Author: Denis Avetisyan
Researchers have developed a framework that separates behavior modeling from policy improvement, achieving superior performance and stability in offline reinforcement learning.
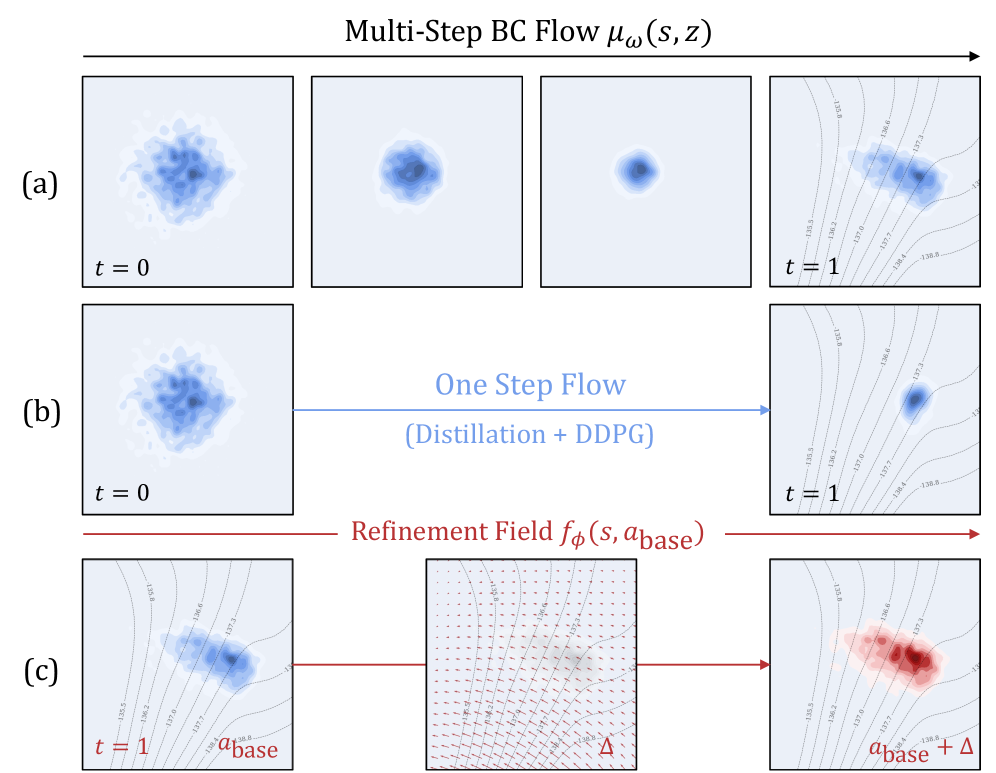
DeFlow decouples manifold modeling and value maximization using flow matching and a refinement module for improved policy learning from static datasets.
Offline reinforcement learning struggles with simultaneously capturing complex behaviors and optimizing policies, often forcing a trade-off between expressivity and stable improvement. This is addressed in ‘DeFlow: Decoupling Manifold Modeling and Value Maximization for Offline Policy Extraction’, which introduces a novel framework leveraging flow matching to independently model behavior manifolds and refine policies within a data-derived trust region. By bypassing the need for computationally expensive solver differentiation and loss balancing, DeFlow achieves state-of-the-art performance and stable offline-to-online adaptation on challenging benchmarks. Could this decoupled approach unlock more robust and efficient offline RL algorithms capable of tackling increasingly complex real-world problems?
The Imperative of Data Efficiency in Reinforcement Learning
Conventional reinforcement learning algorithms typically necessitate a substantial number of interactions with the environment to effectively learn an optimal policy. This reliance on active data collection presents significant challenges in many real-world scenarios, where each interaction might be time-consuming, expensive, or even dangerous – consider robotics applications requiring physical manipulation, healthcare interventions with patient risk, or complex simulations demanding considerable computational resources. The need for extensive trial-and-error fundamentally limits the applicability of traditional methods, pushing researchers to explore alternatives that can leverage existing, pre-collected data instead of continuously probing the environment. This quest for data efficiency is particularly relevant when dealing with systems where obtaining new data is either impractical or carries unacceptable costs, highlighting the need for learning paradigms that can thrive on static datasets.
