Author: Denis Avetisyan
New research pinpoints how users behave when they become overly dependent on conversational AI, offering critical insights for building more responsible interfaces.
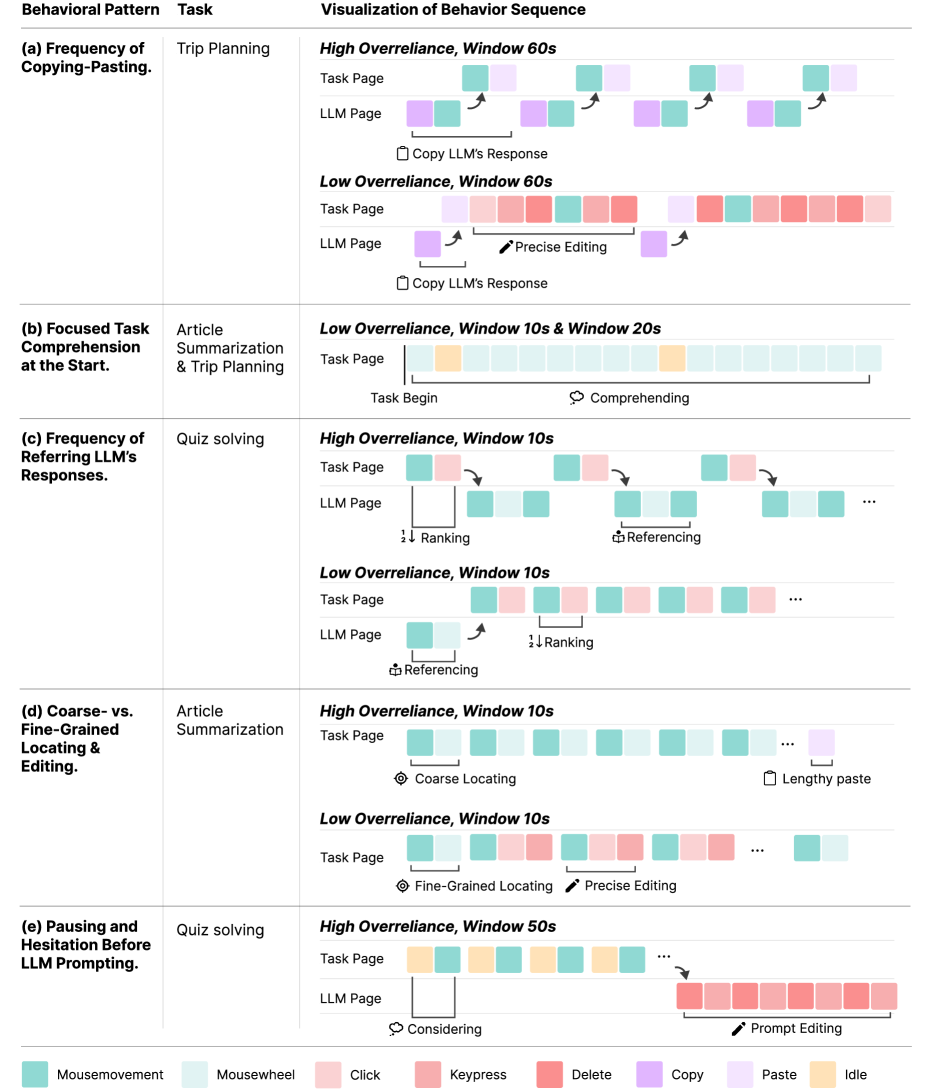
This review identifies behavioral clusters indicative of overreliance on large language models during human-AI interaction, moving beyond outcome-based metrics to understand the process of trust and dependence.
Despite the increasing prevalence of conversational language models in daily life, a key challenge remains in understanding-and mitigating-users’ tendency to overreliance despite the potential for inaccuracies. This research, ‘Behavioral Indicators of Overreliance During Interaction with Conversational Language Models’, investigates how specific user interaction patterns correlate with susceptibility to accepting misinformation generated by these models. Through analysis of \mathcal{N}=77 participants completing real-world tasks, we identified five distinct behavioral clusters-ranging from careful task navigation to frequent copy-pasting and uncritical acceptance-that reliably predict overreliance. How can these insights inform the design of more adaptive user interfaces that foster appropriate trust and critical evaluation when interacting with increasingly powerful AI systems?
