Author: Denis Avetisyan
A novel framework leverages federated learning and voice augmentation to improve Alzheimer’s Disease detection through speech analysis, even with scarce patient data.
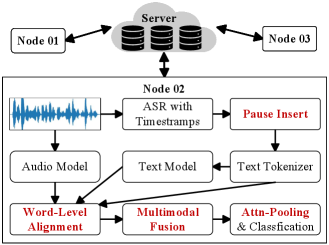
This review details a federated and augmented learning approach incorporating voice conversion and adaptive model selection for enhanced Alzheimer’s Disease detection via speech.
Early diagnosis is critical for managing Alzheimer’s Disease, yet progress is hampered by the scarcity and privacy restrictions surrounding patient data. Addressing this challenge, our work, ‘Breaking Data Efficiency Dilemma: A Federated and Augmented Learning Framework For Alzheimer’s Disease Detection via Speech’, introduces FAL-AD, a novel framework that synergistically combines federated learning with voice conversion-based data augmentation to substantially improve data efficiency. This approach achieves state-of-the-art performance on speech-based Alzheimer’s detection, reaching 91.52% accuracy, while preserving data privacy across institutions. Could this framework pave the way for more accessible and effective early detection of neurodegenerative diseases?
The Data Bottleneck in Alzheimer’s Detection
The potential to significantly improve outcomes for individuals with Alzheimer’s Disease hinges on early and accurate detection, yet current diagnostic pathways present substantial barriers. Establishing a definitive diagnosis often requires costly neuroimaging techniques, like PET scans and MRIs, alongside invasive cerebrospinal fluid analysis – procedures that are not only financially prohibitive for many, but also carry inherent risks and discomfort. This reliance on expensive and potentially harmful methods delays intervention, limiting the effectiveness of available treatments and hindering participation in crucial clinical trials. Consequently, a significant number of individuals remain undiagnosed until the disease has progressed to later stages, diminishing the window for therapeutic benefit and placing a greater burden on healthcare systems.
The potential of spontaneous speech analysis as a non-invasive biomarker for early Alzheimer’s detection is significant, yet currently constrained by a critical lack of comprehensively labeled data. Unlike imaging or cerebrospinal fluid analysis, speech offers a readily accessible and cost-effective means of assessment; however, training artificial intelligence models to reliably identify subtle linguistic patterns indicative of cognitive decline demands extensive datasets where speech samples are meticulously annotated for features like semantic errors, pauses, or changes in prosody. This labeling process is both time-consuming and requires specialized linguistic expertise, creating a bottleneck that limits the development of accurate and robust diagnostic tools. Consequently, while the theoretical promise of speech-based detection is strong, practical implementation is hampered by the difficulty of acquiring sufficiently large and accurately labeled speech corpora, necessitating innovative approaches to data augmentation, transfer learning, and semi-supervised learning to overcome this limitation.
The development of reliable artificial intelligence for early Alzheimer’s detection faces a critical impediment: a severe lack of readily available, labeled data. This scarcity isn’t simply a matter of collection; stringent data privacy regulations, like HIPAA and GDPR, rightly protect sensitive patient information, creating substantial hurdles for researchers. Obtaining sufficient speech samples, cognitive assessments, and medical histories necessary to train effective AI models becomes a complex and often protracted process. Consequently, even sophisticated algorithms struggle to generalize beyond limited datasets, leading to reduced accuracy and hindering the creation of truly robust diagnostic tools. The interplay between data limitations and privacy concerns represents a significant bottleneck, demanding innovative solutions – such as federated learning or synthetic data generation – to unlock the potential of AI in combating this devastating disease.
The pursuit of accurate Alzheimer’s detection using artificial intelligence is significantly challenged by the inherent demands of traditional deep learning models. These approaches, while powerful, require vast quantities of labeled data to achieve reliable performance – a necessity that clashes with the limited availability of speech samples from individuals with the disease. This ‘data hunger’ isn’t simply a matter of collection; the painstaking process of annotating speech for subtle linguistic markers of cognitive decline is both time-consuming and requires specialized expertise. Consequently, the development of robust AI tools is hampered, forcing researchers to either compromise on model accuracy or explore alternative, data-efficient machine learning techniques to overcome this critical bottleneck and accelerate early diagnosis.
A Collaborative Solution: Federated Learning
Federated Learning (FL) is a distributed machine learning approach that allows model training on a large corpus of decentralized data residing on edge devices – such as mobile phones or IoT sensors – or within geographically isolated data centers. Instead of aggregating data to a central server, FL pushes the model to these data sources, trains locally on the available data, and then aggregates only the model updates – gradients or model weights – back to a central server. This process is iterative, with the central server averaging or otherwise combining the updates to create an improved global model, which is then redistributed for further local training. The key benefit is the ability to leverage data from multiple sources without requiring data to leave its original location, thereby preserving data privacy and reducing communication costs.