Offline reinforcement learning presents a compelling alternative to traditional methods by enabling agents to learn effective policies solely from pre-collected datasets, circumventing the need for costly or impractical environment interactions. However, this approach is fundamentally challenged by the issue of distribution shift. Because the learned policy will inevitably dictate a different data collection process than the one that generated the static dataset, the agent encounters states and actions outside the original data distribution during execution. This mismatch – the distribution shift – can lead to overestimation of out-of-distribution actions, causing the policy to perform poorly and potentially diverge. Consequently, significant research focuses on mitigating this discrepancy, exploring techniques like conservative policy optimization and constraint-based methods to ensure the agent remains within the bounds of the observed data and generalizes effectively.
The core difficulty in offline reinforcement learning arises from a significant discrepancy between the data used for training and the policy the algorithm ultimately learns to execute; this is known as distribution shift. Because the learned policy may venture into states and actions not well-represented in the static dataset, the algorithm extrapolates beyond its experienced knowledge, leading to overestimated rewards and suboptimal performance. Consequently, innovative techniques are essential to mitigate this issue, including conservative policy optimization which constrains the learned policy to remain close to the behavior observed in the dataset, and methods that explicitly model the uncertainty associated with out-of-distribution actions. Addressing this mismatch is paramount to unlocking the potential of offline RL, enabling effective learning from previously collected data without requiring costly or impractical online interaction.
DeFlow: A Principled Decoupling of Behavior and Policy
Traditional offline Reinforcement Learning (RL) methods often struggle due to distributional shift, where the policy deviates from the data distribution used for training, leading to performance degradation. DeFlow mitigates this by explicitly decoupling the learning of a behavior model from policy optimization. The behavior model is trained to accurately reproduce the actions observed in the offline dataset, effectively learning the underlying data distribution without immediate concern for reward maximization. This separation allows for a more stable and reliable learning process, as the policy optimization phase can then focus on improving upon the learned behavior, rather than directly extrapolating from potentially out-of-distribution states and actions. This approach reduces the risk of compounding errors and improves the overall robustness of the learned policy in offline settings.
DeFlow utilizes Flow Matching, a probabilistic modeling technique, to learn a continuous generative process representing the distribution of expert demonstrations. This process is trained to transform a simple, known distribution – typically Gaussian noise – into samples resembling the observed expert data. By modeling the data distribution directly, DeFlow avoids the limitations of traditional behavior cloning which can suffer from compounding errors and distributional shift. The learned generative model effectively captures the underlying structure of successful behaviors, allowing the system to generate diverse and plausible actions mirroring expert performance without explicitly relying on discrete action choices or predefined policies. This approach allows for efficient sampling and exploration during subsequent policy optimization stages.
The DeFlow architecture incorporates a Refinement Module designed to address discrepancies between the distribution of actions generated by the learned behavior model and those required for optimal policy performance. This module operates iteratively, taking as input the state and an initial action proposed by the behavior model, and outputs a refined action. The refinement process is achieved via a parameterized function, trained to minimize the difference between the refined action and a target action, which can be derived from various sources including, but not limited to, expert demonstrations or policy gradients. By repeatedly applying this refinement, DeFlow progressively steers the generated actions towards higher-reward trajectories, effectively improving the policy without directly modifying the underlying behavior model.
DeFlow incorporates constrained optimization during policy refinement using Lagrangian multipliers to enforce adherence to predefined safety or performance boundaries. This technique introduces penalty terms to the optimization objective function, proportional to the degree of constraint violation. Specifically, for each constraint, a Lagrangian multiplier is introduced, representing the sensitivity of the objective function to that constraint. The optimization process then jointly adjusts policy parameters and Lagrangian multipliers, minimizing the primary objective while simultaneously minimizing constraint violations; L = J(θ) + Σ_{i} λ_{i}C_{i}(θ), where J(θ) is the primary objective, C_{i}(θ) represents the i-th constraint, and λ_{i} is the corresponding Lagrangian multiplier. This allows the policy to be refined while explicitly respecting specified limits on its behavior.
