Author: Denis Avetisyan
A new framework combines generative AI and robust reinforcement learning to deliver more profitable and resilient financial trading strategies in unpredictable economic climates.
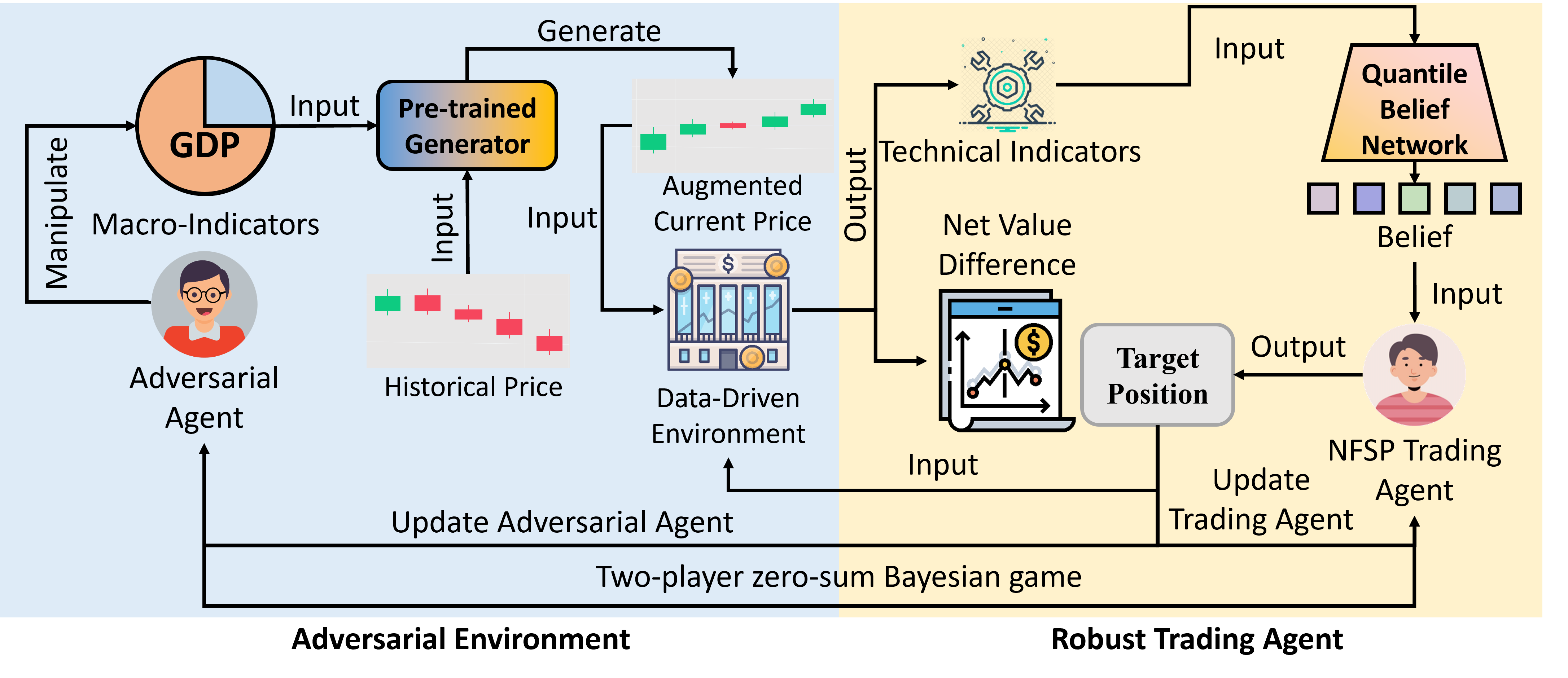
This paper introduces a macro-conditioned generative model coupled with adversarial reinforcement learning for robust financial trading with synthetic data.
