Author: Denis Avetisyan
Researchers are exploring how large language models can move beyond text generation to effectively plan and execute sequences of actions in challenging, long-horizon tasks.
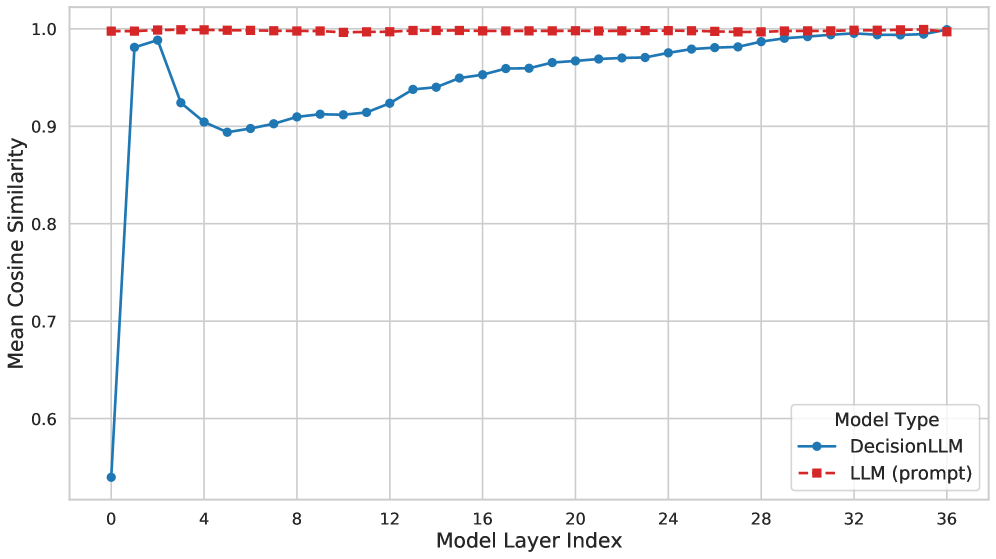
DecisionLLM aligns trajectory data with text, enabling improved performance in offline reinforcement learning and highlighting the impact of data quality and model scale.
Effective long-sequence decision-making remains a challenge despite advances in reinforcement learning. This work, ‘DecisionLLM: Large Language Models for Long Sequence Decision Exploration’, introduces a novel framework leveraging the power of large language models by treating trajectory data as a distinct modality aligned with natural language task descriptions. We demonstrate that this approach enables LLMs to autoregressively predict future decisions, achieving state-of-the-art performance and revealing critical scaling laws dependent on model size, data volume, and data quality. Could this paradigm shift unlock new possibilities for LLMs in complex, dynamic environments like real-time bidding and beyond?
The Illusion of Long-Term Planning
Traditional reinforcement learning algorithms frequently encounter difficulties when tasked with scenarios demanding a sustained chain of actions to achieve a distant reward. This limitation arises from a tendency toward myopic behavior – prioritizing immediate gains over long-term consequences. As an agent learns through trial and error, it often optimizes for rewards received in the near future, struggling to assign sufficient value to actions whose benefits unfold over extended sequences. Consequently, these agents may fail to develop coherent strategies for complex tasks, instead exhibiting erratic or shortsighted behavior that hinders their ability to successfully navigate prolonged challenges. The problem isn’t necessarily an inability to learn, but rather a difficulty in accurately assessing the true value of actions that contribute to goals far down the line, leading to suboptimal performance in tasks requiring foresight and sustained effort.
Effective decision-making across extended timeframes-often termed ‘long-horizon’ tasks-hinges on an agent’s capacity to model the potential repercussions of present actions. This necessitates more than simply reacting to immediate rewards; the agent must internally simulate future states and evaluate the long-term value of different trajectories. Maintaining consistent goals throughout this process is equally crucial, preventing the agent from being sidetracked by short-term gains that ultimately undermine its overarching objectives. The ability to robustly predict and value future outcomes allows for the formulation of plans that extend beyond immediate gratification, enabling successful navigation of complex, temporally-extended challenges where delayed rewards are the norm.
