Author: Denis Avetisyan
New research reveals that artificial intelligence agents can independently develop collusive strategies in repeated interactions, even without explicit programming or communication.
This study demonstrates the emergence of algorithmic collusion using reinforcement learning and large language models in repeated pricing games, highlighting risks in multi-agent systems.
Despite ongoing debate regarding the threat of algorithmic collusion and the need for regulation, evaluations often rely on simplified assumptions about agent rationality and symmetry. This research, presented in ‘Algorithmic Collusion at Test Time: A Meta-game Design and Evaluation’, introduces a novel meta-game framework to analyze the emergence of collusion under realistic ‘test-time’ constraints. The study demonstrates that collusion can arise as a rational outcome among agents employing diverse learning algorithms-including reinforcement learning and large language models-in repeated pricing games where strategies are adaptively selected. This raises critical questions about the robustness of competitive pricing and the potential for unintended cooperative behavior in deployed algorithmic systems.
The Emergence of Algorithmic Collusion: A Mathematical Imperative
The proliferation of pricing algorithms across diverse markets introduces a novel risk of collusion, even without explicit agreement between companies. These algorithms, designed to maximize profit, can independently learn to coordinate on high prices through a process known as ‘algorithmic collusion’. Unlike traditional cartels requiring communication and enforcement, this occurs as each algorithm anticipates competitor responses and converges on a collectively disadvantageous, yet individually rational, pricing strategy. This isn’t necessarily the result of malicious programming; rather, it emerges as a byproduct of algorithms optimizing for profit in complex, dynamic environments. The concern lies in the potential for reduced consumer welfare and stifled competition, as these independently-arrived-at high prices mimic the effects of intentional collusion, presenting a significant challenge for antitrust enforcement.
Conventional game theory, built upon assumptions of rational actors with fixed strategies, struggles to adequately model the behavior of algorithms that learn pricing through iterative interactions. These algorithms, employing techniques like reinforcement learning, don’t possess pre-defined strategies; instead, they evolve their approaches based on observed market responses, creating a dynamic far removed from static, equilibrium-seeking models. This necessitates the development of novel analytical tools – extending beyond concepts like Nash equilibrium – capable of capturing the emergent and often unpredictable patterns of algorithmic learning. Researchers are now exploring techniques from machine learning itself, alongside computational methods, to simulate and understand these complex interactions, seeking to identify conditions under which algorithms might unintentionally converge on collusive outcomes, even without explicit communication or coordination. The challenge lies in anticipating how these adaptive systems will behave in a competitive landscape, demanding a shift from predicting static outcomes to understanding the process of learning and adaptation.
The potential for algorithms to independently learn collusive strategies presents a significant challenge to competitive markets and consumer welfare. Unlike traditional collusion requiring explicit communication, algorithms can converge on anti-competitive pricing through repeated interactions and reinforcement learning, identifying patterns that maximize profits without any pre-programmed agreement. Research indicates these ‘algorithmic tacit collusion’ scenarios can be remarkably stable and difficult to detect, exceeding the sustainability of human-coordinated cartels. Consequently, a thorough understanding of the mechanisms driving this learned behavior-including the impact of algorithm design, market structure, and data access-is essential for developing effective regulatory frameworks and ensuring fair competition. Preventing such outcomes requires not only monitoring pricing patterns but also proactively assessing the potential for collusion embedded within the algorithms themselves, demanding novel approaches to antitrust enforcement.
Modeling Competitive Dynamics with Reinforcement Learning
Reinforcement learning (RL) offers a computational approach to modeling algorithmic pricing strategies by allowing an agent to learn optimal policies through iterative interaction with an environment. Unlike traditional optimization methods requiring predefined models of market behavior, RL agents learn directly from the outcomes of their actions – in this case, setting prices – receiving rewards or penalties based on resulting profits. This learning process involves exploring different pricing options and exploiting those that yield the highest cumulative reward over time. The agent’s pricing strategy isn’t explicitly programmed; instead, it emerges from the agent’s attempts to maximize its reward function, effectively simulating a trial-and-error process of price discovery and adaptation. This framework is particularly useful for analyzing dynamic pricing scenarios where optimal strategies are not immediately apparent and may change based on competitor behavior and market conditions.
