Author: Denis Avetisyan
New research explores a method for training large language models to develop robust reasoning skills by rewarding internally consistent thought processes.
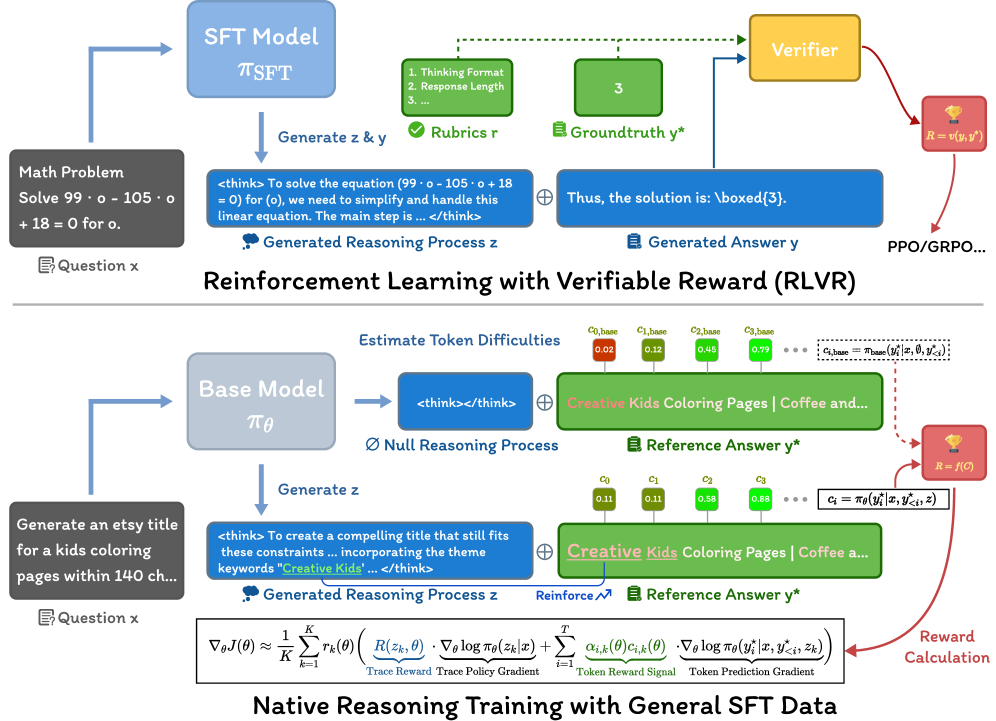
This paper introduces Native Reasoning Training, a framework enabling language models to reason on unverifiable data using intrinsic rewards and eliminating the need for external verification or human annotation.
Current approaches to training large reasoning models are fundamentally constrained by reliance on costly, human-annotated data and objective verifiers, limiting their applicability to a narrow range of tasks. This work, ‘Native Reasoning Models: Training Language Models to Reason on Unverifiable Data’, introduces Native Reasoning Training (NRT), a novel framework that cultivates complex reasoning abilities by intrinsically rewarding models for generating reasoning traces that increase their confidence in correct answers-eliminating the need for external verification. By reframing reasoning as an optimization problem, NRT establishes a self-reinforcing feedback loop and achieves state-of-the-art performance among verifier-free methods on models like Llama and Mistral. Could this approach unlock a new generation of broadly applicable reasoning systems capable of tackling previously intractable, unverifiable challenges?
The Illusion of Understanding: Limits of Pattern Recognition
Contemporary language models frequently demonstrate impressive capabilities by leveraging Supervised Fine-Tuning (SFT) to identify and replicate patterns within vast datasets. This approach allows them to generate text that appears insightful, often mimicking human writing styles and even answering questions with remarkable accuracy. However, this proficiency is largely superficial; the models excel at recognizing correlations rather than understanding underlying causal relationships or applying genuine reasoning skills. While adept at predicting the next word in a sequence or completing a pattern, they often falter when presented with novel situations requiring extrapolation, inference, or the application of abstract principles – effectively highlighting a distinction between statistical mimicry and true cognitive ability. The success of SFT relies on the availability of labeled examples, limiting performance to tasks mirroring the training data and revealing a core constraint in achieving generalized reasoning capabilities.
Despite the remarkable progress in language model capabilities fueled by increased scale, complex reasoning tasks reveal a critical performance plateau. Studies demonstrate that simply increasing the number of parameters or the size of the training dataset yields diminishing returns when tackling problems requiring more than superficial pattern recognition. This isn’t merely a matter of needing more data, but a fundamental limitation inherent in the supervised learning approach itself. The models, while adept at identifying correlations within the training data, struggle to generalize to novel situations or to perform the kind of compositional reasoning necessary for truly solving problems – instead, they often reproduce patterns without genuine understanding. This suggests that scale alone cannot bridge the gap between statistical learning and robust, human-like reasoning abilities, prompting researchers to explore alternative architectures and learning paradigms.