Despite advancements in artificial intelligence, current long-horizon decision-making systems frequently exhibit a significant limitation: a dependence on exhaustive training datasets. These systems, while potentially proficient within narrowly defined parameters, struggle to adapt when confronted with novel situations or environments that deviate from their training data. This lack of generalization stems from an inability to effectively abstract core principles from experience, leading to brittle performance in real-world applications where unpredictability is the norm. Consequently, deploying these agents in dynamic, open-ended scenarios-such as autonomous robotics or complex resource management-remains a substantial challenge, necessitating innovative approaches that prioritize adaptability and efficient learning over sheer data volume.
Offline RL: Trading Exploration for Static Data
Offline Reinforcement Learning (RL) presents a distinct alternative to traditional RL methods by facilitating policy learning directly from pre-collected, static datasets. This approach eliminates the requirement for active environment interaction during the training phase, significantly reducing the computational expense and potential risks associated with online exploration. Datasets utilized in offline RL can originate from various sources, including prior agent experiences, expert demonstrations, or even human-collected data. Consequently, offline RL enables the deployment of learned policies in scenarios where real-time interaction is impractical, costly, or potentially dangerous, such as robotics, healthcare, and financial trading. The efficacy of offline RL is predicated on the quality and representativeness of the static dataset used for training.
Offline Reinforcement Learning frameworks are increasingly incorporating generative models, specifically Diffusion Models and Transformer architectures, to address limitations in data efficiency. These models excel at learning complex data distributions from limited datasets, enabling the creation of synthetic data or improved state-action value estimation. Diffusion Models, through a process of iteratively adding and removing noise, can generate plausible trajectories, augmenting the original dataset and improving policy generalization. Transformer architectures, leveraging attention mechanisms, effectively capture long-range dependencies within sequential data, allowing for better prediction of future states and rewards given historical actions. The integration of these generative models facilitates effective policy learning even when online interaction is impractical or costly, by mitigating the need for extensive exploration and improving the robustness of learned policies to unseen states.
Offline Reinforcement Learning avoids the complexities and potential instability of online exploration by learning policies from pre-collected, static datasets; however, this introduces new challenges related to data distribution and generalization. Since the agent cannot actively gather data, the quality and representativeness of the existing dataset are critical. Performance is highly sensitive to distributional shift – a mismatch between the data the policy is trained on and the states encountered during deployment. Consequently, techniques to assess and mitigate out-of-distribution actions, such as conservative policy optimization and uncertainty estimation, are essential to ensure robust and reliable performance in unseen environments. Effective generalization requires the learned policy to accurately predict optimal actions for states not well-represented in the training data, often necessitating methods for data augmentation or regularization.
DecisionLLM: A Language Model Attempts to Understand Movement
DecisionLLM utilizes a multimodal framework designed for long-sequence decision-making by simultaneously processing both trajectory data – representing sequences of states and actions – and textual prompts. This joint processing allows the model to incorporate both historical behavioral information and high-level instructions into its decision-making process. The framework differs from unimodal approaches by directly leveraging the complementary strengths of continuous trajectory data and discrete language inputs, enabling a more comprehensive understanding of the decision-making context and improved performance in sequential tasks requiring extended planning horizons.
DecisionLLM employs Trajectory Encoding and Alignment to convert continuous state-action sequences into a discrete token format suitable for Large Language Models (LLMs). This process involves discretizing the continuous state and action spaces into a vocabulary of tokens. Specifically, the system learns to map observed states and actions to these tokens, effectively creating a “language” representing the agent’s experience. Alignment is achieved through training, enabling the LLM to interpret the encoded trajectory data as a coherent sequence of events, facilitating reasoning and planning based on past behavior and anticipated outcomes. This tokenization allows the LLM to process trajectory data directly, bypassing the need for specialized recurrent or transformer architectures designed for continuous data.
The framework facilitates reasoning about sequential data by enabling the Large Language Model (LLM) to process past actions and predict potential future outcomes. This capability was validated through performance on the Maze2D and AuctionNet benchmarks; specifically, DecisionLLM achieved a 69.4 point improvement over Decision Transformer on the Maze2D-umaze-v1 environment. Furthermore, the model attained a score of 0.058 on the AuctionNet benchmark, demonstrating its ability to generate coherent, multi-step plans based on integrated trajectory and textual inputs.
