Author: Denis Avetisyan
Researchers are adapting techniques originally developed for large language models to shed light on the internal workings of Transformer networks used for time series classification.

This review examines the application of mechanistic interpretability methods-including activation patching, causal inference, and sparse autoencoders-to reveal key features and decision pathways within Time Series Transformer models.
Despite the increasing prevalence of transformer models in time series classification, their internal workings remain largely opaque, hindering trust and refinement. This paper, ‘Mechanistic Interpretability for Transformer-based Time Series Classification’, adapts techniques from natural language processing-including activation patching, attention saliency, and sparse autoencoders-to systematically probe the causal structure within these models. Our analysis reveals key attention heads and temporal positions driving accurate classifications, constructing causal graphs of information flow and uncovering interpretable latent features. Ultimately, can these mechanistic insights unlock further performance gains and enable more robust, reliable time series forecasting?
Unveiling Temporal Dynamics: The Pursuit of Interpretable Forecasting
Time Series Transformers have rapidly become state-of-the-art for forecasting and anomaly detection, demonstrating impressive predictive power across diverse datasets. However, this performance often comes at the cost of transparency; these models frequently operate as ‘black boxes’, where the internal logic driving their decisions remains obscure. While achieving high accuracy is paramount, the lack of interpretability presents significant challenges, particularly in critical applications like healthcare or finance where understanding why a prediction was made is as important as the prediction itself. This opacity hinders trust, complicates model debugging, and limits opportunities for refinement – preventing stakeholders from confidently leveraging these powerful tools and potentially masking subtle but important biases within the data or model architecture. Consequently, a growing emphasis is being placed on developing methods to illuminate the inner workings of Time Series Transformers and unlock their full potential.
The dependable deployment of time series transformers in fields like healthcare, finance, and climate modeling necessitates a clear understanding of their predictive reasoning. While these models demonstrate impressive accuracy, their ‘black box’ nature presents a significant obstacle to trust and effective utilization; simply knowing that a prediction is made is insufficient when high-stakes decisions are involved. To ensure responsible application, stakeholders require insight into how a model arrives at a specific forecast, allowing for validation of its logic, identification of potential biases, and ultimately, greater confidence in its recommendations. Without this transparency, errors or unexpected behavior could have substantial consequences, hindering the adoption of powerful, yet opaque, predictive tools.
Existing techniques for analyzing time series forecasts often struggle to identify which specific moments in the past exert the strongest influence on a model’s current predictions. While a model might accurately forecast future values, it typically offers little insight into why that particular forecast was generated; it cannot, for example, highlight a specific event three weeks prior as a key driver. This limitation poses significant challenges, particularly in fields like finance or healthcare, where understanding the reasoning behind a prediction is as important as the prediction itself. Consequently, users are left with limited ability to validate model behavior, diagnose potential biases, or refine the model based on causal factors – effectively treating the model as a black box despite its predictive power.
The limitations of current time series forecasting models necessitate a move towards mechanistic interpretability – a paradigm focused on understanding how a model functions, rather than simply accepting its predictions. This approach moves beyond simply assessing feature importance and instead aims to dissect the internal logic of the model, identifying the precise temporal patterns and relationships that drive its outputs. By reverse-engineering the model’s decision-making process, researchers can pinpoint which specific historical data points are most influential, and how those points interact to generate a forecast. This granular level of understanding isn’t merely academic; it’s essential for building trust in critical applications like financial modeling or medical diagnosis, enabling informed refinement, and ultimately, ensuring responsible deployment of these powerful predictive tools. Such transparency fosters the ability to not only correct errors but also to validate the model’s reasoning against domain expertise, solidifying its reliability and utility.

Dissecting the Causal Fabric: A Mechanistic Lens
Mechanistic Interpretability (MI) distinguishes itself from traditional neural network analysis by focusing on identifying and characterizing the causal relationships within a model, rather than simply observing correlations. This is achieved through techniques that go beyond passive observation of network behavior; MI methods actively intervene on internal activations and measure the resulting effects on the network’s output. By treating neural network components as potential causal units, MI aims to determine which components are responsible for specific computations and how information flows through the network. This approach contrasts with methods that primarily focus on feature importance or attention weights, which can indicate correlation but not necessarily causation. The goal is to build a comprehensive understanding of how a neural network arrives at a decision, not just what decision it makes.