Truly robust reasoning necessitates a shift from systems that passively recognize patterns to those that actively construct solutions. Current approaches often excel at identifying correlations within vast datasets, but falter when confronted with novel scenarios requiring genuine problem-solving. Instead of simply predicting the most likely continuation of a sequence, advanced systems must be capable of formulating hypotheses, exploring potential solutions, and evaluating their validity – a process akin to building a logical argument from first principles. This constructive approach demands architectures that move beyond statistical association and embrace symbolic manipulation, causal inference, and the ability to represent and reason about underlying principles, ultimately enabling a form of artificial intelligence that doesn’t just mimic intelligence, but genuinely embodies it.
![Analysis of the learned vocabulary reveals that NRT-WS([latex]-\log p[/latex]) develops a distinct](https://arxiv.org/html/2602.11549v1/x13.png)
Cultivating Internal Logic: Introducing Native Reasoning Training
Native Reasoning Training (NRT) represents a departure from traditional supervised learning approaches to reasoning by aiming to cultivate these skills autonomously. This framework moves beyond methods requiring pre-labeled reasoning steps or explicit human guidance. Instead, NRT focuses on directly optimizing the model’s internal reasoning process, enabling it to develop proficiency through self-assessment and iterative refinement. This is achieved without requiring datasets annotated with correct reasoning chains, offering a pathway to build reasoning capabilities in scenarios where such data is unavailable or costly to produce. The core principle is to encourage the model to generate and evaluate its own reasoning steps as part of the learning process.
Native Reasoning Training (NRT) builds upon established techniques such as Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR) by directly optimizing for the intermediate reasoning steps required to arrive at a final answer. Unlike standard SFT which focuses on input-output mapping, and RLVR which rewards only correct final answers, NRT encourages the model to explicitly demonstrate logical progression. This is achieved by formulating the training process to reward not just the correctness of the outcome, but also the validity and coherence of the reasoning chain leading to that outcome, thereby fostering improved reasoning capabilities beyond simple pattern matching.
Native Reasoning Training (NRT) utilizes an intrinsic reward signal to enhance model reasoning capabilities. This signal is calculated based on the model’s self-reported confidence in its generated answer, providing a direct feedback mechanism during training without external labeling. By optimizing for this intrinsic reward in conjunction with supervised fine-tuning and reinforcement learning, NRT achieves an average performance improvement of +10.2 points across a range of established benchmarks. The confidence score serves as a proxy for the quality of reasoning, allowing the model to reinforce steps leading to higher-confidence, and therefore more accurate, outputs.
The Weight of Evidence: Optimizing Reward Aggregation in NRT
Neural Reinforcement Training (NRT) performance is directly influenced by the method used to aggregate rewards from multiple sources. Two primary approaches are investigated: the Weighted Sum and the Geometric Mean. The Weighted Sum assigns a scalar weight to each individual reward signal, summing these weighted values to produce a single aggregate reward. Conversely, the Geometric Mean calculates the nth root of the product of individual rewards, where n represents the number of reward signals; this approach inherently penalizes low rewards more heavily than the Weighted Sum. The selection of an appropriate reward aggregation function is crucial for stable and effective policy optimization within the NRT framework, as it directly impacts the magnitude and distribution of the reward signal used for policy updates.
Both the NRT-WS (Weighted Sum) and NRT-GM (Geometric Mean) implementations utilize Group Relative Policy Optimization (GRPO) as their core policy update mechanism. GRPO facilitates efficient training by allowing updates to be computed relative to a group of policies, rather than absolute policy values. This relative approach reduces variance during training and improves sample efficiency, particularly in complex reward landscapes. By framing the optimization problem in terms of relative improvements within the group, GRPO enables more stable and faster convergence of the model’s policy during the reward aggregation process.
Model performance evaluation within the Neural Reward Training (NRT) framework utilizes Sequence-Level Probability as a key metric, and adheres to the standardized evaluation protocol established by the Open Language Model Evaluation Standard. Quantitative results demonstrate NRT achieving a score of 76.0 on the GSM8K benchmark, a substantial improvement over a Supervised Fine-Tuning (SFT) baseline which achieved a score of 29.0. This performance difference highlights the efficacy of NRT in enhancing model capabilities on complex reasoning tasks as assessed by the GSM8K dataset.