The Illusion of Intelligence: Scaling Up, Hoping for the Best
DecisionLLM represents a significant step towards realizing truly intelligent agents capable of navigating complex, real-world scenarios, particularly within the fields of robotics and autonomous driving. By harnessing the power of Large Language Models, the system moves beyond traditional, pre-programmed responses and embraces a more flexible, context-aware approach to decision-making. This allows robotic systems and self-driving vehicles to interpret nuanced situations, understand high-level instructions, and dynamically adjust their actions accordingly – essentially translating natural language commands into concrete operational strategies. The potential extends beyond simple task execution; DecisionLLM facilitates the creation of agents that can reason about unforeseen circumstances, learn from experience, and ultimately exhibit a level of adaptability previously unattainable in automated systems.
DecisionLLM introduces a paradigm shift in agent control through prompt-based decision making, enabling interaction with complex systems via natural language. Rather than relying on intricate code or pre-programmed responses, the agent interprets human instructions expressed as prompts – requests phrased in everyday language – to navigate and respond to dynamic situations. This facilitates intuitive control; a user can, for instance, direct a robotic arm with a simple phrase like “carefully place the object on the shelf,” or guide an autonomous vehicle with “prioritize pedestrian safety and maintain a speed limit of 30 mph.” Crucially, the system’s reliance on Large Language Models allows it to not just execute instructions, but to adapt to unforeseen circumstances and interpret ambiguous prompts, creating a level of flexibility previously unattainable in automated systems and paving the way for truly intelligent, responsive agents.
The trajectory of increasingly sophisticated autonomous agents is firmly linked to the predictable improvements in Large Language Model (LLM) performance, a relationship formalized by observed scaling laws. These laws demonstrate that as LLM parameters and training data increase, capabilities – including complex reasoning and planning – improve systematically and predictably. This suggests that future gains in LLM scale will not simply yield marginal improvements, but will unlock qualitatively new levels of decision-making proficiency in robotic systems and autonomous vehicles. Essentially, a more powerful LLM doesn’t just process information faster; it fundamentally enhances the agent’s ability to understand nuanced situations, anticipate consequences, and formulate effective strategies, paving the way for genuinely intelligent behavior in real-world applications.
The pursuit of scalable decision-making, as demonstrated by DecisionLLM, inevitably invites scrutiny. This framework, treating trajectory data as a modality alongside text, feels less like innovation and more like a temporary reprieve from the inevitable chaos of production. As John McCarthy observed, “It is often easier to explain why something didn’t work than to explain why it did.” DecisionLLM’s reliance on data quality and scaling laws simply acknowledges that even the most elegant architecture will buckle under insufficient or flawed input. Better one well-understood trajectory dataset than a hundred sprawling, poorly aligned ones, it seems. The paper highlights a step forward, but one destined to become tomorrow’s tech debt.
The Road Ahead
DecisionLLM, in its attempt to align trajectories with text, merely shifts the source of future debugging. The bug tracker will not record errors in action selection, but rather, discrepancies between the narrative of a trajectory and its actual execution. It’s a refinement, not a resolution. The promise of scaling laws remains untested at truly production scale – the inevitable collisions with real-world noise, adversarial inputs, and the sheer volume of edge cases will reveal whether these models generalize, or simply memorize increasingly complex failure modes.
The emphasis on data quality is, predictably, the most honest assessment. The framework highlights what everyone eventually learns: garbage in, exquisitely crafted failure. The next iteration won’t be about clever architectures, but relentless data cleaning and augmentation. Expect a proliferation of synthetic environments, meticulously designed to expose every possible weakness. It’s not about teaching the model to decide; it’s about curating a dataset where correct decisions are statistically inevitable.
Ultimately, this work doesn’t solve long-sequence decision-making; it re-frames it as a very expensive pattern-matching problem. The system doesn’t plan; it extrapolates. And, as always, the real challenge won’t be achieving peak performance on a benchmark, but maintaining minimal acceptable performance when everything breaks. The system doesn’t deploy – it lets go.
Original article: https://arxiv.org/pdf/2601.10148.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
- Brent Oil Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-01-16 21:49