Despite strong performance in controlled environments, algorithmic trading strategies often falter when confronted with the dynamic and unpredictable nature of real-world financial markets. This paper, ‘Bayesian Robust Financial Trading with Adversarial Synthetic Market Data’, addresses this limitation by introducing a novel framework that combines a macro-conditioned generative model with robust reinforcement learning. Our approach achieves higher profitability and reduced risk by training agents against an adversarial simulator that mimics shifting macroeconomic regimes, effectively learning to navigate uncertainty. Could this methodology pave the way for more resilient and adaptive trading systems capable of thriving in increasingly volatile global markets?
Navigating Uncertainty: The Fragility of Conventional Trading Systems
Quantitative trading systems, historically built upon the analysis of past market behavior, face significant challenges when confronted with novel or deliberately disruptive conditions. These strategies often extrapolate patterns from historical datasets, assuming a degree of stationarity – that future market dynamics will resemble the past. However, unforeseen economic shocks, geopolitical events, or even the intentional manipulation of market variables can render these historical relationships unreliable. Furthermore, sophisticated actors may exploit the known vulnerabilities of these data-driven systems through adversarial machine learning, crafting inputs designed to trigger erroneous trades or degrade performance. This inherent reliance on the past, therefore, creates a systemic risk, demanding more adaptable and robust methodologies capable of navigating an increasingly unpredictable financial landscape.
Financial markets are no longer characterized by stationary distributions, a fundamental assumption underlying many traditional quantitative strategies. Increasing interconnectedness, the proliferation of high-frequency trading, and the emergence of novel financial instruments contribute to a constantly evolving landscape. Consequently, models must move beyond simple extrapolation of past performance and embrace adaptive learning techniques. Robustness, in this context, isn’t merely about minimizing losses during downturns, but about maintaining consistent performance across a spectrum of previously unseen market regimes. This necessitates incorporating mechanisms for real-time recalibration, exploring non-parametric methods less reliant on strict distributional assumptions, and potentially leveraging techniques from game theory to anticipate and respond to the strategic actions of other market participants. The ability of a model to gracefully degrade, rather than catastrophically fail, under stress is becoming paramount for sustained success.
Current quantitative trading methodologies frequently falter when confronted with genuine market dynamism because they largely presume a static environment. These models are typically built on the assumption that future market behavior will mirror past patterns, a premise invalidated by the inherent unpredictability of financial systems and the increasingly sophisticated actions of other traders. The failure to incorporate game-theoretic considerations – acknowledging that market participants actively respond to and attempt to exploit perceived strategies – results in models vulnerable to manipulation and suboptimal returns, particularly during periods of heightened volatility. This limitation isn’t simply a matter of statistical error; it reflects a fundamental disconnect between the simplifying assumptions of many algorithms and the complex, interactive reality of financial markets, where strategic behavior by competitors can swiftly render even the most rigorously backtested strategies ineffective.
Reinforcement Learning: Building Agents Resilient to Disruption
Robust Reinforcement Learning (Robust RL) represents a significant departure from traditional Reinforcement Learning by incorporating explicit modeling of environmental uncertainty and potential disturbances. Standard RL algorithms typically assume a perfectly known environment, a simplification that limits their performance in real-world applications subject to noise, unexpected events, or adversarial manipulation. Robust RL addresses this limitation by formulating the learning problem with the explicit goal of achieving optimal performance even under the worst-case realization of these uncertainties. This is achieved through modifications to both the state and action spaces, as well as the reward function, to account for the range of possible disturbances. By proactively considering these adverse conditions during training, Robust RL agents develop policies that are demonstrably more resilient and reliable than those produced by conventional RL methods when deployed in unpredictable environments.
A Robust Markov Decision Process (RMP) extends the standard Markov Decision Process framework by explicitly incorporating uncertainty in the transition dynamics and reward function. Instead of assuming a single, deterministic outcome for each action, the RMP considers a set of possible outcomes, defined by an uncertainty set. This allows the agent to optimize its policy not for the expected outcome, but for the worst-case scenario within that uncertainty set. Formally, the RMP defines a distribution over possible environments, and the agent seeks a policy that maximizes the minimum expected return across all environments within the defined set. This approach guarantees a level of performance even under significant environmental disturbances, providing resilience to unforeseen or adversarial conditions.