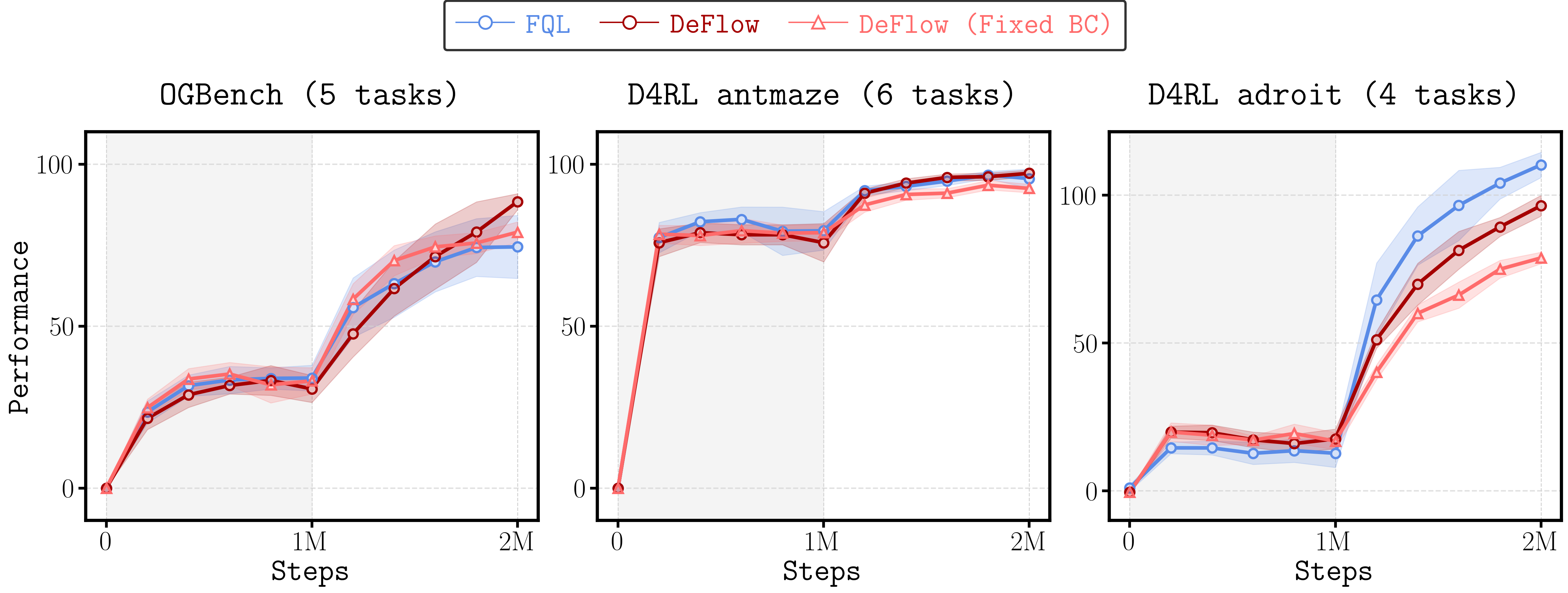
Flow Q-Learning: Achieving One-Step Policy Optimization
Flow Q-Learning represents an advancement over the DeFlow architecture by consolidating the multi-step policy refinement procedure into a single generative model. DeFlow required iterative improvements to the policy, whereas Flow Q-Learning directly outputs a refined policy in one step. This distillation is achieved by training a generator network to map states directly to optimal actions, effectively compressing the iterative process into a single forward pass. The resulting architecture reduces computational complexity and allows for more efficient policy optimization compared to the iterative approach employed in DeFlow.