The Illusion of Assistance: Why We Trust the Machine Too Easily
Conversational Large Language Models (LLMs) are swiftly transitioning from novelties to indispensable tools across a widening spectrum of tasks. Initially recognized for their ability to generate human-quality text, these models now facilitate activities ranging from complex data analysis and software coding to creative writing and personalized education. This rapid integration is fueled by increasing accessibility – LLMs are readily available through user-friendly interfaces and APIs – and their demonstrated capacity to enhance productivity and streamline workflows. Consequently, professionals in fields as diverse as marketing, engineering, and healthcare are increasingly incorporating LLMs into their daily routines, not simply as assistants, but as collaborative partners in problem-solving and innovation. The pervasiveness of these models suggests a fundamental shift in how information is accessed, processed, and utilized, promising a future where AI-driven assistance is seamlessly woven into the fabric of work and life.
The accelerating integration of large language models into daily workflows carries a significant, though often subtle, risk: an increasing tendency for users to accept LLM-generated recommendations without sufficient critical assessment. This ‘overreliance’ isn’t necessarily about a lack of understanding, but rather a shift in cognitive effort, where the readily available output preempts independent thought and verification. Consequently, errors or biases embedded within the LLM’s response may go unchallenged, potentially leading to flawed decision-making or the propagation of inaccurate information. The danger lies not in the technology itself, but in the potential for diminished human oversight, effectively outsourcing judgment to an artificial system and eroding the user’s capacity for independent reasoning.
The tendency to uncritically accept suggestions from large language models is notably amplified when individuals struggle with a thorough understanding of the task at hand, or when facing constraints of time. Research indicates that diminished task comprehension creates a cognitive space where users are less likely to independently verify information, instead deferring to the LLM as a readily available authority. Simultaneously, time pressure restricts the opportunity for careful consideration and fact-checking, fostering a reliance on the LLM’s output as a quick solution. This combination-limited understanding coupled with urgency-significantly elevates the risk of adopting inaccurate or inappropriate LLM-generated content without sufficient scrutiny, highlighting the importance of both cognitive preparedness and adequate time allocation when utilizing these tools.
Analysis of user interactions with large language models has revealed discernible patterns indicative of overreliance. Researchers identified five distinct behavioral markers, ranging from frequent referencing of the LLM for even simple tasks to a high frequency of direct copy-pasting of generated text without modification. These patterns aren’t simply about using the tool, but suggest a diminished critical assessment of the LLM’s output. The granularity of these identified behaviors – encompassing not just if a user copies, but how often and in what context – provides a basis for developing systems capable of detecting when a user may be unduly dependent on the LLM, potentially flagging instances where independent thought or verification is needed. This ability to monitor behavioral cues offers a pathway toward promoting responsible LLM integration and mitigating the risks associated with unquestioning acceptance of generated content.
Decoding the User: From Keystrokes to Cognitive Load
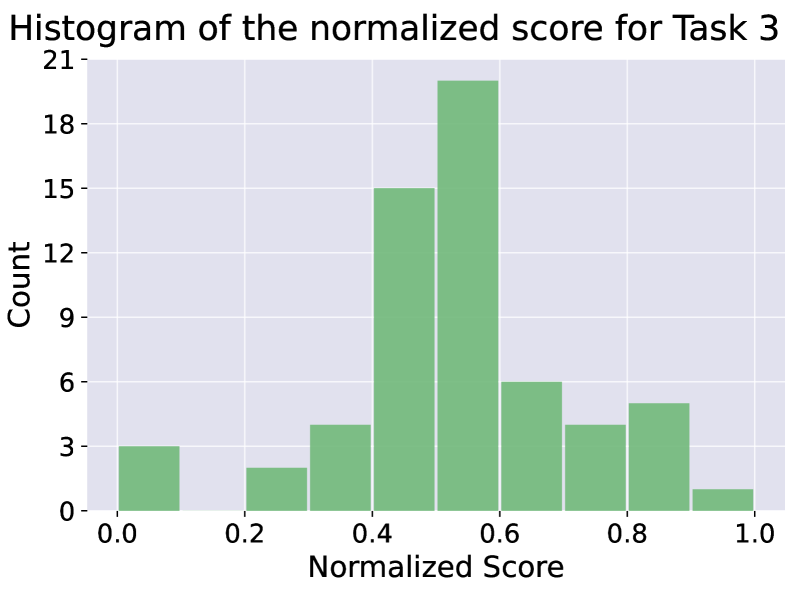
User interaction behaviors, specifically keystroke dynamics and mouse movements, function as quantifiable indicators of underlying cognitive processes. These actions are not simply inputs for task completion; the timing, speed, and patterns within these interactions correlate with cognitive states such as attention, workload, and decision-making strategies. Analysis of these behaviors offers a non-intrusive method for assessing a user’s cognitive load and control during task performance, providing insights that may not be readily available through self-reporting or traditional performance metrics. The granularity of these interaction signals allows for the detection of subtle shifts in cognitive engagement, enabling a more nuanced understanding of human-computer interaction.
