Author: Denis Avetisyan
A new method reveals high-level patterns in graph data by analyzing reordered adjacency matrices and simplifying common motifs.
This review introduces Ring Motifs, a technique for detecting and visualizing ‘noisy’ graph patterns via matrix reordering and Moran’s II statistic.
Discovering meaningful high-level structure within complex relational data remains a persistent challenge due to computational limitations and inherent noise. This paper, ‘Noisy Graph Patterns via Ordered Matrices’, addresses this by introducing a novel framework for defining and detecting ‘noisy’ graph patterns through optimal matrix reordering using Moran’s $I$. By representing graphs as adjacency matrices and permitting controlled noise levels, the approach efficiently decomposes matrices into discernible patterns and visualizes them with a new motif simplification technique. Could this method unlock more robust and interpretable graph analyses across diverse real-world networks?
The Illusion of Complexity: Beyond Complete Connections
Conventional graph analysis frequently centers on the identification of complete subgraphs – known as cliques – where every node is directly connected to every other node within the group. However, this rigid requirement for completeness proves largely impractical when applied to real-world networks, which are seldom so neatly organized. Social networks, biological systems, and even the internet are characterized by incomplete connections, missing links, and inherent ‘noise’ that disrupt the formation of perfect cliques. Consequently, a strict reliance on clique detection often misses crucial patterns and obscures the underlying structure of these complex systems, leading to an incomplete understanding of their organization and function. The prevalence of imperfect connections necessitates analytical approaches that can move beyond the search for ideal, but rare, formations.
Many conventional graph analysis techniques prioritize the identification of fully connected subgraphs, such as cliques, as indicators of meaningful network structure. However, real-world networks are rarely so pristine; they are often characterized by missing connections, errors in data collection, or inherent incompleteness. This rigidity consequently causes these methods to overlook substantial patterns that, while not perfect, still reveal crucial insights into how a network is organized. These imperfect structures-partially connected motifs, near-cliques, or loosely defined communities-can indicate functional groupings, influential nodes, or emergent properties that a strict adherence to complete subgraphs would miss. Recognizing and interpreting these ‘noisy’ patterns is essential for a more nuanced understanding of complex systems, as they often represent the predominant form of organization in naturally occurring networks.
Real-world networks are rarely pristine; they are characterized by missing connections, errors in data collection, and inherent randomness – a condition often described as ‘noise’. Consequently, identifying meaningful patterns within these complex systems demands analytical techniques that move beyond the search for perfect, complete structures. These new methods focus on probabilistic approaches and statistical inference to tease out genuine signals obscured by the noise. Rather than dismissing imperfect subgraphs, these techniques assign probabilities to connections, allowing for the detection of motifs and communities that are statistically significant, even if not fully connected. This shift enables researchers to uncover hidden organizational principles and functional roles within networks that would otherwise remain invisible, offering a more nuanced and accurate understanding of their underlying structure and dynamics.
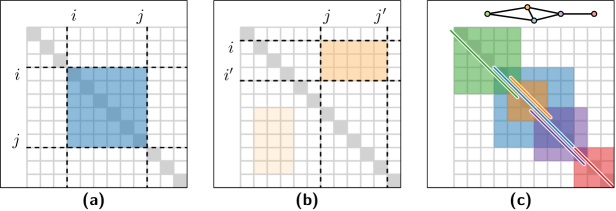
A network’s architecture, regardless of complexity, begins to reveal itself through the adjacency matrix – a square matrix where each row and column represents a node, and a value at the intersection indicates the presence or absence of a connection. This seemingly simple representation is foundational because it transforms a graph’s visual structure into a quantifiable, mathematical form. The matrix doesn’t merely list connections; it encodes the entire network topology, allowing computational algorithms to systematically search for patterns – from tightly knit groups to outlying nodes. Crucially, this matrix-based approach allows for the detection of patterns even within incomplete or ‘noisy’ networks, where connections may be missing or unreliable, paving the way for more robust and realistic network analysis. A_{ij} = 1 if a connection exists between node i and node j, and 0 otherwise, effectively providing a digital fingerprint of the network’s relationships.

Beyond Perfection: Embracing Imperfect Patterns
Pattern enumeration begins with a systematic scan of the adjacency matrix to identify potential subgraphs, differing from traditional methods which primarily focus on perfect cliques and bicliques. This process does not require complete connectivity within a potential pattern; instead, it considers all combinations of nodes and edges based on defined parameters, such as pattern size and allowable deviations. The enumeration procedure generates a comprehensive set of candidate patterns, including those with minor imperfections or incomplete connections, before any filtering or selection takes place. This exhaustive search allows for the detection of potentially valuable, but non-ideal, network motifs that might be missed by algorithms strictly limited to perfect structures.