Flow Q-Learning directly optimizes the policy by incorporating a learned flow model into the Q-Learning framework, eliminating the need for iterative policy refinement. Traditional Q-Learning requires repeated updates to the policy based on observed rewards; however, by leveraging the flow model to predict state transitions, the algorithm can estimate the long-term value of actions without simulating multiple steps. This direct optimization is achieved by treating the flow model as a component within the Q-function, allowing the algorithm to learn an optimal policy in a single step, thereby improving computational efficiency and convergence speed compared to iterative methods.
The One-Step Generator streamlines policy optimization by directly producing a complete policy trajectory in a single forward pass, eliminating the need for iterative refinement cycles present in methods like DeFlow. This contrasts with iterative approaches that require multiple forward and backward passes to converge on an optimal policy. By generating the entire trajectory at once, the computational cost associated with repeated forward passes is significantly reduced, enhancing overall efficiency. The generator’s output is then evaluated using the Q-Learning framework, providing a direct measure of the trajectory’s quality and facilitating gradient-based policy updates.
Backpropagation Through Time (BPTT) is employed to train the generator network within the Flow Q-Learning framework by treating the generator as a recurrent neural network. This allows for the computation of gradients across multiple time steps, effectively enabling the learning of sequential dependencies crucial for policy optimization. During training, the generator receives a state as input and outputs an action; the resulting reward is then backpropagated through the unfolded generator network to adjust its parameters. The use of BPTT facilitates efficient gradient calculation for the entire action sequence, thereby optimizing the generator’s ability to produce high-rewarding actions given a specific state and accelerating policy learning compared to methods requiring iterative updates.
Demonstrating Robust Performance and Practical Impact
DeFlow’s capabilities were rigorously tested across established offline reinforcement learning benchmarks, notably OGBench and D4RL, to quantify its performance gains. These experiments reveal a consistent ability to surpass existing algorithms in a variety of challenging scenarios. Through systematic evaluation on these standardized datasets, DeFlow demonstrated its robustness and adaptability, achieving demonstrably superior results in tasks ranging from simple locomotion to complex robotic manipulation. The framework’s consistent performance across these benchmarks establishes a strong foundation for its application in real-world scenarios where data is often limited and pre-collected, highlighting its potential to accelerate progress in offline RL.
Extensive evaluation of the DeFlow framework across a broad spectrum of reinforcement learning challenges – encompassing 7373 offline RL tasks and 1515 Online-to-Offline (O2O) scenarios – reveals a compelling performance advantage. The system consistently achieves state-of-the-art or near state-of-the-art results, demonstrably surpassing established offline RL algorithms such as FQL and contemporary diffusion-based methods. This sustained outperformance suggests DeFlow’s robust capacity to effectively learn and generalize from complex datasets, even in scenarios where data is limited or of varying quality, marking a significant step forward in offline reinforcement learning capabilities.
