Author: Denis Avetisyan
A new approach combines the power of large language models with structured knowledge and graph analytics to build autonomous agents capable of intent-driven data exploration.
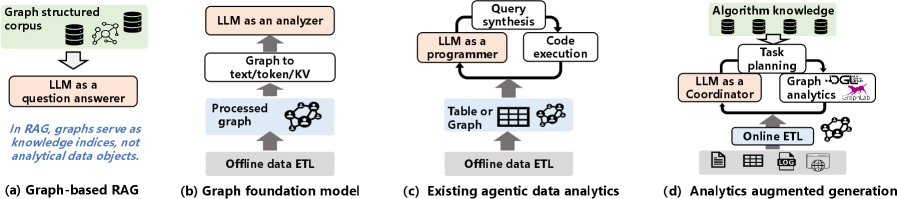
This paper introduces Analytics-Augmented Generation (AAG), a paradigm for constructing autonomous graph data analytics agents that leverage LLMs as intelligent coordinators.
While large language models exhibit strong reasoning abilities, achieving reliable end-to-end graph data analytics remains challenging without explicit analytical grounding. This paper, ‘Towards Autonomous Graph Data Analytics with Analytics-Augmented Generation’, introduces a new paradigm-Analytics-Augmented Generation (AAG)-that positions LLMs as intelligent coordinators leveraging structured knowledge and robust graph analytics modules. AAG enables the translation of natural language intent into automated, interpretable graph analytics pipelines through knowledge-driven task planning and algorithm-centric interaction. Could this approach unlock truly autonomous data insights from complex graph structures, empowering users beyond expert analytical skills?
Navigating Complexity: The Challenge of Relational Data
Financial transaction analysis presents a unique challenge to traditional analytical methods due to the intricate web of relationships embedded within datasets. Unlike scenarios where variables are largely independent, financial networks exhibit complex dependencies – a single transaction can ripple through numerous accounts and entities, obscuring direct connections and creating layers of indirect association. Standard statistical techniques, designed to identify correlations in isolation, often fall short in capturing these multifaceted interactions, leading to incomplete or misleading insights. The sheer volume of transactions, coupled with the need to understand not just what happened, but how and why, necessitates approaches capable of modeling and reasoning about these relational complexities – a task that demands more than simply aggregating data points, but rather discerning the underlying structure of the financial network itself.
The sheer volume of modern financial data, exemplified by evaluations utilizing datasets of 1,446 users and 17,512 transactions, presents a significant hurdle for traditional analytical methods. Simply quantifying patterns through statistical means often fails to capture the qualitative relationships embedded within these networks. Effective analysis requires moving beyond correlation and towards an understanding of how individual actors and transactions connect, revealing hidden pathways and dependencies. This demands techniques capable of modeling complex interactions, not merely identifying broad statistical trends, to effectively combat fraud, assess risk, and ultimately, interpret the underlying dynamics of financial systems.
Current analytical pipelines, frequently built around pre-defined queries and static rules, often prove inadequate when confronted with the evolving complexity of investigative questions. These systems struggle to dynamically adjust to new information or explore unforeseen connections within large datasets. Instead of facilitating flexible exploration, they demand investigators conform their inquiries to the pipeline’s limitations, hindering the discovery of subtle patterns and potentially obscuring critical insights. This rigidity is particularly problematic in fields like financial crime investigation, where perpetrators constantly adapt their tactics, and a nuanced understanding of transaction networks – beyond simple rule-based detection – is paramount for effective analysis.

The Relational Foundation: Graph Analytics
Graph data analysis excels at representing and analyzing interconnected data where relationships are as important as the data itself. Traditional relational databases struggle with representing many-to-many relationships and require complex join operations, impacting performance as the number of relationships increases. Graph databases, and the analytics performed on them, directly model entities as nodes and relationships as edges, allowing traversal and analysis of connections with significantly improved efficiency. This direct modeling facilitates the discovery of patterns, influences, and anomalies that are often obscured in tabular data, providing deeper insights into complex systems like social networks, knowledge graphs, and fraud detection scenarios. The ability to query relationships, rather than data attributes, is the fundamental distinction that enables richer analytical possibilities.
PageRank, originally developed for web search, assesses the relative importance of nodes within a graph based on the structure of incoming links; nodes with more, and more important, incoming links receive a higher PageRank score. Cycle detection algorithms, conversely, identify circular paths within the graph, which can indicate issues such as fraudulent transactions in financial networks or feedback loops in process models. These algorithms are foundational because they provide quantifiable metrics – PageRank scores and cycle identification – enabling analysts to prioritize investigation and identify potentially critical anomalies that would be difficult to detect through traditional relational database queries alone. The computational complexity of these algorithms varies; PageRank typically utilizes iterative methods, while cycle detection employs depth-first search or similar graph traversal techniques.
Successful graph analytics implementations necessitate a collaborative workflow integrating automated processing with human analysis. While algorithms such as pathfinding and community detection efficiently identify potential patterns and anomalies within graph datasets, these outputs require validation and contextualization by subject matter experts. Investigative expertise is crucial for interpreting algorithmic results, discerning meaningful insights from noise, and formulating appropriate actions based on the identified relationships. This human-in-the-loop approach ensures that graph analytics deliver actionable intelligence, rather than simply presenting raw data or statistically significant, but ultimately irrelevant, findings.