Autoencoder embedding is utilized to transform variable-length sequences of user interaction behaviors – such as keystroke timings and mouse trajectories – into fixed-dimension vector representations. This process involves training an autoencoder neural network to reconstruct the original input sequence from a lower-dimensional ‘latent space’ representation. The resulting embedded vectors capture the essential characteristics of the interaction sequence while significantly reducing dimensionality, facilitating subsequent analysis and comparison. This compression is critical for applying algorithms like DBSCAN clustering to identify patterns within the high-dimensional space of user interactions, as it reduces computational complexity and mitigates the ‘curse of dimensionality’.
DBSCAN, or Density-Based Spatial Clustering of Applications with Noise, was implemented to categorize the autoencoder-generated embeddings of user interaction sequences. This unsupervised machine learning algorithm groups together similar embedding vectors based on their density, identifying clusters of interaction patterns without requiring pre-defined categories. Parameters for DBSCAN – specifically, the radius defining neighborhood scope and the minimum number of points required to form a dense region – were optimized to effectively differentiate between meaningful behavioral clusters and noise within the dataset. The resulting clusters represent distinct modes of user interaction, allowing for the automated discovery of common behavioral profiles exhibited across the participant pool.
Analysis of user interaction behaviors, specifically keystroke and mouse movement data, enables automated identification of patterns suggesting either overreliance on, or effective cognitive control during, interaction with conversational Large Language Models (LLMs). This was demonstrated through analysis of data collected from a participant pool of 62-70 individuals performing three distinct conversational tasks. The size of this dataset supports statistically robust pattern identification, allowing for differentiation between user behaviors indicative of appropriate LLM utilization and those suggesting undue dependence or conversely, skillful management of the LLM’s assistance.
The Usual Suspects: Task Complexity, Time Pressure, and Human Limitations
Analysis of user interaction data demonstrates a statistically significant correlation between task complexity and reliance on Large Language Model (LLM) assistance. Specifically, as the cognitive demands of a task increase – measured by factors such as the number of required steps, ambiguity of information, or necessary calculations – users exhibit a corresponding increase in their frequency of consulting and accepting recommendations from LLMs. This suggests that individuals rationally employ LLMs as cognitive offloading tools when faced with tasks exceeding their immediate processing capacity, rather than indicating a general disposition towards uncritical acceptance of AI outputs.
Analysis indicates that increased time pressure correlates with a heightened propensity to accept recommendations generated by Large Language Models (LLMs) without critical assessment. This effect is observed across multiple experimental conditions, suggesting that when users face strict deadlines, they reduce the cognitive effort dedicated to evaluating the LLM’s output. Rather than indicating a deficit in user skill, this behavior appears to be a rational adaptation to situational demands, prioritizing task completion speed over exhaustive verification of information. The observed increase in LLM reliance under time constraints demonstrates that external pressures can significantly influence decision-making processes, even when users are aware of potential inaccuracies in the provided recommendations.
Analysis indicates that increased reliance on Large Language Models (LLMs) is frequently a function of situational demands rather than individual negligence. Specifically, when faced with tasks exhibiting high complexity or strict time constraints, users demonstrate a predictable pattern of accepting LLM-generated recommendations with reduced critical evaluation. This behavior is not necessarily indicative of a lack of diligence, but instead represents a rational adaptation to optimize performance under pressure, where the cognitive cost of independent verification outweighs the perceived risk of accepting a potentially imperfect suggestion. This suggests that overreliance can be understood as a pragmatic strategy employed when resources – specifically, time and cognitive capacity – are limited.
The study demonstrates that individual differences in cognitive control and cognitive monitoring abilities are key factors in mediating the impact of task complexity and time pressure on reliance on Large Language Models (LLMs). To ensure the robustness of identified user clusters based on these cognitive factors, a stability threshold was implemented during data analysis. Specifically, each cluster had to appear in a minimum of 3 out of 18 iterations of the DBSCAN clustering algorithm; this requirement was necessary to validate that the observed groupings were not simply artifacts of the parameterization process and represented consistent patterns in the data.