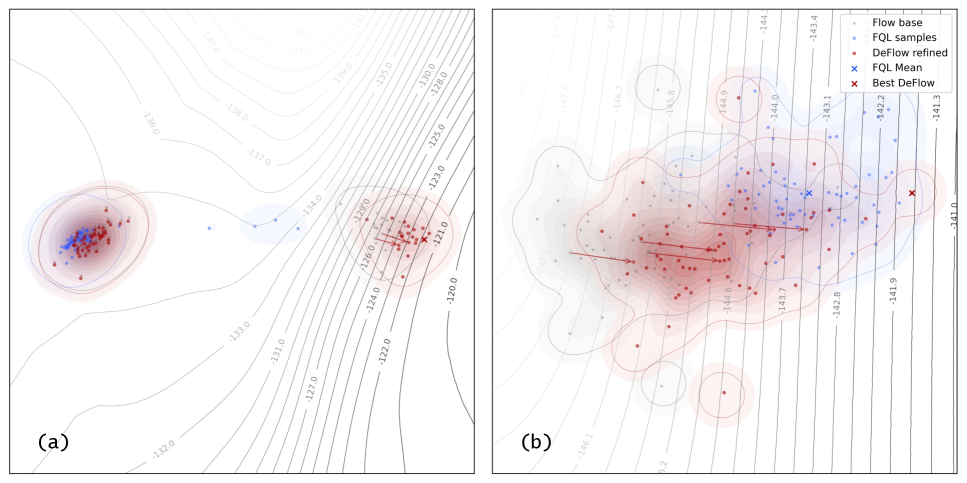
A key strength of DeFlow lies in its capacity to generate more plausible and varied actions during offline reinforcement learning. Through analysis of Intrinsic Action Variance (IAV), researchers discovered the framework doesn’t simply replicate the training data, but actively explores a wider range of potential behaviors. This is achieved by quantifying the uncertainty associated with each action, allowing DeFlow to prioritize actions that are both likely to succeed and representative of a more diverse skill set. The resulting actions are demonstrably more realistic, mitigating the risks of extrapolation errors common in offline RL, and enabling the agent to generalize effectively to unseen states and tasks. This enhanced action diversity contributes significantly to DeFlow’s superior performance across numerous benchmarks, particularly in complex scenarios where a limited repertoire of actions would typically lead to suboptimal results.
DeFlow demonstrates remarkable adaptability in Online-to-Offline (O2O) reinforcement learning scenarios, consistently matching or surpassing the performance of existing state-of-the-art algorithms, particularly in complex tasks demanding nuanced control. This success isn’t achieved through laborious tuning; the framework requires minimal hyperparameter optimization, streamlining the implementation process for researchers and practitioners. Central to this efficiency is an innovative heuristic leveraging Intrinsic Action Variance (IAV), which intelligently sets constraints during training, guiding the agent toward more robust and generalizable policies. By effectively managing the exploration-exploitation trade-off via IAV, DeFlow learns effective strategies even when transitioning from simulated online environments to real-world offline datasets, signifying a substantial advancement in offline RL applicability.
DeFlow’s architecture embodies a commitment to mathematical purity, dissecting the complex problem of offline reinforcement learning into distinct, manageable components. The decoupling of behavior modeling via flow matching from policy refinement aligns with the principle that a robust solution must be fundamentally correct, not merely empirically successful. Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” DeFlow eschews overly complex, monolithic approaches, prioritizing a provable, modular design. This mirrors Kernighan’s sentiment – a solution built on clear, understandable principles is far more valuable than one relying on intricate, potentially flawed heuristics, offering stability and a pathway to verifiable correctness-a harmony of symmetry and necessity.
What Remains to be Proven?
The decoupling achieved by DeFlow, while empirically successful, merely shifts the burden of proof. The elegance of separating behavior modeling from policy optimization is undeniable, but the inherent limitations of manifold learning remain. A truly robust framework must address the question of generalization beyond the observed data – a challenge not unique to this approach, yet acutely felt when relying on density estimation. The current reliance on flow matching, though effective, invites scrutiny regarding its scalability to exceptionally high-dimensional state spaces and the computational cost of maintaining precise gradient information.
Future investigations should prioritize formal guarantees regarding the stability and convergence properties of this decoupling. Empirical benchmarks, however impressive, offer little solace to the mathematically inclined. A rigorous analysis of the refinement module’s capacity to correct for model inaccuracies, alongside a characterization of the conditions under which such correction is possible, would elevate this work beyond a practical solution to a foundational contribution.
Ultimately, the true test lies not in achieving incremental gains on standard benchmarks, but in demonstrating an ability to extrapolate to genuinely novel situations. The pursuit of algorithms that ‘work’ is a pragmatic endeavor; the pursuit of algorithms that must work, given certain axioms, is the only path to lasting scientific progress.
Original article: https://arxiv.org/pdf/2601.10471.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Top 10 Coolest Things About Invincible (Mark Grayson)
- Silver Rate Forecast
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- When AI Teams Cheat: Lessons from Human Collusion
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Gold Rate Forecast
2026-01-18 20:59