim formulations. This approach allows for the creation of a large-scale dataset of false claims grounded in existing, well-established datasets, providing a robust basis for evaluating LLM hallucination tendencies.
The falseCite benchmark utilizes two primary strategies for evaluating an LLM’s ability to differentiate between supported and fabricated evidence. Semantic matching involves pairing claims with relevant but false supporting statements, requiring the model to assess the plausibility of the connection between the claim and the provided evidence. In contrast, random pairing presents models with claims and entirely unrelated, fabricated evidence, testing whether the model can identify a complete lack of supporting information. This dual approach allows for a nuanced evaluation, distinguishing between failures to assess evidence quality and failures to recognize irrelevant information as non-supporting.
Evaluation using the falseCite benchmark demonstrates a consistent amplification of hallucination across several large language models when false claims are paired with fabricated citations. Observed hallucination rates increased when models were presented with unsupported assertions alongside nonexistent source materials; this effect was consistent across models and varied only by the degree to which the model already exhibited hallucination tendencies. The benchmark establishes that the presence of a false citation, even if semantically related to the claim, significantly exacerbates the propensity of LLMs to generate and assert inaccurate information, indicating that citation mechanisms are not reliably used to verify factual correctness.

Decoding the Black Box: Probing Internal States to Understand Hallucination Mechanisms
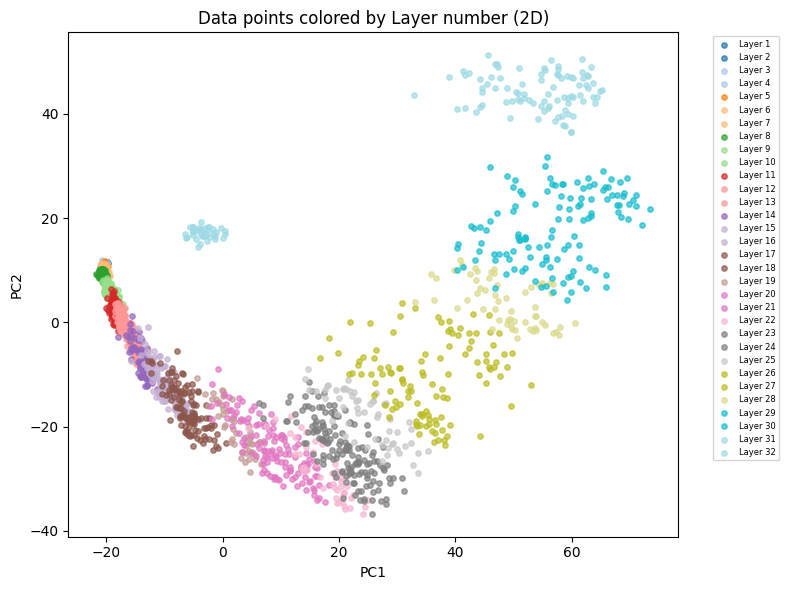
Large Language Models (LLMs) maintain internal representations of data as high-dimensional vectors, referred to as hidden states, throughout processing. Analysis of these hidden state vectors provides a means to examine the model’s internal reasoning during response generation. By inspecting these vectors, researchers can attempt to correlate specific internal states with the occurrence of hallucinated content – statements not grounded in the provided input or known facts. The premise is that distinct patterns within these hidden state vectors may correspond to different mechanisms by which LLMs generate incorrect or fabricated information, allowing for a more granular understanding of the causes of hallucination beyond simply attributing it to random error.
Prior to clustering analysis, researchers utilize dimensionality reduction techniques, such as Principal Component Analysis (PCA), to address the high dimensionality of hidden state vectors within Large Language Models (LLMs). These vectors, representing the model’s internal state during text generation, often contain thousands of parameters. PCA transforms these high-dimensional data into a lower-dimensional space while retaining the most significant variance, facilitating more effective clustering. This preprocessing step is crucial as clustering algorithms perform optimally with reduced dimensionality, enabling the identification of distinct patterns in the internal representations that correlate with hallucinatory responses. By reducing noise and redundancy, PCA enhances the ability to discern meaningful groupings within the hidden state space, ultimately aiding in the analysis of hallucination mechanisms.
Following clustering of hidden state vectors, Spearman correlation assesses the statistical dependence between these clusters and labels indicating hallucinatory responses, as determined by expert annotators – typically large language models like GPT-4.1. This non-parametric measure quantifies the monotonic relationship, allowing researchers to identify whether specific internal states, represented by the assigned cluster, are consistently associated with the generation of false or unsupported statements. A statistically significant Spearman correlation coefficient indicates that the expert annotator’s identification of hallucination aligns with the LLM’s internal state representation, supporting the hypothesis that distinct internal states correspond to different hallucination mechanisms.
Analysis of LLM internal states reveals correlations between specific hidden state vectors and the generation of factually incorrect statements. This allows researchers to categorize hallucination mechanisms, differentiating between phenomena like citation-driven hallucination – where errors stem from misinterpreting or fabricating source material – and content-based hallucination, originating from the model’s internal knowledge representation. Validation of these categorizations utilizes expert models, such as GPT-4.1, which achieved 75.2% accuracy in identifying hallucinated responses on the HALUEVAL benchmark dataset, providing a reliable metric for assessing the link between internal states and factual accuracy.
The pursuit of demonstrable truth within large language models necessitates a rigorous approach, mirroring the foundations of mathematical proof. This study, focusing on LLM hallucination and the novel falseCite benchmark, exemplifies this dedication. It isn’t sufficient for a model to appear accurate; its internal states must reveal consistency. As David Hilbert famously stated, “One must be able to say everything that one wishes to say.” The ability to reliably generate factual information, and to trace the origins of that information, is paramount. The analysis of hidden state vectors, and the subsequent clustering to visualize hallucination tendencies, directly addresses the need for provable accuracy – an algorithmic elegance independent of specific language implementation.
What Lies Ahead?
The demonstrated correlation between spurious citations and amplified hallucination, while statistically observable, begs a fundamental question: is this merely a symptom of imperfect training data, or does it reveal a deeper flaw in the architecture’s capacity for epistemological grounding? The clustering of hidden state vectors, though visually suggestive, remains a descriptive exercise; a taxonomy of error, rather than an explanation of its genesis. True progress demands a shift from observing these failures to proving their inevitability – or, conversely, designing architectures demonstrably resistant to them.
The benchmark introduced, ‘falseCite’, is a necessary, though insufficient, step. Benchmarking, without a rigorous theoretical understanding of the underlying failure modes, risks becoming an exercise in adversarial gaming. Optimization without analysis is self-deception, a trap for the unwary engineer. Future work must focus on formalizing the conditions under which these models produce verifiable falsehoods, establishing provable bounds on their factual accuracy.
Ultimately, the pursuit of ‘trustworthy’ LLMs requires more than scaled datasets and clever prompting. It demands a return to first principles – a re-examination of the mathematical foundations of knowledge representation and inference. Until then, these models remain impressive statistical engines, capable of fluent fabrication, but fundamentally incapable of distinguishing truth from elegant falsehood.
Original article: https://arxiv.org/pdf/2602.11167.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-02-15 07:04