Author: Denis Avetisyan
New research tackles the challenge of making optimal decisions in changing environments where underlying states are unknown, paving the way for more robust and efficient learning.
This paper introduces adaptive probing strategies for latent-state bandits that minimize regret and improve state estimation in non-stationary settings.
Sequential decision-making under uncertainty is often hampered by hidden state variables that confound reward estimation. This paper, ‘Adaptive Exploration for Latent-State Bandits’, introduces a family of state-model-free bandit algorithms leveraging lagged contextual features and coordinated probing to address this challenge. Our methods learn optimal policies without explicit state modeling by adaptively balancing exploration and exploitation in non-stationary environments, demonstrably reducing cumulative regret. Can these adaptive probing strategies be extended to tackle more complex, partially-observable Markov decision processes?
The Shifting Sands of Sequential Choice
Numerous real-world challenges necessitate a series of decisions made sequentially, yet the very definition of an ‘optimal’ choice can shift as circumstances evolve. Consider, for example, dynamically priced advertising, where the effectiveness of a given ad placement changes with user exposure and competitor bids, or even managing a portfolio of financial assets where market conditions are constantly in flux. These scenarios represent non-stationary environments – systems where the underlying reward distributions are not fixed, rendering traditional decision-making approaches ineffective. Unlike static problems where a single, best strategy can be learned and consistently applied, these dynamic systems demand algorithms capable of continuously adapting to new information and recognizing when previously successful strategies are no longer optimal. This inherent instability creates a significant hurdle in fields ranging from robotics and resource management to personalized medicine and online learning, necessitating the development of robust and flexible sequential decision-making frameworks.
Conventional bandit algorithms, while effective in stable environments, often falter when faced with non-stationary rewards. These algorithms fundamentally operate under the assumption that the probability of receiving a reward from each action remains consistent over time. However, when reward distributions shift – perhaps due to changing user preferences, seasonal trends, or external factors – this core assumption is violated. Consequently, algorithms optimized for stationary conditions become less efficient at identifying the currently optimal action, leading to suboptimal decision-making. The reliance on historical data, rather than a dynamic assessment of present rewards, causes these algorithms to persistently favor actions that were previously successful, even if their current performance has diminished, hindering their ability to adapt and maximize cumulative rewards in a changing world.
Effective decision-making in dynamic environments hinges on an algorithm’s ability to reconcile exploration and exploitation – a delicate balance continuously challenged by shifting conditions. Algorithms must actively seek new information about the evolving landscape – exploration – to identify potentially superior strategies, yet simultaneously leverage current knowledge – exploitation – to maximize immediate rewards. This isn’t a static optimization; the ideal ratio between these two approaches changes as the environment itself changes. Strategies that prioritize exploration too heavily may sacrifice short-term gains, while over-exploitation can lead to stagnation and failure to adapt to newly optimal solutions. Consequently, algorithms designed for non-stationary environments often incorporate mechanisms for detecting shifts in reward distributions and dynamically adjusting their exploration-exploitation behavior, ensuring continued performance even as the underlying conditions evolve.
The Ghosts in the Machine: Hidden States and Reward Generation
In sequential decision-making problems, observed rewards are frequently not solely determined by the actions taken by an agent but are also impacted by underlying, unobservable factors referred to as ‘hidden states’. These hidden states are dynamic, meaning their values change over time and influence the reward structure of the environment. This introduces complexity because the agent does not have direct access to these states, and must infer their influence through observed rewards and its own actions. Consequently, a reward received at a specific time step is a function of both the action taken and the current value of the hidden state, creating a stochastic reward landscape that complicates the learning process. The evolution of these hidden states is often temporally correlated, meaning the state at a given time is dependent on its previous values, further contributing to the challenge of accurately modeling the environment.
Hidden states, while not directly observed, manifest as influences on the sequential decision-making process. These states can encompass a range of factors; in robotic navigation, they might represent unmapped changes in the environment like lighting shifts or temporary obstructions. In user modeling applications, hidden states could reflect evolving user preferences, such as a shift in favored product categories or tolerance for risk. Critically, these underlying factors are not static; they represent dynamic elements that change over time and affect both the agent’s optimal actions and the resulting rewards received, creating a complex relationship between observable behavior and the unobserved drivers behind it.