Federated Learning (FL) mitigates data scarcity and enhances privacy by eliminating the need to consolidate data into a central repository. Traditional machine learning approaches require data to be pooled, which can be impractical due to data size, regulatory restrictions, or privacy concerns. FL instead trains models across a network of decentralized devices – such as mobile phones or hospital servers – each retaining its local data. Only model updates, rather than the raw data itself, are shared with a central server for aggregation, thereby preserving data privacy and reducing the risks associated with centralized data storage and transmission. This approach enables model training on larger, more diverse datasets than would otherwise be accessible, while simultaneously addressing key data governance and privacy requirements.
Standard Federated Learning (FL) implementations often encounter performance degradation when faced with non-Independent and Identically Distributed (non-IID) data. This occurs because the global model, trained through averaging locally computed updates, may not effectively generalize across clients exhibiting disparate data distributions. Specifically, if each client possesses data reflecting a unique subset of the overall feature space or exhibits varying class imbalances, the aggregated global model can be biased towards the majority distribution, leading to suboptimal performance on clients with minority or unique data. The degree of non-IIDness is typically categorized along dimensions such as feature distribution skew (different clients have different features), label distribution skew (different clients have different label proportions), and quantity skew (clients have varying amounts of data), each contributing to the challenge of achieving robust and accurate models in decentralized settings.
Model personalization in Federated Learning addresses the limitations of a single, globally shared model when faced with heterogeneous data distributions across clients. These techniques modify the global model to better suit individual client datasets, often through methods like adding personalized layers, fine-tuning specific parameters, or utilizing client-specific regularization terms. The goal is to mitigate performance degradation caused by non-IID data, where a model trained on the aggregate data may not generalize well to individual clients. Common personalization strategies include Federated Meta-Learning (FML), which learns to quickly adapt to new clients, and techniques that maintain a base global model while allowing for client-specific modifications, thereby balancing personalization with generalization capabilities and improving the overall system performance by increasing local model accuracy.
Augmented Federated Learning for Alzheimer’s: FAL-AD
The FAL-AD framework addresses the challenge of limited data availability in Alzheimer’s disease detection by employing data augmentation techniques. This process artificially expands the training dataset, increasing the volume of available samples without requiring additional real-world data collection. Specifically, augmentation is used to generate variations of existing data, improving the model’s generalization capability and robustness to unseen data. This is crucial because acquiring large, labeled datasets for neurodegenerative disease research is often difficult and expensive, and augmentation provides a viable method for improving model performance in data-scarce scenarios.
To address the scarcity of labeled pathological speech data for Alzheimer’s disease detection, the FAL-AD framework utilizes cross-category voice conversion. This technique synthesizes speech samples exhibiting characteristics of Alzheimer’s-related dysarthria by transforming speech from healthy speakers. The process generates a diverse dataset of pathological speech, effectively augmenting the limited real-world data available for training. This data augmentation strategy mitigates the challenges posed by insufficient data volume and variability, improving the robustness and generalization capability of the Alzheimer’s disease detection model.
Attention-Based Cross-Modal Fusion within the FAL-AD framework utilizes the CogniAlign architecture to improve feature extraction from multi-modal data. This process incorporates automatic speech recognition (ASR) performed by the Whisper model to achieve word-level alignment between audio and text data. By aligning these modalities at the word level, the system can more effectively integrate information from both sources. The attention mechanism then dynamically weights the contributions of each modality during feature extraction, focusing on the most relevant information for Alzheimer’s disease detection. This targeted fusion enhances the representation of complex patterns present in the combined audio and textual data, leading to improved model performance.
Adaptive Federated Learning within the FAL-AD framework dynamically optimizes model selection and collaborative strategies among participating clients to enhance both performance and system stability. This approach moves beyond static federated averaging by continuously evaluating local model contributions and adjusting aggregation weights based on observed performance metrics. Utilizing this methodology, FAL-AD achieved a state-of-the-art multi-modal accuracy of 91.52% in Alzheimer’s disease detection, demonstrating a significant improvement over existing federated learning approaches in this domain. This performance was validated using a diverse, multi-institutional dataset, ensuring generalizability and robustness of the model.