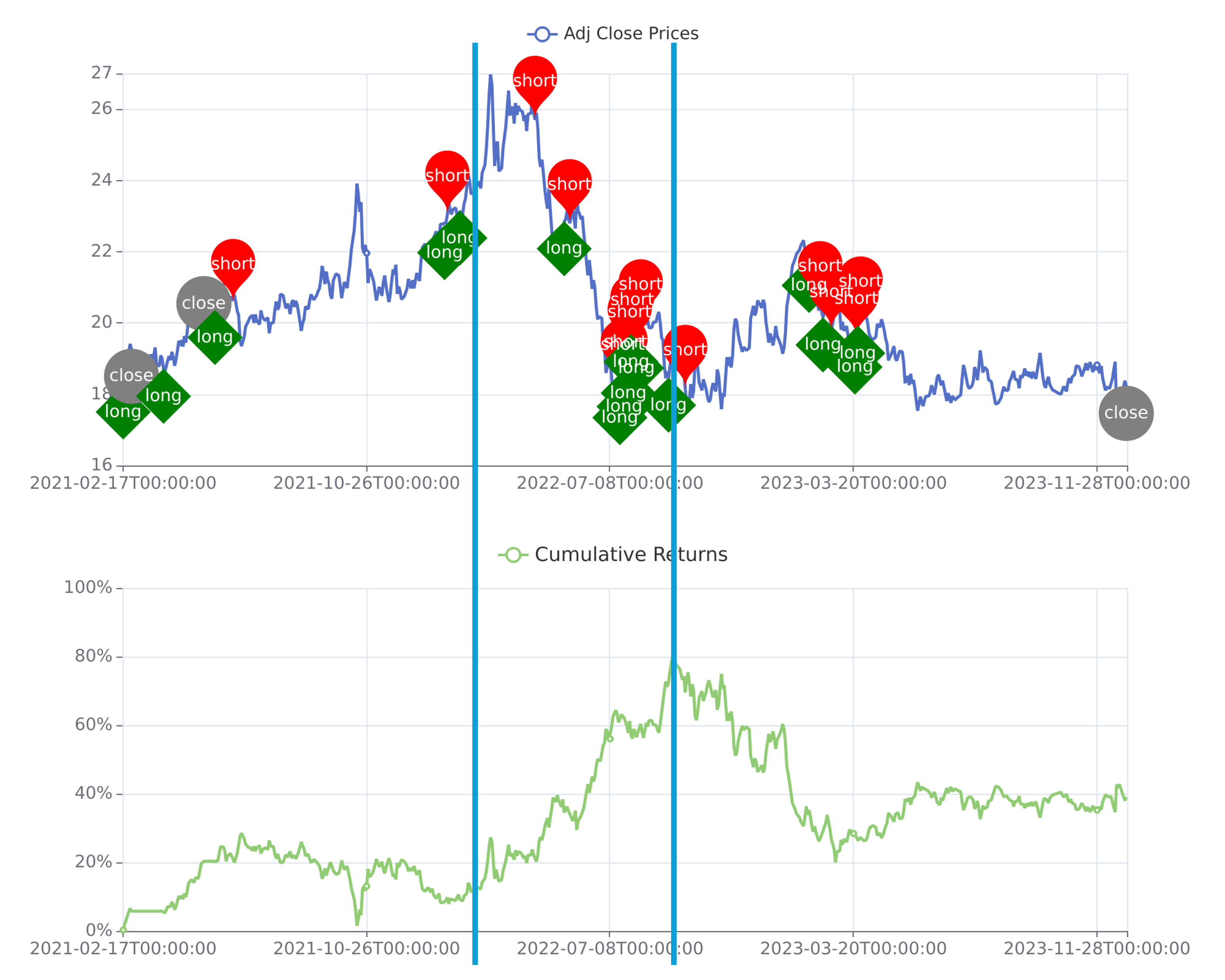
The implementation of Robust Reinforcement Learning (Robust RL) prioritizes the creation of agents designed to withstand and neutralize adversarial attacks within a trading environment. This capability is achieved by training agents to anticipate and mitigate malicious inputs intended to disrupt optimal performance. Empirical testing demonstrates that trading systems built with Robust RL consistently outperform baseline reinforcement learning methods when evaluated across nine Exchange Traded Funds (ETFs). This superior performance indicates an increased stability and reliability in trading strategies when subjected to potentially disruptive forces, validating the effectiveness of adversarial robustness as a key design principle.