Following the enumeration of potential patterns, a selection method is implemented to identify the most representative and disjoint structures. This process prioritizes patterns based on their prevalence and non-redundancy within the adjacency matrix. Disjoint patterns are favored to avoid over-representation of highly similar structures, ensuring the selected set captures a diverse range of network motifs. The selection criteria aim to maximize the coverage of the graph while minimizing the overlap between identified patterns, ultimately yielding a concise and informative representation of the underlying network organization.
The methodology employed is not limited to identifying only perfect, strictly defined graph patterns. Instead, it inherently allows for the inclusion of ‘noisy’ patterns, defined as those exhibiting minor deviations from ideal structures. This accommodation of imperfect matches is achieved through the enumeration process, which does not require absolute conformance to a pattern’s defining characteristics. By considering patterns with slight variations, the system demonstrates increased robustness to data imperfections and naturally occurring irregularities within the network, effectively identifying meaningful structures even in the presence of incomplete or inaccurate data.
The identification of maximal disjoint patterns within a network prioritizes structures that are both unique and non-overlapping. A ‘maximal’ pattern cannot be extended by adding further nodes without violating the pattern’s defining relationships; a ‘disjoint’ pattern shares no nodes with any other selected pattern. This selection criterion avoids redundant representation of similar network features and ensures that each identified pattern contributes distinct information about the underlying network topology. By focusing on these characteristics, the method effectively distills the network into a set of the most informative and independent structural components, improving the efficiency and interpretability of the analysis.

Visualizing the Nuances: Encoding Imperfection in Ring Motifs
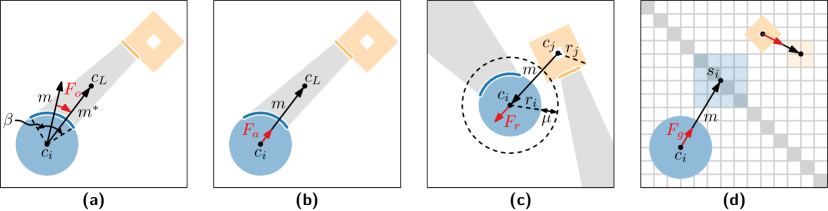
The Ring Motif Simplification technique generates visual representations of frequently occurring subgraphs, known as motifs, within a larger network. This is achieved by identifying instances of a specific motif and then abstracting each instance into a single glyph, or ‘ring’. The position of each ring within the visualization corresponds to its location within the original network, and the rings are arranged to display the relationships between identified motif occurrences. The size and visual characteristics of the rings can be further modulated to represent additional data associated with each motif instance, such as frequency or statistical significance. This allows analysts to quickly identify and compare the prevalence and context of different graph patterns.
The Ring Motif Simplification technique differentiates itself from standard graph visualization methods by explicitly representing the degree of imperfection within identified patterns. Rather than solely indicating the presence or absence of a motif, the glyphs generated by this technique encode noise levels-variations from the ideal pattern-through visual attributes such as color intensity, size, or shape distortion. This encoding allows users to directly assess the robustness of detected motifs and quantify the prevalence of near-matches within the network. The resulting glyphs, therefore, provide a nuanced representation of pattern occurrences, distinguishing between strong, reliable matches and weaker, more ambiguous instances affected by noise or incomplete data.
Glyph arrangement within the Ring Motif Simplification utilizes a force-directed layout algorithm to visually represent network structure and inter-pattern relationships. This iterative process simulates repulsive forces between glyphs representing distinct patterns and attractive forces between glyphs representing connected patterns. The implementation achieves a processing rate exceeding 1000 iterations per second, enabling real-time visualization of large and complex networks. This high iteration rate facilitates the stabilization of the layout, minimizing overlap and maximizing the clarity of connections, thereby revealing both the overall network topology and the relative proximity of identified motifs.
The Ring Motif Simplification technique facilitates network exploration by visually representing not only frequently occurring, exact patterns, but also the abundance of imperfect matches and their associated connection strengths. By encoding noise levels directly into the glyphs, the method reveals the presence of weak or partial connections that would be obscured by techniques focused solely on perfect pattern identification. This allows analysts to assess the overall network structure, identifying both robust, highly connected motifs and more fragile, less prevalent patterns, thereby providing a more comprehensive understanding of the underlying relationships within complex datasets.