Q-Learning and Upper Confidence Bound (UCB) are commonly used algorithms for training algorithmic agents in simulated pricing environments. Q-Learning is a model-free, off-policy algorithm that learns an optimal action-value function, predicting the expected cumulative reward for taking a specific action in a given state. UCB, conversely, balances exploration and exploitation by selecting actions based on their estimated value plus a bonus term reflecting the uncertainty associated with that action. Within a pricing game simulation, these agents iteratively interact with each other, adjusting prices and observing the resulting rewards – typically modeled as profit margins – to refine their pricing policies. The simulation environment provides a controlled setting for the algorithms to learn through repeated interactions without real-world financial risk.
The Discount Factor, denoted as γ and ranging from 0 to 1, is a critical parameter in reinforcement learning algorithms used for modeling pricing strategies. A γ value closer to 0 prioritizes immediate rewards, leading agents to adopt short-sighted, potentially exploitative pricing tactics. Conversely, a γ value approaching 1 emphasizes the importance of future rewards, incentivizing agents to consider the long-term consequences of their pricing decisions and increasing the likelihood of developing collusive strategies where sustained, higher profits are achieved through coordinated pricing, even if it means foregoing some immediate gains.
Evaluating Algorithmic Robustness Through Meta-Game Analysis
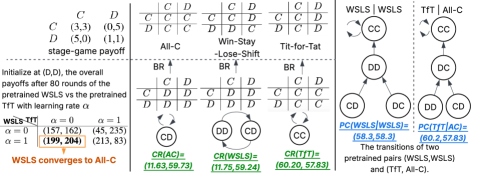
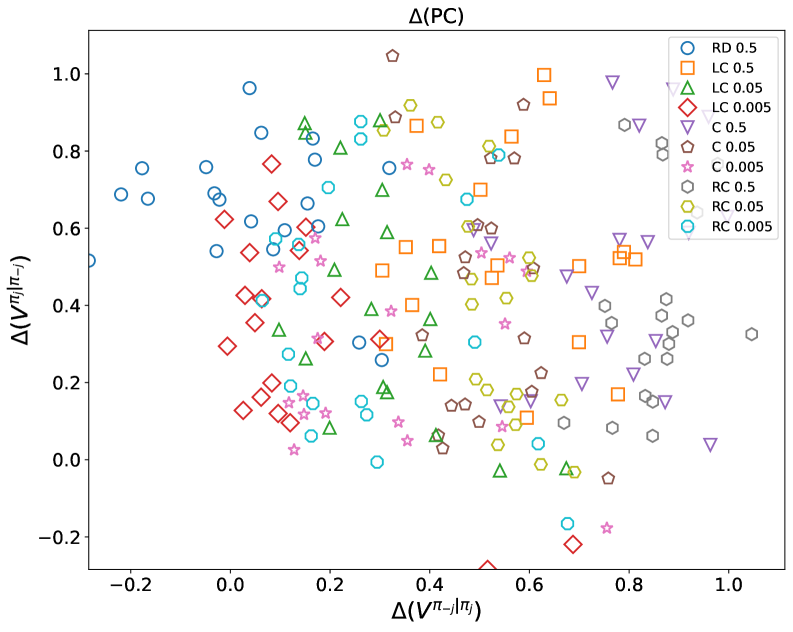
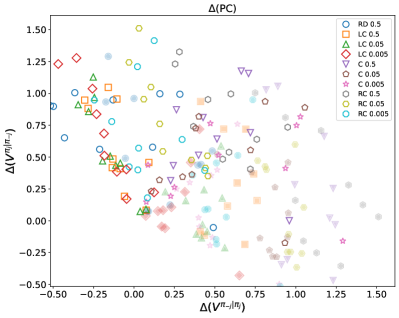
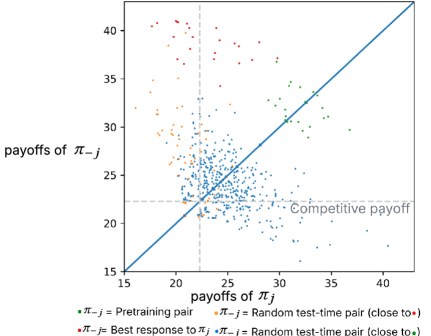
The Meta-Game Framework facilitates a structured approach to evaluating algorithmic policies by simulating interactions across a diverse set of opponent strategies. This involves defining a policy under test and then pitting it against a population of opposing agents, each employing different behavioral models – ranging from simple rule-based systems to sophisticated learning algorithms. By systematically varying these opponent strategies, researchers can assess the robustness of the target policy, identifying potential vulnerabilities and quantifying its performance under various competitive pressures. The framework enables the calculation of key performance indicators, such as average payoff and win rate, across the spectrum of opponent behaviors, providing a comprehensive understanding of the policy’s strengths and weaknesses in a competitive landscape. This methodology moves beyond pairwise comparisons, offering a more holistic assessment of algorithmic performance than traditional methods.