A Markov Chain models the evolution of hidden states by defining a probability distribution over future states conditional only on the present state, satisfying the Markov property. This means the system’s future state is independent of its past, given its current state. Mathematically, this is expressed as P(S_{t+1} | S_t, S_{t-1}, ..., S_0) = P(S_{t+1} | S_t), where S_t represents the state at time step t. The transition probabilities between states are typically represented by a transition matrix, where each element P_{ij} denotes the probability of transitioning from state i to state j. By defining this probabilistic relationship, a Markov Chain provides a computationally tractable method for representing and predicting the sequential dependencies inherent in hidden state dynamics.
When hidden states exert influence over both the actions taken by an agent and the subsequent rewards received, they introduce confounding variables into the learning process. This creates spurious correlations between actions and rewards, as observed reward is not solely a consequence of the action itself but also of the unobserved hidden state. Consequently, standard reinforcement learning algorithms may incorrectly attribute reward to specific actions, leading to suboptimal policies. The presence of these confounders biases the estimated value function, hindering the agent’s ability to accurately learn the true relationship between actions and their expected outcomes, and requiring more complex methods to disentangle the true causal effects.
Algorithms for a Shifting World: Adaptation and Context
The Contextual Bandit framework is a machine learning paradigm for sequential decision-making where an algorithm repeatedly selects an action from a set of possibilities and receives a reward. Unlike traditional bandit algorithms which treat each action selection in isolation, contextual bandits incorporate contextual features – information about the current state or situation – to inform the action selection process. These features, represented as a vector of variables, allow the algorithm to personalize its decisions and adapt to varying circumstances. The algorithm learns a policy that maps contexts to actions, aiming to maximize cumulative reward over time. This approach is particularly well-suited for applications where the optimal action depends on the specific context, such as personalized recommendations, dynamic pricing, and adaptive clinical trials.
Contextual bandit algorithms improve reward estimation by incorporating contextual features – descriptive attributes of the current state – into their decision-making process. Instead of treating each action selection as independent, these algorithms model the probability of reward conditioned on these features. This allows the algorithm to learn a more accurate representation of the underlying reward distribution, P(reward | context), and subsequently predict rewards for new, unseen states. As environmental conditions change, the algorithm adjusts its policy based on the evolving relationship between context and reward, effectively adapting to non-stationarity. This adaptive capability is crucial in scenarios where the optimal action varies over time, as the algorithm continuously refines its understanding of the reward landscape based on observed contextual changes.
Contextual bandit algorithms, while capable of incorporating side information to improve decision-making, still face the inherent exploration-exploitation dilemma present in reinforcement learning. In non-stationary environments, the optimal action can change over time, requiring the algorithm to continuously explore potentially better options while simultaneously exploiting current knowledge to maximize immediate rewards. Insufficient exploration can lead to suboptimal policies as the algorithm fails to discover improved actions, while excessive exploration reduces cumulative reward. Effectively balancing these competing objectives is crucial for achieving good performance in dynamic settings, and requires strategies that adapt the exploration rate based on observed changes in the environment or uncertainty in reward estimates.