Traditional methods of interpreting neural networks, such as analyzing attention weights via Attention Saliency, are largely observational; they indicate correlation but not causation. Mechanistic Interpretability (MI) distinguishes itself by employing interventional techniques that directly manipulate internal activations. Rather than passively noting which inputs the network focuses on, MI methods actively alter these activations and measure the resulting changes in output. This allows researchers to determine if a particular activation genuinely causes a specific outcome, providing a stronger understanding of the network’s functional components and their relationships, and moving beyond simply identifying which features are associated with a decision.
Activation Patching operates by systematically replacing activations within a neural network processing a ‘corrupt’ input with corresponding activations obtained from a ‘clean’ input. This intervention allows researchers to isolate the causal effect of specific network components; if replacing a corrupted activation with a clean one restores the original, correct output, it indicates that the replaced component was causally responsible for the error. The magnitude of this restoration serves as a quantitative measure of causal influence, enabling the construction of a causal model of the network’s internal computations. This differs from simple ablation, as it preserves the rest of the forward pass and measures the effect of a component, rather than simply its presence or absence.
Causal Graph construction via Activation Patching facilitates the visualization of information flow within a neural network by identifying which internal components are responsible for specific predictions. Empirical results demonstrate the efficacy of this approach; in instances where a model misclassifies an input, reconstructing the prediction via causal intervention-specifically, by patching activations-has achieved up to 0.89 of the true-class probability that the model should have predicted. This indicates a significant ability to not only diagnose the source of error within the network, but also to recover the correct prediction by manipulating identified causal pathways.

Pinpointing Temporal Influence: A Granular Approach
Activation patching techniques offer flexibility in their application, ranging from coarse-grained layer-level interventions to highly specific position-level manipulations. Layer-level patching disables all activations within a given layer of the neural network, effectively removing its contribution to the output. Head-level patching refines this by targeting individual attention heads within a layer, allowing for the isolation of specific attention mechanisms. The most granular approach, position-level patching, disables activations for specific input positions or timesteps, enabling analysis of the model’s reliance on particular input features or sequential data points. This tiered approach provides a spectrum of control for analyzing and modulating model behavior.
Activation Patching, when implemented at varying granularities, facilitates the isolation of predictive influence within a neural network. Layer-Level Patching assesses the contribution of entire layers, while finer-grained approaches like Head-Level and Position-Level Patching pinpoint specific attention heads or input timesteps responsible for particular classifications. This isolation is achieved by systematically masking or intervening on these components and observing the resulting change in model output; significant deviations indicate a strong influence of the masked component on the prediction. This allows for precise identification of the network’s reliance on specific features or temporal data points during inference.
Systematic application of Activation Patching at varying granularities – layer, head, and position – facilitates the identification of critical components within a model responsible for specific classifications. This involves selectively ablating or masking attention heads and/or time steps, and then observing the resulting impact on model performance. Statistically significant decreases in accuracy following the removal of a particular head or time step indicate its importance for that classification task. By quantifying these performance changes across different heads and time steps, researchers can establish a profile of which components contribute most strongly to the model’s predictions, offering insights into the model’s internal reasoning process and potential areas for optimization.
Evaluation of Activation Patching techniques was performed using the Japanese Vowels Dataset, resulting in a Test Accuracy of 97.57%. This dataset provides a standardized and reproducible environment for assessing the efficacy of interventions at varying granularities – layer, head, and position levels. The achieved accuracy demonstrates the potential of these methods for targeted model analysis and intervention, while the dataset serves as a benchmark for comparing and validating future research in temporal influence mapping and model interpretability.

Disentangling Learned Representations: Unveiling Temporal Motifs
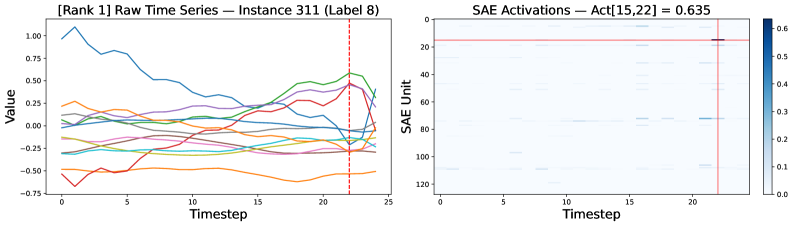
The integration of Sparse Autoencoders with Mutual Information (MI) offers a powerful technique for dissecting the complex internal representations developed by Time Series Transformers. These autoencoders don’t simply compress data; they enforce sparsity, compelling the model to learn a concise code representing the most salient features within the time series. When coupled with MI, this approach goes further, revealing which learned features are statistically independent and therefore represent disentangled aspects of the underlying data. Essentially, the model isn’t just identifying patterns, it’s discovering the fundamental, independent temporal motifs that compose those patterns. This process allows researchers to move beyond observing what the model predicts to understanding how it arrives at those predictions, ultimately unveiling a more transparent and interpretable representation of the learned time series dynamics.