Simulating the Crucible: Adversarial Agents and Market Dynamics
The Adversarial Agent is a core element of our testing methodology, functioning as a dynamic counterparty designed to introduce strategic disturbances into the simulated market environment. This agent doesn’t operate randomly; instead, it actively seeks to identify and exploit vulnerabilities in the trading agent’s strategies. By intentionally perturbing market conditions – including price fluctuations, order book imbalances, and liquidity – the Adversarial Agent forces the trading agent to adapt and demonstrate its resilience under stress. The agent’s actions are governed by a defined objective function focused on maximizing the impact on the trading agent’s performance, allowing for a quantifiable assessment of robustness beyond standard backtesting procedures.
The Adversarial Agent is implemented within a Bayesian Game framework to model the strategic interaction between the trading agent and the adversary, accounting for incomplete information availability to both parties. This framework defines a game structure where each agent possesses private information – the adversary regarding its perturbation strategies and the trading agent regarding its internal state and risk assessment – and acts to maximize its own utility. The Bayesian aspect necessitates that each agent maintains probability distributions over the possible private information of the other, updating these beliefs based on observed actions. This allows for the modeling of rational, yet uncertain, behavior from both the trading agent and the adversary, enabling a more robust evaluation of the trading agent’s performance under conditions of strategic market pressure. The resulting game provides a mathematically rigorous method for analyzing the equilibrium strategies of both agents, and quantifying the impact of adversarial actions on trading outcomes.
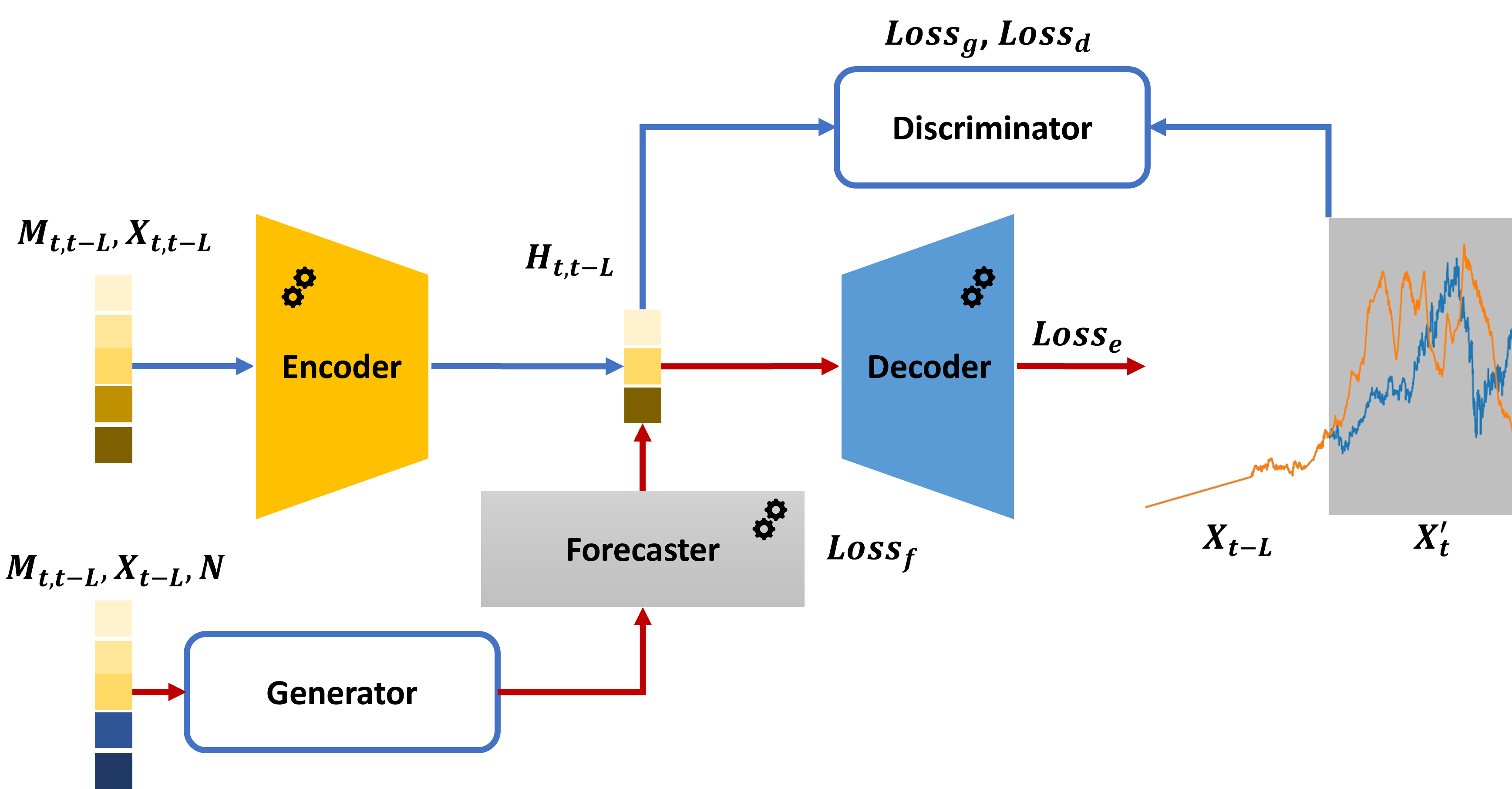
The Market Data Generator employed in this simulation incorporates both macroeconomic indicators and temporal dependencies to produce realistic market data. This generator models the interrelationships between various financial features and macroeconomic factors, minimizing the difference in Feature-Macro Correlation – a metric used to assess the alignment