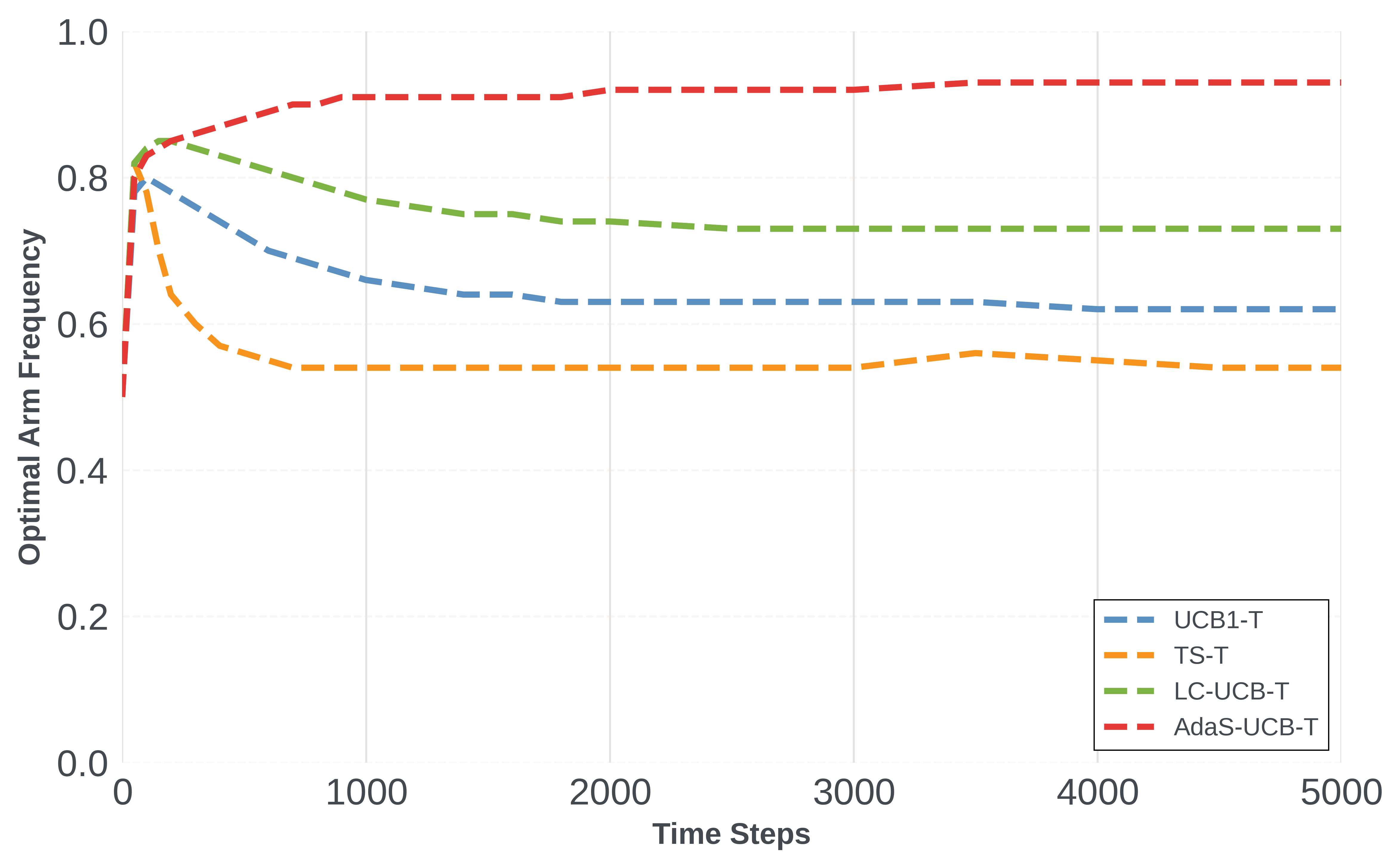
Dynamic Regret is a standard metric used to evaluate the performance of algorithms in non-stationary environments, representing the cumulative difference between the total reward achieved by the algorithm and the total reward that would have been achieved by consistently following the optimal policy. Lower Dynamic Regret indicates better performance, signifying the algorithm quickly adapts and minimizes the loss compared to the ideal strategy. In our experiments, the adaptive probing algorithms AdaRP-UCB and AdaSP-UCB exhibited reduced cumulative regret in 12 out of 13 tested configurations, demonstrating their improved ability to learn and perform effectively under changing conditions compared to baseline algorithms.
The Price of Uncertainty: Robustness and Noise Filtering
Sequential decision-making, whether in robotics, finance, or game playing, rarely occurs within a pristine environment of clear, unambiguous rewards. Instead, real-world feedback is often corrupted by noise – inherent imperfections in the signal that indicates success or failure. This ‘reward noise’ can stem from various sources, including sensor inaccuracies, incomplete information, or the stochastic nature of the environment itself. Consequently, algorithms designed to learn optimal policies must contend with this uncertainty, distinguishing genuine progress from random fluctuations. Ignoring this pervasive noise can lead to suboptimal decision-making, as algorithms may misinterpret fleeting negative signals as true failures or, conversely, mistake temporary successes for sustainable gains. Addressing reward noise is therefore not merely a technical refinement, but a fundamental requirement for building robust and reliable intelligent agents capable of operating effectively in complex, real-world scenarios.