The internal workings of complex time series models, such as the Transformer, often remain opaque, hindering both trust and refinement. However, by applying sparse autoencoders, researchers are able to distill these internal activations into a concise, sparse code – a representation that highlights only the most salient features. This process effectively uncovers recurring patterns, known as temporal motifs, within the model’s learned representations. These motifs aren’t simply correlations in the data; they represent fundamental, repeating processes the model itself has identified as important. Consequently, analysis of these sparse codes provides a window into the model’s ‘reasoning’ – revealing how it processes time-dependent information and, crucially, what aspects of the data it deems most predictive. This allows for a deeper understanding of the learned features and opens possibilities for targeted interventions to improve model performance and generalization capabilities.
The integration of sparse autoencoders with time series transformers offers a pathway to pinpoint the specific internal features driving individual predictions, thereby enhancing model interpretability. By isolating the most relevant activations, this approach moves beyond a “black box” understanding, revealing why a model arrived at a particular conclusion. This transparency is crucial for building trust in artificial intelligence systems, particularly in applications where accountability is paramount. The ability to trace predictions back to specific, understandable features not only facilitates debugging and refinement, but also allows for verification of the model’s reasoning – confirming whether it’s relying on meaningful signals or spurious correlations within the data. Ultimately, a model whose internal logic can be readily understood is more likely to be accepted and effectively utilized.
The capacity to pinpoint and comprehend the internal features learned by a Time Series Transformer holds significant promise for both enhancing model performance and broadening its applicability. By discerning which features contribute most effectively to accurate predictions, researchers can strategically refine the model’s architecture and training data, leading to improved generalization capabilities on unseen data. This targeted refinement moves beyond simply optimizing overall accuracy; it enables the model to adapt more readily to subtle shifts in data distribution or entirely novel scenarios. Consequently, a deeper understanding of these learned features fosters not only more robust predictive power, but also the potential to tailor the model’s behavior for specific tasks or domains, unlocking a new level of control and efficiency in time series analysis.
The pursuit of understanding complex systems benefits from rigorous dissection. This work, adapting Mechanistic Interpretability from natural language processing to Time Series Transformers, exemplifies that principle. The researchers didn’t simply accept the model’s performance; they sought to illuminate the internal mechanisms driving its decisions. This aligns with Gauss’s sentiment: “If I have seen further it is by standing on the shoulders of giants.” The application of established techniques-the ‘shoulders’-to a new domain allows for deeper insight than would be possible through isolated exploration. The focus on revealing causal pathways and latent features underscores the value of reducing complexity to its essential components, a practice that mirrors the elegance Gauss championed.
What’s Next?
The successful translation of Mechanistic Interpretability techniques to time series data, as demonstrated, is less a breakthrough and more a necessary correction. The field labored under the assumption that complexity equated to capability, building opaque systems and then scrambling for post-hoc explanations. It appears the models weren’t fundamentally different – merely arranged in a less familiar dimension. The true challenge now isn’t explaining what these transformers do, but accepting how little they need to do it. Sparse autoencoders and attention saliency are tools, not revelations.
Future work will inevitably focus on refining these tools. But a more fruitful avenue lies in deliberate reduction. Can models be constructed from the outset with interpretability as a primary constraint, rather than an afterthought? The pursuit of minimal sufficient mechanisms – the smallest network capable of a given task – should eclipse the quest for ever-larger parameter counts.
The ultimate test won’t be achieving higher accuracy, but establishing causal provenance. Not simply identifying correlations within the model, but demonstrating a direct line from input feature to output decision, mediated by clearly defined internal pathways. Only then can one claim genuine understanding, and perhaps, a degree of trust. The elegance of a solution is not measured by its intricacy, but by the things it leaves out.
Original article: https://arxiv.org/pdf/2511.21514.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Top 10 Coolest Things About Jared Leto
2025-11-28 07:53