between generated and real-world data – as compared to alternative data generation methods. Specifically, the generator utilizes time-series modeling to capture the auto-correlation and seasonality present in financial data, and integrates key macroeconomic indicators such as GDP growth, inflation rates, and unemployment figures. This approach ensures the simulated market environment accurately reflects the complex interplay of factors influencing real-world market behavior, providing a robust testing ground for trading strategies.
Modeling Uncertainty: Belief Networks and Stable Policies
A Quantile Belief Network (QBN) is utilized to model the probability distribution of market states, moving beyond simple point estimates of future conditions. The QBN predicts multiple quantiles of the distribution, allowing for a representation of uncertainty that captures not only the most likely outcome, but also the range of plausible scenarios and their associated probabilities. This approach contrasts with methods that provide only a single expected value, offering a more nuanced understanding of potential market behavior. Specifically, the QBN estimates the α-quantile, representing the value below which α proportion of the probability mass resides, for a range of α values. This granular representation enables a more robust assessment of risk and opportunity, and informs decision-making under uncertainty.
Bayesian Neural Fictitious Self-Play (BNFSP) integrates Bayesian methods into the fictitious self-play algorithm to address the challenges of learning stable policies in uncertain environments. Traditional fictitious self-play iteratively refines a strategy by assuming opponents play a best response to the historical distribution of actions. BNFSP extends this by representing the opponent’s strategy as a probability distribution, modeled using a Bayesian neural network. This allows the agent to quantify uncertainty about the opponent’s strategy and learn a policy that is robust to a range of possible opponent behaviors. By maintaining a distribution over opponent strategies, rather than a single point estimate, the agent avoids overfitting to historical data and achieves more stable learning, particularly in non-stationary environments where opponent behavior may change over time.