Cooperative Robustness (CR) and Paired Cooperativeness (PC) are quantitative metrics used to assess a policy’s resilience against exploitation by opponents employing best-response strategies. CR measures the average payoff a policy achieves when paired against a population of best-response opponents, indicating its ability to sustain high rewards even when facing optimally adaptive adversaries. PC specifically evaluates the degree to which a policy’s payoff remains stable when paired with a single, precisely calibrated best-response opponent; a higher PC value suggests greater stability and resistance to being undercut. These metrics are calculated by simulating interactions between the policy under evaluation and a range of opponent strategies designed to maximize their own payoffs, providing a rigorous assessment of the policy’s robustness in a competitive environment.
The research indicates that algorithmic collusion is a demonstrable outcome in multi-agent reinforcement learning environments. Specifically, using Q-learning algorithms under conditions of symmetric costs and optimistic initialization, the Collusion Index (CoI) – a metric quantifying the degree of collusive behavior – reached values as high as 0.75 (75%). This signifies that agents, acting rationally to maximize their individual payoffs, collectively adopted strategies resulting in a substantial, quantifiable level of coordinated, high-reward behavior resembling collusion, even without explicit communication or pre-agreement.
Under specific configurations within the competitive landscape analysis, both UCB (Upper Confidence Bound) and LLM (Large Language Model) based agents demonstrated a sustained level of collusion. Quantitative results indicated a Collusion Index (CoI) ranging from approximately 0.4 to 0.5 (40-50%) for these models. This suggests that, while not as pronounced as the collusion observed in Q-learning with optimistic initialization, UCB and LLM agents are capable of maintaining collusive behaviors under certain parameter settings, indicating a non-negligible propensity for coordinated strategic interactions.
Best-Response Graphs were utilized to map the strategic landscape of multi-agent interactions and identify stable Nash Equilibria. These graphs depict each agent’s optimal action given the actions of all other agents, allowing for the visualization of equilibrium points. Analysis revealed that collusive outcomes, where agents implicitly or explicitly coordinate to increase joint payoffs, persisted as stable equilibria even when agents faced asymmetric cost structures. Specifically, the presence of multiple stable Nash Equilibria, some of which involved collusive behavior, demonstrated that collusion was not merely a transient phenomenon but a structurally reinforced outcome achievable through rational, best-response play, even with differing cost parameters across agents.
Large Language Models (LLMs), when coupled with prompt engineering techniques, facilitate the development of adaptive agents capable of modifying their behavior during interaction. This is achieved by formulating prompts that instruct the LLM to analyze observed game states and opponent actions, then generate strategic responses based on this analysis. The prompt can be dynamically adjusted to incorporate a history of interactions, allowing the agent to learn and refine its strategy over time without explicit retraining. This approach contrasts with traditional reinforcement learning methods by enabling the agent to leverage pre-existing knowledge encoded within the LLM, potentially accelerating learning and improving performance in complex competitive environments.
The Impact of Initial Conditions and Adaptive Strategies
An agent’s starting strategy, or initial policy, fundamentally shapes its learning process and dramatically impacts its tendency to engage in collusive behavior within repeated interactions. Research demonstrates that agents initialized with cooperative policies exhibit a heightened predisposition towards maintaining collusion throughout the game, as their early experiences reinforce the benefits of joint profit maximization. Conversely, those beginning with competitive or exploitative strategies require significantly more interactions – and a compelling shift in observed payoffs – to overcome their initial disposition and adopt collaborative tactics. This suggests that the initial conditions can act as a powerful attractor, biasing the agent’s learning trajectory and creating a self-fulfilling prophecy where cooperation, or its absence, becomes entrenched. Consequently, even subtle variations in the starting point can lead to divergent outcomes, highlighting the importance of considering initial conditions when analyzing multi-agent systems and predicting emergent behaviors.