The Illusion of Accuracy: Testing the Limits of Trust
Researchers deliberately introduced inaccuracies into the responses of large language models to simulate the challenges of real-world information seeking. This ‘misinformation injection’ wasn’t about creating outlandish falsehoods, but rather subtle errors-the kind of inaccuracies that might easily slip past cursory review. By carefully embedding these errors into LLM recommendations, the study aimed to understand how individuals respond when confronted with confidently delivered, yet incorrect, information. The approach allowed for a controlled examination of user behavior, specifically assessing the degree to which people accept and act upon flawed advice from these increasingly prevalent AI systems, mirroring the potential pitfalls of relying on LLMs for decision-making in everyday life.
Research indicates that even subtle inaccuracies within large language model (LLM) outputs can unexpectedly amplify user reliance on these systems. This tendency towards ‘overreliance’ is not uniform; individuals demonstrating lower cognitive control – a measure of their ability to monitor and correct errors – are particularly susceptible to accepting flawed recommendations from LLMs. The study demonstrated that even when users are aware of the potential for errors, a minor factual mistake can significantly increase confidence in the LLM’s overall response, suggesting that cognitive capacity plays a crucial role in mediating trust and discernment when interacting with artificial intelligence. These findings highlight a potential vulnerability in human-AI collaboration, where diminished critical assessment can lead to the uncritical acceptance of inaccurate information, even when that information originates from a demonstrably flawed source.
The study’s findings highlight a crucial need to bolster critical thinking abilities, as even subtle inaccuracies within large language model outputs can dramatically increase user reliance. Recognizing that individuals aren’t uniformly equipped to discern flawed information, research suggests proactive measures are essential. This includes not only educational initiatives designed to enhance evaluative skills, but also the development of robust systems capable of identifying and flagging potentially erroneous content. Such mechanisms could range from integrated fact-checking tools within LLM interfaces to algorithms that assess the internal consistency and plausibility of generated responses, ultimately fostering a more discerning and responsible approach to human-AI interaction.
The study’s findings extend beyond immediate error detection, suggesting a fundamental need to redesign how humans and artificial intelligence interact. Building trustworthy AI isn’t solely about minimizing mistakes, but also about anticipating how users will respond to them; this research demonstrates that even subtle inaccuracies can disproportionately influence reliance, particularly in individuals less equipped to critically assess information. To ensure the robustness of these findings, the predictive validity of identified user clusters – those exhibiting similar patterns of overreliance – was rigorously confirmed. This validation involved a stringent comparison between training and testing data, guaranteeing an absolute difference of no more than 0.15 in mean overreliance scores, thus bolstering confidence in the generalizability of these insights and informing the development of strategies for responsible human-AI collaboration.
The study meticulously details how users exhibit behaviors suggesting undue trust in conversational LLMs, a pattern predictable to anyone who’s witnessed a ‘controlled release’ morph into production chaos. It’s a familiar dance: elegant theory meeting the brutal reality of user interaction. Donald Davies famously observed, “It is not the answer that matters, but the question.” This research, by focusing on how users interact – the behavioral clustering – shifts the focus from simply measuring outcome accuracy to understanding the questions users are asking of these systems, and, more crucially, the questions they aren’t. It’s a stark reminder that the most sophisticated interface can’t compensate for a fundamental lack of critical engagement. The team’s work acknowledges that every revolutionary framework inevitably becomes tomorrow’s tech debt, but at least offers a framework for slowing the inevitable.
What’s Next?
This exploration into behavioral indicators of overreliance, while valuable, merely charts the first visible cracks in a rapidly expanding surface. The identified clusters – the hesitations, the uncritical acceptance of outputs – will, predictably, prove insufficient. Production use will reveal edge cases, idiosyncratic user patterns, and novel methods for confidently accepting demonstrably false information from a language model. Every abstraction dies in production, and this one, attempting to model trust, will be no different.
Future work must acknowledge that ‘safe’ AI interfaces aren’t built, they’re iteratively patched. The focus shouldn’t be on preventing overreliance-a losing battle-but on designing systems that gracefully degrade when it occurs. Monitoring for these behavioral indicators is a start, but the real challenge lies in building tools that allow users to efficiently recover from confidently held, yet demonstrably incorrect, beliefs.
Ultimately, this research highlights a deeper, less tractable problem: the human tendency to outsource cognition, even to systems known to be fallible. The observed behaviors aren’t bugs in the user, they’re features. Any attempt to ‘fix’ this will likely only result in users finding more subtle, more efficient ways to abdicate responsibility. The field should prepare for a long cycle of detection, mitigation, and inevitable circumvention.
Original article: https://arxiv.org/pdf/2602.11567.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-02-15 03:53