The presence of reward noise poses a substantial challenge to learning algorithms designed for sequential decision-making. Imperfect reward signals-those containing inaccuracies or inconsistencies-can mislead the algorithm, causing it to incorrectly assess the value of different actions and ultimately adopt suboptimal policies. This is because algorithms often rely on observed rewards to estimate the true underlying value of each option; noise obscures this true value, leading to biased estimates and potentially flawed decision-making. Consequently, an algorithm might consistently choose actions that appear rewarding based on noisy data, while better alternatives remain unexplored, hindering its ability to maximize cumulative rewards over time. Addressing this issue is crucial for deploying effective learning systems in real-world applications where perfect information is rarely, if ever, available.
The efficacy of sequential decision-making algorithms hinges on their ability to discern genuine reward signals from inherent noise, a prevalent characteristic of real-world applications. Algorithms lacking robust noise filtering mechanisms often struggle with suboptimal policy selection, as spurious fluctuations can overshadow true underlying trends. Consequently, significant research focuses on designing algorithms capable of effectively separating signal from noise, employing techniques like statistical smoothing, Bayesian inference, and robust optimization. These approaches aim to minimize the impact of noisy rewards on policy evaluation and selection, enabling algorithms to converge more reliably towards optimal behavior even in challenging, uncertain environments. Ultimately, a robust algorithm doesn’t merely react to every reward; it learns to identify and prioritize the consistent, meaningful signals that drive long-term success.
Successfully navigating dynamic, real-world scenarios demands algorithms capable of minimizing cumulative regret – the difference between the rewards obtained and those that could have been achieved with perfect foresight – even when faced with noisy or changing reward signals. Recent research highlights AdaRP-UCB as a particularly effective approach to this challenge, consistently exceeding the performance of RP-UCB, especially in volatile environments characterized by frequent shifts in optimal actions. Through rigorous testing across a spectrum of parameter settings, AdaRP-UCB demonstrably increases the frequency with which the theoretically best action is selected, suggesting a superior ability to discern genuine reward signals from random fluctuations and adapt to evolving conditions. This improved performance is critical for applications ranging from personalized medicine to financial trading, where responsiveness and robustness are paramount.
The pursuit of optimal policies in dynamic systems, as explored in this work on latent-state bandits, feels less like engineering and more like tending a garden. One attempts to coax order from chaos, knowing full well that any intervention carries the seed of future disruption. It’s a humbling endeavor. Claude Shannon observed, “The most important thing in communication is to reduce the uncertainty.” This principle resonates deeply; the adaptive probing strategies detailed here aren’t about finding the optimal policy, but about systematically reducing the uncertainty surrounding the hidden states driving the environment’s behavior. Each deploy, then, is a small apocalypse, revealing new layers of complexity and necessitating a continual recalibration of expectations.
The Shifting Sands
This work, concerned with bandits in worlds it cannot fully see, offers a temporary reprieve. It builds a more clever probe, a more nuanced question to ask of a changing reality. But the very act of asking alters the landscape. Each refined strategy for estimating hidden states presumes a particular kind of non-stationarity, a specific failure mode. The inevitable will arrive – a shift in the underlying dynamics unforeseen by any current model, rendering the carefully crafted probe… obsolete. Scalability is merely the word used to justify complexity, and the relentless pursuit of reduced regret often comes at the cost of adaptability.
The true challenge isn’t minimizing regret in a fixed, unknowable world, but accepting its inevitability. Future work will likely focus on meta-strategies – algorithms that don’t seek the best action, but the most robust method for discovering what “best” even means. This demands a shift from causal inference as a means to control, toward causal inference as a means to understand the limits of control. Everything optimized will someday lose flexibility.
The perfect architecture is a myth to keep people sane. This research, like all others, offers a fleeting glimpse of order before the inevitable entropy. The goal isn’t to build a system that solves non-stationarity, but one that can gracefully decompose when it encounters a change it cannot anticipate. The exploration itself, perpetually renewed, becomes the constant.
Original article: https://arxiv.org/pdf/2602.05139.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
- The Best Former NFL Players Turned Actors, Ranked
2026-02-07 17:15