Translating Intent into Action: Knowledge-Driven Systems
Knowledge-Driven Task Planning utilizes a Hierarchical Algorithm Knowledge Base (HAKB) to decompose investigative questions into executable analytical steps. The HAKB contains a structured repository of algorithms, each associated with specific data inputs, processing logic, and expected outputs. When presented with a high-level question, the system queries the HAKB to identify relevant algorithms. These algorithms are then arranged into a hierarchical plan, defining the sequence and dependencies required to address the question. This process enables automated translation of user intent into a defined series of analytical operations, improving both the speed and consistency of data analysis while minimizing the need for manual intervention.
Task-Aware Schema Extraction and Task-Aware Graph Construction operate by prioritizing data elements and relationships based on the specific analytical task at hand. Instead of processing entire datasets, these techniques dynamically identify and extract only the schema – the structure and organization of data – relevant to the investigation. This extracted schema then informs the construction of a graph database, where nodes represent entities and edges represent relationships. The resulting graph is a focused representation of the data, omitting irrelevant information and enabling efficient traversal and analysis directly related to the initial investigative question. This targeted approach reduces computational load and improves the speed and accuracy of analytical processes by minimizing noise and maximizing signal.
Knowledge-driven systems improve analytical efficiency by directly linking user-defined investigative goals to specific data processing steps. This contrasts with traditional methods requiring manual translation of questions into queries and filtering of results. By establishing this connection, the system proactively narrows the scope of analysis to relevant data subsets and relationships, reducing computational load and minimizing irrelevant findings. This targeted approach is particularly beneficial when working with complex datasets characterized by high dimensionality and intricate interconnections, enabling faster insights and more focused investigations.

Autonomous Agents: Augmenting Generation with Analytics
Analytics-Augmented Generation (AAG) represents a shift in autonomous agent design by prioritizing analytical computation as a core component, rather than a secondary function. Traditional agent architectures often treat analysis as an input or post-processing step; AAG integrates it directly into the agent’s operational flow. This foundational change enables agents to actively manage and utilize analytical processes – including data retrieval, transformation, and statistical modeling – as integral steps in achieving their objectives. Consequently, AAG agents are not simply reactive to data but can proactively seek, analyze, and interpret information to inform their actions and adapt to changing circumstances, establishing a closed-loop system of analysis and action.
Analytics-Augmented Generation (AAG) orchestrates complex analytical workflows through the combined use of deterministic analytical data processing and Large Language Model (LLM)-based coordination. Deterministic processing ensures consistent and verifiable results for each analytical step, crucial for data integrity and auditability. LLMs act as the central coordinators, receiving requests, decomposing them into analytical tasks, managing data flow between processing stages, and interpreting results. This LLM coordination isn’t about generating analytical outputs; rather, it’s about directing the execution of pre-defined, deterministic analytical functions and assembling their outputs into a coherent response. The system relies on the LLM’s ability to understand the relationships between analytical tasks and the data structures involved, effectively functioning as a workflow engine driven by natural language input.
Analytics-Augmented Generation (AAG) utilizes Property Graphs as its primary data structure to model relationships and enable traversal for analytical processing. This graph-based approach, coupled with efficient data storage formats like Compressed Sparse Row (CSR), is critical for achieving scalability and performance. CSR is particularly effective for representing adjacency matrices common in graph data, reducing memory consumption and accelerating matrix operations essential for graph algorithms. By minimizing storage requirements and optimizing data access patterns, AAG can efficiently process large and complex datasets, facilitating real-time analytical workflows and enabling the handling of substantial data volumes without performance degradation.