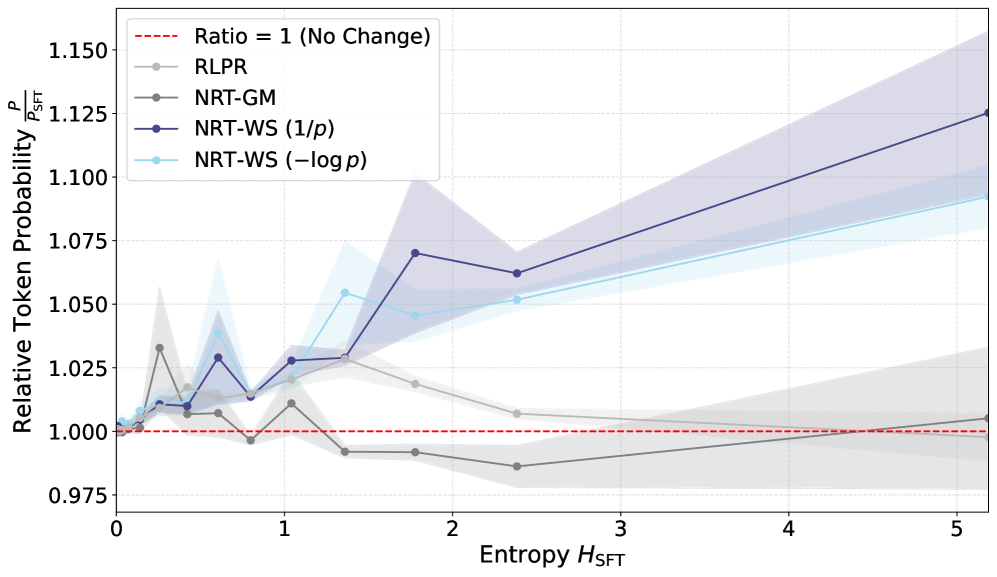
Beyond Mimicry: Implications and Future Directions
Neural Reasoning and Training (NRT) represents a significant step toward language models capable of true reasoning, rather than simply mimicking patterns in data. Traditional language models often excel at identifying correlations, but struggle with tasks requiring logical inference or problem-solving. NRT directly addresses this limitation by incentivizing the model to perform sequential reasoning steps, rewarding it not just for the final answer, but for the validity of each intermediate step. This approach fosters a system where the model learns to think through a problem, building a chain of thought that can be evaluated for its logical consistency. Consequently, NRT offers a pathway to models that generalize better to unseen scenarios and demonstrate a deeper understanding of the information they process, ultimately moving beyond superficial pattern recognition towards genuine cognitive abilities.
Neural Reasoning Training (NRT) represents a departure from conventional supervised learning techniques by directly incentivizing the process of reasoning, rather than solely focusing on correct answers. Traditional methods often rely on vast datasets of input-output pairs, leading models to identify statistical correlations without developing genuine understanding. NRT, however, introduces intrinsic rewards for each logical step taken towards a solution, effectively training the model to prioritize coherent reasoning paths. This approach circumvents the limitations of solely learning from end results, enabling the model to generalize better to unseen problems and fostering a more robust and interpretable reasoning capability. By optimizing for the quality of reasoning itself, NRT cultivates a system that doesn’t just appear to reason, but actively engages in a structured thought process, offering a pathway towards artificial intelligence with enhanced cognitive abilities.
Ongoing research aims to significantly enhance the Novel Reasoning Training (NRT) framework through iterative improvements to its reward functions and the exploration of advanced optimization algorithms. These refinements are designed to bolster stability and performance as NRT tackles increasingly complex reasoning challenges. Preliminary results demonstrate the potential of this approach; specifically, NRT exhibits a substantial 63% relative increase in predictive confidence when applied to fact-based question answering tasks, a marked improvement over the 30.8% baseline achieved through traditional supervised fine-tuning (SFT). Future investigations will also incorporate techniques like Advantage Estimation to further refine the learning process and unlock even greater reasoning capabilities within language models.
The pursuit of robust reasoning within large language models, as detailed in this work, mirrors a fundamental principle of enduring systems. Native Reasoning Training elegantly sidesteps the reliance on external validation – a costly and ultimately fragile dependency. Barbara Liskov observes, “Programs must be correct, and they must be understandable.” This sentiment resonates deeply with the NRT framework; by cultivating intrinsic rewards for coherent reasoning traces, the model learns not merely to arrive at a correct answer, but to justify its path – a demonstrable sign of internal consistency. The framework’s ability to operate without human annotation or external verifiers suggests a pathway toward systems that age gracefully, adapting and refining their internal logic over time, rather than crumbling under the weight of external dependencies.
What Lies Ahead?
The pursuit of reasoning in large language models invariably encounters the limitations of validation. This work, by turning to intrinsic reward based on confidence, sidesteps the expensive and ultimately finite resource of human annotation. However, it does not erase the fundamental question of grounding. Confidence, after all, is merely a state of the system, not a reflection of external truth. The model’s chronicle of its own reasoning – the generated traces – become the primary artifact, and their decay over successive training iterations a natural, if unexamined, process.
Future iterations will likely focus on the stability of these internal reward signals. A system that rewards itself can easily fall into local optima, generating increasingly elaborate, yet ultimately meaningless, justifications for answers. Deployment represents a single moment on the timeline, a snapshot of a system that will inevitably drift. The challenge is not simply to build a model that reasons now, but to understand the vectors of its future decay and build in mechanisms for graceful adaptation.
Perhaps the most compelling direction lies in exploring the meta-reasoning capabilities of such systems. If a model can learn to reason about its own reasoning, it may be possible to construct internal “verifiers” that don’t require external data – systems that assess the quality of a trace not by comparison to ground truth, but by internal consistency and coherence. The logging of these self-assessments will then become a crucial element in understanding the evolution of reasoning itself.
Original article: https://arxiv.org/pdf/2602.11549.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-02-15 00:18