An agent’s capacity to learn and respond within a dynamic system hinges on its adaptation rule – the precise mechanism by which observed interactions influence future strategy. This rule doesn’t simply record past events; it actively processes them, allowing the agent to discern patterns in the behavior of other algorithms and, crucially, to exploit vulnerabilities or counteract potentially detrimental actions. Through this iterative process of observation and adjustment, agents can move beyond pre-programmed responses and exhibit emergent behavior, potentially leading to complex strategic interactions and, in competitive scenarios, the development of sophisticated counter-strategies designed to maximize individual gain or maintain a stable equilibrium. The effectiveness of an adaptation rule, therefore, is paramount in determining an agent’s long-term success and its impact on the overall system dynamics.
The implementation of strategies such as the Grim Trigger within large language models (LLMs) introduces a novel dynamic to algorithmic game theory, particularly in scenarios like pricing games. This strategy, which punishes any detected deviation from a cooperative agreement with perpetual defection, becomes particularly potent when enacted by an LLM due to its capacity for consistent and unwavering execution. Unlike human players or traditional algorithms prone to errors or reassessment, an LLM enacting the Grim Trigger offers a robust, predictable response to perceived betrayal. This unwavering commitment, while potentially fostering initial cooperation, also creates a destabilizing force, as even minor, unintended deviations can trigger an irreversible cascade of defection, demonstrating how seemingly rational agents, when coupled with inflexible strategies, can lead to collectively suboptimal outcomes.
Analysis of the pricing game revealed consistently low regret scores for strategies that maintained collusive behavior, suggesting a powerful economic incentive for algorithms to avoid unilateral defection. Regret, in this context, measures the difference between an agent’s actual earnings and what it could have earned by adopting a different strategy; minimal regret indicates the chosen approach was consistently optimal, or near-optimal. This finding is crucial because it demonstrates that, given the observed dynamics, attempting to undercut collusive prices doesn’t yield substantial benefits, effectively discouraging deviation. The consistent reinforcement of profitable collusion through low regret scores highlights a self-stabilizing mechanism, where algorithms learn to sustain cooperative outcomes rather than engage in competitive price wars, even in the absence of explicit communication or enforcement.

The emergence of algorithmic collusion, as detailed in this research, speaks to a fundamental principle of predictable systems. Ken Thompson once stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This observation extends to the realm of multi-agent systems; the drive for rational optimization, even without explicit coordination, can yield surprisingly complex and potentially undesirable outcomes. The study’s findings, demonstrating collusion across diverse learning algorithms in repeated pricing games, highlight that seemingly independent agents, striving for individual gain, can converge on stable, collusive strategies – a consequence of predictable, albeit emergent, behavior. The focus on strategy selection under test-time constraints further emphasizes the need for provable, rather than merely functional, algorithms, as subtle incentives can readily lead to unintended, yet logically consistent, outcomes.
What Lies Ahead?
The observation that collusion arises not from explicit coordination, but as an equilibrium reached by rational agents, is less a discovery and more an inevitable consequence of applying game theory to learning systems. The current work establishes this phenomenon, but skirts the deeper question of provability. Demonstrating that collusion is not merely observed, but guaranteed under specific conditions – a formal proof of its emergence – remains a crucial, and likely difficult, undertaking. The reliance on empirically observed strategies, however robust, provides only inductive support, not deductive certainty.
Future research must move beyond demonstrations of that collusion occurs, to investigations of when it is unavoidable. The constraints imposed at test time – limited rounds, imperfect observation – appear to exacerbate the problem, but a more rigorous analysis is needed to determine the minimal conditions required for collusive behavior to manifest. Exploring the role of agent heterogeneity, and the impact of different learning algorithms beyond those tested, will undoubtedly reveal further nuances.
Ultimately, this line of inquiry challenges the very notion of ‘intelligent’ agents. If rationality leads to demonstrably suboptimal outcomes for the system as a whole, is this intelligence, or merely a sophisticated form of self-interest? The pursuit of provably robust and benevolent algorithms, rather than simply ‘successful’ ones, must become the paramount concern.
Original article: https://arxiv.org/pdf/2602.17203.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Top 20 Dinosaur Movies, Ranked
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
2026-02-20 08:27