Towards Robust and Personalized Alzheimer’s Detection
A novel framework, Federated Alzheimer’s Detection (FAL-AD), showcases a compelling ability to construct remarkably accurate Alzheimer’s Disease detection models even when training data is scarce. Achieving a multi-modal accuracy of 91.52%, FAL-AD demonstrably outperforms existing centralized machine learning approaches. This advancement stems from a federated learning approach, allowing model training across decentralized datasets without direct data sharing. The framework’s efficacy isn’t simply about reaching a high accuracy score; it represents a significant step towards overcoming a critical barrier in Alzheimer’s research – the limited availability of labeled patient data – and paves the way for more reliable and accessible diagnostic tools.
A significant hurdle in Alzheimer’s research is accessing diverse and sufficient patient data, often complicated by privacy concerns. The proposed framework addresses this by utilizing decentralized data – meaning information remains with the individual institutions or patients who generate it – and employing privacy-preserving techniques. This approach circumvents the need to centralize sensitive medical records, thereby fostering greater collaboration among researchers and building trust with data contributors. By enabling analysis at the source, rather than requiring data transfer, the framework unlocks the potential of previously inaccessible datasets, accelerating the development of more accurate and representative Alzheimer’s detection models and promoting responsible data sharing practices within the scientific community.
A significant hurdle in developing effective Alzheimer’s detection models lies in the inherent variability of patient data – a phenomenon known as non-IID data, where datasets from different sources exhibit substantial differences. The Federated Learning approach, FAL-AD, directly addresses this challenge, enabling the creation of highly personalized diagnostic tools. By allowing model training on decentralized datasets without data sharing, FAL-AD preserves patient privacy while capitalizing on diverse information. Evaluations demonstrate that incorporating data augmentation techniques within FAL-AD substantially improves accuracy; multi-modal accuracy increased from 89.70% with standard Federated Learning to 91.52%, and local learning accuracy rose from 78.59% to 80.61%. This enhancement underscores FAL-AD’s potential to deliver more precise and individualized assessments, paving the way for earlier interventions and improved patient outcomes.
The development of robust Alzheimer’s detection frameworks promises a significant shift towards proactive healthcare for those at risk. Early diagnosis, facilitated by technologies like FAL-AD, is no longer simply about identifying the disease, but about enabling timely interventions – lifestyle adjustments, cognitive training, and future pharmacological treatments – that can potentially slow disease progression and preserve cognitive function. This proactive approach extends beyond clinical benefits, offering individuals and their families valuable time to plan for the future, access support networks, and make informed decisions regarding care and quality of life. Ultimately, advancements in personalized detection methods represent a move toward managing Alzheimer’s not as an inevitable decline, but as a condition that can be addressed and navigated with greater agency and hope.
The pursuit of robust Alzheimer’s Disease detection, as outlined in this framework, mirrors a fundamental tenet of system design: structure dictates behavior. The FAL-AD system’s reliance on federated learning and voice conversion isn’t merely about achieving higher accuracy; it’s about crafting a resilient architecture capable of handling data scarcity and privacy constraints. If the system looks clever – fusing cross-modal data and adaptively selecting models – it’s because those choices address inherent fragility. As Barbara Liskov aptly stated, “It’s one of the great failures of the computer field that we’ve been so focused on hardware and so little on software.” This research exemplifies a shift toward prioritizing the intelligent orchestration of data and algorithms-a testament to the enduring power of elegant software design.
Looking Ahead
The presented framework, while demonstrating efficacy in addressing data scarcity within Alzheimer’s Disease detection, merely shifts the locus of complexity. The inherent challenge isn’t simply acquiring data, but ensuring the augmented samples genuinely reflect the nuanced pathology of the disease. Voice conversion, as a tool, is predicated on the assumption that synthetic variations retain diagnostic relevance-a proposition demanding rigorous validation beyond current performance metrics. Future work must dissect the very nature of these synthetic signals, probing whether they introduce subtle biases or amplify existing noise.
Moreover, the adaptive model selection, while pragmatic, hints at a deeper unease. The “best” model isn’t necessarily the most accurate, but the one best suited to the available, and often imperfect, data. This suggests a fundamental limitation: that current methodologies are chasing shadows, optimizing for performance within a constrained space rather than achieving true understanding of the underlying biological processes. A shift toward biologically-informed feature engineering, coupled with more robust uncertainty quantification, may prove more fruitful.
Ultimately, the pursuit of data efficiency should not eclipse the imperative for interpretability. The elegance of a system lies not in its complexity, but in its capacity to reveal underlying principles. The next phase requires moving beyond predictive power toward a genuine comprehension of how vocal biomarkers relate to the progression of Alzheimer’s Disease, thereby enabling truly targeted interventions.
Original article: https://arxiv.org/pdf/2602.14655.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-02-17 23:12