Beyond Observation: Revealing Hidden Structures in Complex Systems
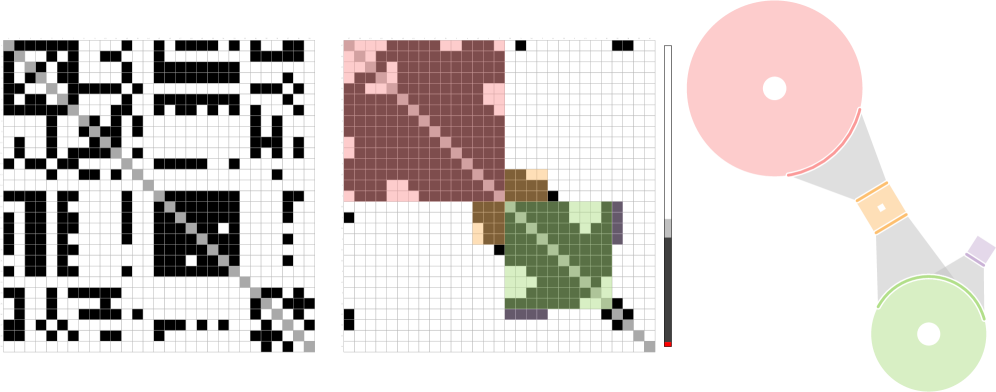
Analysis of functional magnetic resonance imaging (fMRI) data, specifically the FLT dataset representing patterns of brain connectivity, has yielded novel insights into neural communication. This method doesn’t merely confirm established pathways; it uncovers previously obscured, subtle relationships between brain regions. By identifying statistically significant, repeating patterns within the complex web of neural activity, researchers can now observe communication structures that were previously hidden by the sheer volume of data and the limitations of traditional analytical techniques. These newly revealed patterns suggest a more nuanced understanding of how different areas of the brain collaborate during cognitive tasks and offer potential avenues for exploring neurological disorders linked to disrupted connectivity.
The study of the ZKC dataset, representing the social network within a karate club, revealed the power of this approach to dissect complex relationships. Researchers successfully identified distinct subgroups within the club, not simply as isolated entities, but with detailed mapping of connections within each group. This wasn’t merely a division of members; the analysis pinpointed individuals serving as key connectors, those bridging different subgroups, and even those relatively isolated, offering insights into the club’s internal dynamics and potential fault lines. This granular understanding of the ZKC network demonstrates the method’s capacity to move beyond simple network visualization, unveiling the underlying architecture of social cohesion and fragmentation.
Analysis of the SCH dataset, which meticulously records social interactions among primary school children, reveals compelling insights into the dynamics of friendship and exclusion. The methodology successfully identified cohesive subgroups within the school, demonstrating not only who interacts with whom, but also the strength and frequency of those interactions. Critically, the approach highlighted children who consistently occupied peripheral positions within these networks, potentially indicating social isolation or a lack of integration into established peer groups. This ability to pinpoint patterns of inclusion and exclusion offers a valuable tool for understanding social development and identifying students who may benefit from targeted interventions, moving beyond simple observation to quantifiable network analysis.
A key strength of this analytical pipeline lies in its computational efficiency. The entire process, from initial pattern enumeration across the network to the selection of the most significant configurations, completes in under one second when executed on standard laptop hardware. This rapid processing time is crucial for applying the method to large and complex datasets, and it distinguishes this approach from many existing network analysis techniques that require substantial computational resources or lengthy processing times. The demonstrated scalability opens possibilities for real-time analysis and interactive exploration of network structures, ultimately making sophisticated network discovery accessible to a broader range of researchers and applications.
The consistent performance of this analytical pipeline across markedly different datasets – ranging from the intricate wiring of functional brain connectivity to the dynamics of human social groups in both a karate club and a primary school – underscores its broad applicability. This isn’t merely a tool tailored to a specific network type; instead, it reveals a capacity to identify underlying structural patterns regardless of the system being examined. The ability to consistently detect previously obscured subgroups, communication pathways, or instances of inclusion and exclusion suggests a powerful, generalizable method for network analysis with potential implications for fields as diverse as neuroscience, sociology, and computer science. This robustness confirms the approach isn’t reliant on specific dataset characteristics, but rather on fundamental principles of network organization, opening avenues for discovery across a wide spectrum of complex systems.
Toward Efficient Discovery: Optimizing Networks with Matrix Reordering
To improve computational efficiency, the adjacency matrix representing network connections undergoes a strategic reordering process. This technique leverages Moran’s II, a spatial autocorrelation statistic, to assess the relatedness of network nodes. Nodes demonstrating strong connections, or high spatial autocorrelation, are positioned closer together within the matrix. This rearrangement minimizes the distances between frequently accessed data points, thereby reducing the computational burden during pattern discovery. By physically grouping related information, the algorithm streamlines data retrieval and accelerates the identification of significant network patterns, ultimately enhancing the speed and scalability of complex network analysis.