The agent’s adaptive strategy, informed by its modeled beliefs regarding opponent actions, results in demonstrable performance improvements in simulated trading scenarios. Empirical evaluation across nine Exchange Traded Funds (ETFs) indicates consistent gains in key risk-adjusted return metrics; specifically, the framework achieves statistically significant improvements in Sharpe Ratios and concurrent reductions in Maximum Drawdown values. This suggests that incorporating beliefs about adversarial behavior allows for the development of trading strategies that are both more profitable and more robust to unfavorable market conditions, relative to strategies employing static or less informed approaches.
Ensuring Integrity and Charting Future Directions
To maintain the integrity of the simulated market environment, a method called Correlation-Weighted Imputation addresses the inevitable presence of missing data points. This technique doesn’t simply replace missing values with averages; instead, it leverages the established relationships between different market variables. By analyzing the correlations between assets, the imputation process intelligently estimates missing data based on the observed behavior of related instruments. This ensures that the simulation remains statistically consistent and avoids introducing artificial distortions, ultimately bolstering the reliability of the agent’s training and the validity of the resulting quantitative trading strategies. The approach is crucial for creating a robust and realistic financial model capable of accurately reflecting complex market dynamics.
The agent’s capacity to navigate complex market conditions is significantly bolstered by the implementation of a Transformer architecture within its state representation. This innovative approach moves beyond traditional recurrent neural networks by allowing the agent to weigh the importance of different historical market signals when making predictions. Unlike methods that process data sequentially, the Transformer architecture facilitates parallel processing, enabling the agent to capture long-range dependencies and nuanced patterns with greater efficiency. Consequently, the agent demonstrates an improved ability to interpret market signals, discern subtle shifts in momentum, and formulate more effective trading strategies, ultimately leading to enhanced responsiveness and potentially higher profitability in dynamic market environments.
The developed framework represents a significant advancement in quantitative trading, offering a foundation for strategies designed to withstand market volatility and generate consistent returns. By accurately capturing the intricacies of market dynamics – as evidenced by demonstrably lower Absolute Returns Autocorrelation Function (AbsReturnsACF) differences – the system provides a more realistic simulation environment for testing and refining algorithmic approaches. This enhanced realism extends beyond simple profit maximization, fostering research into adaptive market modeling where strategies can learn and evolve with changing conditions. Consequently, the work opens avenues for exploration in AI-driven finance, potentially leading to the creation of truly intelligent trading systems capable of navigating complex financial landscapes with increased efficiency and resilience.
The pursuit of resilient financial strategies, as detailed in the study, necessitates a rigorous simplification of complex market dynamics. One strives for clarity amidst the noise of macroeconomic factors and adversarial conditions. This aligns perfectly with Grace Hopper’s sentiment: “It’s easier to ask forgiveness than it is to get permission.” The framework presented embodies this principle by prioritizing a robust, adaptable agent-one that doesn’t require perfect foresight, but rather the ability to learn and recover from unexpected shifts. The generative model, while sophisticated, ultimately serves to create a challenging, yet manageable, environment for honing this adaptability. The emphasis isn’t on predicting the future, but on building a system capable of navigating uncertainty.
What’s Next?
The presented work offers a localized improvement. Profitability, even robust profitability, remains a transient metric. The true challenge lies not in maximizing return within a simulated volatility, but in defining-and surviving-the unsimulated. Future iterations must address the inherent limitations of macroeconomic conditioning. Factors are, by definition, incomplete proxies. The model excels at navigating the known unknowns; the truly dangerous territory remains the unknown unknowns.
A pertinent extension concerns the ontological status of the adversary. Current adversarial training presupposes a rational, profit-maximizing opponent. This is… generous. Market irrationality, driven by behavioral biases and exogenous shocks, represents a more likely threat model. The agent’s resilience to noise, not just sophisticated opposition, demands further investigation.
Ultimately, the pursuit of robustness feels less like engineering and more like applied epistemology. One does not eliminate risk; one merely shifts its distribution. Clarity is the minimum viable kindness. The next step isn’t a more complex model, but a more honest one.
Original article: https://arxiv.org/pdf/2601.17008.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading Smarter: AI-Powered Execution Schedules
2026-01-27 08:54