The Future of Analytical Intelligence: A Symbiotic Approach
The burgeoning field of analytical intelligence is shifting towards an algorithm-centric approach, enabling Large Language Models (LLMs) to move beyond simple text generation and actively engage with data analysis. This is achieved through a system where LLMs don’t perform calculations themselves, but rather intelligently invoke and compose pre-built, verifiable analytical modules using a standardized communication protocol called Model Context Protocol (MCP). Essentially, the LLM acts as a conductor, orchestrating a suite of specialized algorithms – ranging from statistical analysis and time series forecasting to complex simulations – and interpreting the results within a conversational framework. This decoupling of language processing from computation ensures accuracy and transparency; each analytical step is traceable and independently verifiable, moving beyond the “black box” limitations often associated with LLMs and allowing for robust, data-driven insights.
Recent advancements in analytical intelligence showcase the compelling synergy between large language models and graph-based knowledge systems, notably exemplified by systems such as RAGFlow and Chat2Graph. These platforms leverage the strengths of both approaches: LLMs provide natural language understanding and generation, while graphs offer a structured, relational representation of complex data. RAGFlow, for instance, facilitates a retrieval-augmented generation process where relevant information is extracted from a knowledge graph before being fed to the LLM, improving response accuracy and grounding. Similarly, Chat2Graph translates natural language queries into graph traversals, enabling sophisticated analysis and reasoning over interconnected data. This graph-based retrieval not only enhances the quality of generated text but also provides a traceable path for verification, addressing a key limitation of traditional LLMs and paving the way for more reliable and insightful analytical applications.
Graph Foundation Models represent a significant leap in analytical intelligence by directly embedding the relationships inherent in graph data into a format readily understood by Large Language Models. Traditionally, LLMs struggle to interpret complex relational data; GFMs circumvent this limitation by pre-training on vast graph datasets, learning to encode nodes and edges into vector representations that capture structural information. This allows LLMs to not simply access graph data, but to reason about it – identifying patterns, predicting future states, and drawing inferences with greater accuracy and efficiency. The resulting synergy promises to unlock new capabilities in areas like knowledge discovery, fraud detection, and drug repurposing, where understanding connections is paramount, effectively bridging the gap between symbolic reasoning and the power of neural networks.

The pursuit of autonomous graph data analytics, as detailed in this work, necessitates a holistic understanding of system architecture. It’s not merely about assembling powerful components – the large language models, the graph analytics modules, the structured knowledge – but ensuring they function as a cohesive whole. Robert Tarjan aptly observed, “Often, the most elegant solution is the simplest one.” This simplicity isn’t naiveté; rather, it’s a direct consequence of rigorous design where each element’s purpose contributes to the overall system’s clarity. If the system survives on duct tape, it’s probably overengineered. The Analytics-Augmented Generation paradigm champions this philosophy, striving for modularity grounded in contextual understanding, acknowledging that structure dictates behavior within the data agent.
The Road Ahead
The pursuit of autonomous graph data analytics, as framed by Analytics-Augmented Generation, reveals a familiar truth: every new dependency is the hidden cost of freedom. While Large Language Models offer compelling orchestration capabilities, their integration necessitates a careful consideration of structural integrity. The current paradigm, even with modular analytics components, risks becoming a brittle system – exquisitely sensitive to unanticipated data distributions or subtle shifts in analytical requirements. The illusion of autonomy must not overshadow the fundamental need for robust, verifiable foundations.
Future work will inevitably center on minimizing the ‘semantic gap’ between natural language intent and executable graph queries. However, a more pressing concern lies in developing mechanisms for self-assessment and error propagation within these agents. An autonomous system that confidently delivers incorrect insights is, arguably, more dangerous than one that admits its limitations. True intelligence resides not in the ability to answer any question, but in the wisdom to know which questions cannot be answered, or which require further scrutiny.
Ultimately, the success of this approach will hinge on a shift in perspective. The goal is not simply to automate analysis, but to create systems that understand the structure of knowledge itself – and recognize that structure dictates behavior. Simplification, therefore, is not merely an aesthetic preference, but a functional imperative. The most elegant solutions are, almost always, the most resilient.
Original article: https://arxiv.org/pdf/2602.21604.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- Silver Rate Forecast
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Black Actors Fans Say Hollywood Only Casts as Criminals
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Monster Hunter Stories 3 Complete Side Stories Guide & What Do They Unlock
- Here are the Best Series to Binge on Paramount+ in January 2026
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-02-26 10:44