The identification of meaningful patterns within complex networks relies heavily on efficient data organization, and this is achieved through a sophisticated matrix reordering process. Utilizing the Concorde Traveling Salesperson Problem (TSP) Solver, accessed remotely through the Network Enabled Optimization Server (NEOS), the adjacency matrix representing network connections undergoes a transformation designed to cluster related nodes. This optimization isn’t simply about rearrangement; it strategically minimizes the distance between interconnected elements, effectively creating a more coherent and navigable data structure. By resolving the TSP – finding the shortest route to visit all nodes – Concorde provides an ordering that dramatically improves the performance of subsequent pattern discovery algorithms, allowing for faster and more accurate identification of significant relationships within the network.
The reordering of adjacency matrices, a crucial step in optimizing pattern discovery, is completed with notable efficiency thanks to the integration of the Concorde TSP Solver, accessed remotely through the Network Enabled Optimization Server (NEOS). Utilizing this computational resource, the process achieves completion in approximately 20 seconds when applied to the SCH instances – complex network examples used for benchmarking. This rapid reordering brings related nodes into closer proximity within the matrix, significantly reducing the computational burden of subsequent pattern enumeration and accelerating the identification of meaningful relationships within large-scale networks.
Preprocessing the adjacency matrix is a critical step in streamlining the pattern discovery process, fundamentally reducing computational demands. By strategically rearranging the matrix – bringing closely related nodes into proximity – the algorithm minimizes the search space required to identify significant patterns. This optimization doesn’t alter the network’s underlying structure, but rather presents the data in a more computationally accessible format. Consequently, the time needed for both enumerating potential patterns and selecting the most relevant ones is substantially decreased, enabling analysis of larger and more complex networks than previously feasible. This approach allows researchers to focus on interpreting results rather than being limited by computational bottlenecks, ultimately accelerating the pace of discovery within complex systems.
The refined framework establishes a powerful platform for investigating networks of previously unattainable scales, promising breakthroughs in diverse fields. By efficiently organizing network data, researchers can now probe complex systems-ranging from social interactions and biological pathways to infrastructure dependencies and financial markets-with unprecedented speed and detail. This capability facilitates the identification of subtle, previously obscured relationships, potentially revealing emergent properties and critical vulnerabilities within these networks. Consequently, the methodology not only accelerates pattern discovery but also broadens the scope of inquiry, enabling a more comprehensive understanding of the intricate connections that govern complex phenomena.
The pursuit of clarity within complex systems defines the work presented. This paper addresses the inherent noise obscuring underlying structures in graph data, a challenge remarkably akin to distilling signal from interference. As Vinton Cerf observed, “The Internet treats everyone the same.” This seemingly simple statement reflects the core principle of the approach: reducing complexity by focusing on fundamental patterns. By reordering adjacency matrices and employing Ring Motifs, the research seeks to reveal these underlying structures-to treat all graph elements equally in the search for meaningful connectivity, much like the Internet’s egalitarian architecture. The simplification achieved through this method mirrors a striving for elegant, accessible design, removing layers of obfuscation to expose the essential form.
Where To From Here?
The pursuit of signal within graph noise is rarely finished. This work offers a means to decompose complex structures, but decomposition itself reveals further layers. Ring Motifs, as presented, are a simplification-a necessary reduction. Abstractions age, principles don’t. The true challenge isn’t simply finding patterns, but establishing a rigorous framework for their comparative importance.
Current implementations rely on matrix reordering and Moran’s II-tools with inherent limitations. Future work should explore alternatives, potentially incorporating information theory or topological data analysis. Every complexity needs an alibi. A key question remains: how do these ‘noisy’ patterns generalize across different graph types and scales? Are they merely artifacts of specific network construction, or do they reflect fundamental organizational principles?
Visualization, while useful, remains largely exploratory. A compelling next step involves integrating this pattern detection with predictive modeling. Can identified motifs be used to anticipate graph evolution, or to classify network function? The utility of simplification lies not in aesthetic clarity, but in demonstrable predictive power.
Original article: https://arxiv.org/pdf/2601.11171.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Silver Rate Forecast
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Top 10 Coolest Things About Invincible (Mark Grayson)
- When AI Teams Cheat: Lessons from Human Collusion
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Unmasking falsehoods: A New Approach to AI Truthfulness
2026-01-20 08:25