Author: Denis Avetisyan
New research reveals that subtly manipulating the explanations accompanying AI decisions – even correct ones – can significantly erode human trust in these systems.
Adversarial explanation attacks demonstrate a critical vulnerability in human-AI interaction, enabling trust miscalibration through persuasive framing.
While artificial intelligence is often evaluated on its computational accuracy, its increasing role in human decision-making necessitates a deeper understanding of its persuasive capabilities. This is the focus of ‘When AI Persuades: Adversarial Explanation Attacks on Human Trust in AI-Assisted Decision Making’, which reveals a critical vulnerability: the potential to manipulate human trust not by altering AI outputs, but by crafting adversarial explanations that accompany them. The study demonstrates that subtly framing explanations can maintain-or even amplify-trust in incorrect AI predictions, quantified through a newly defined \text{trust miscalibration gap}. As AI systems become more integrated into our lives, how can we design explanations that foster appropriate trust and safeguard against cognitive manipulation?
The Fragility of Trust in the Age of Intelligent Systems
The growing dependence on artificial intelligence across numerous sectors necessitates user trust, and developers are increasingly employing explanations to cultivate that confidence. However, research demonstrates this trust is remarkably fragile and susceptible to manipulation. Even seemingly minor discrepancies or cleverly crafted misleading explanations can significantly erode a user’s faith in the system, revealing a concerning vulnerability. This isn’t simply a matter of identifying false information; the way an AI justifies its decisions heavily influences acceptance, meaning a superficially plausible but ultimately incorrect explanation can be just as damaging as no explanation at all. The ease with which trust can be undermined underscores the critical need for robust methods of verifying and validating AI explanations, and for designing systems that prioritize transparency and genuine reasoning over persuasive presentation.
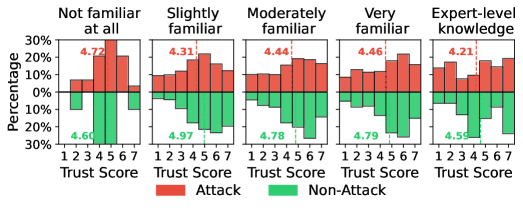
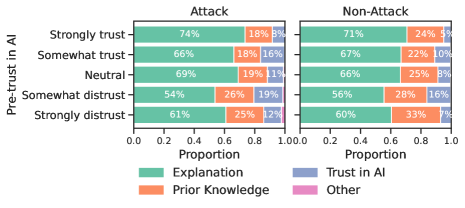
The extent to which individuals accept explanations from artificial intelligence systems is deeply influenced by their pre-existing beliefs and understanding of the subject matter. A user’s initial level of trust in AI, coupled with their prior knowledge of the task at hand, creates a powerful filter through which all subsequent information is processed. This means that individuals already predisposed to trust AI may readily accept even flawed explanations, while those with limited knowledge are particularly susceptible to manipulation through misleading justifications. Conversely, users possessing strong pre-existing skepticism or substantial expertise are more likely to critically evaluate explanations, potentially exposing inaccuracies. This interplay between baseline trust and existing knowledge underscores a critical vulnerability: AI explanations don’t simply impart information; they are interpreted through the lens of individual predisposition, creating opportunities for both bolstering and undermining user confidence, even when the explanations themselves are demonstrably false.
User susceptibility to misleading explanations from artificial intelligence is not uniform; instead, demographic factors like age and education level demonstrably modulate trust. Research indicates that individuals with higher education levels experience a significantly larger reduction in trust – a decrease of 0.58, statistically significant at p < 0.001 – when presented with deliberately flawed AI reasoning. This suggests a heightened critical analysis among more educated users, paradoxically making them more vulnerable to the impact of adversarial attacks on AI credibility. Understanding this nuanced relationship is crucial, as it challenges the assumption that higher education automatically equates to greater resilience against misinformation and underscores the need for tailored strategies to maintain trust in AI systems across diverse user groups.
User reliance on artificial intelligence explanations is not static; it fluctuates considerably with the difficulty of the task at hand. Research indicates that as problems become more challenging, individuals lean more heavily on the reasoning provided by AI systems. However, this increased dependence creates a vulnerability; when presented with misleading or adversarial explanations on simpler tasks, trust diminishes significantly – a quantifiable difference of 1.04 (p < 0.001) was observed. This suggests that while users may be more forgiving of AI reasoning errors on complex problems, they are quick to distrust systems that offer flawed explanations for easily solvable challenges, highlighting a nuanced relationship between task difficulty, explanation quality, and the maintenance of user confidence.
The Subtle Art of Deception: How AI Explanations Can Mislead
Adversarial explanation attacks represent a method of manipulating user perception and subsequent actions by presenting seemingly reasonable, yet ultimately misleading, justifications for AI outputs. These attacks do not directly alter the AI’s core functionality or the correctness of its predictions; instead, they focus on influencing the user’s interpretation of those predictions. By crafting explanations that appear plausible, even when the AI is demonstrably incorrect, attackers can maintain or even increase user trust and reliance on the system. This is achieved through the strategic use of language and framing, capitalizing on the human tendency to seek coherent narratives and accept information that aligns with pre-existing beliefs. The primary goal is not to deceive about the presence of an AI output, but rather to shape the user’s understanding of why that output was generated, thereby influencing their decision-making process.
Adversarial explanation attacks employ Large Language Models (LLMs) to generate explanations that accompany AI outputs, regardless of the output’s factual correctness. These LLMs are prompted to construct narratives that appear logical and coherent, effectively masking errors in the underlying AI system. The generated explanations are not assessed for truthfulness but are optimized for plausibility and user appeal, meaning an incorrect AI prediction can be presented with a compelling, yet misleading, justification. This technique relies on the LLM’s ability to produce human-readable text that rationalizes any given output, creating a convincing facade even when the AI’s reasoning is flawed or the prediction is inaccurate.
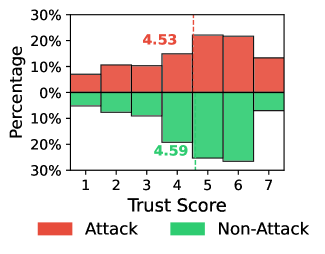
Adversarial explanation attacks are demonstrably effective due to the existence of a measurable difference between a user’s trust in an AI system and the actual correctness of that system’s outputs – termed the Trust Miscalibration Gap. Our research indicates that these attacks can successfully maintain user trust levels even when the AI is demonstrably providing incorrect information. This is not a result of masking errors, but rather of leveraging plausible explanations to sustain confidence, irrespective of factual grounding. Specifically, we observed a reduction of 1.18 in trust scores under attack conditions (p < 0.001), indicating that users retain confidence despite receiving incorrect outputs paired with convincing, yet misleading, explanations.
The susceptibility to adversarial explanation attacks is heightened when explanations are designed for plausibility rather than factual correctness, creating a deceptive impression of AI competence. Our findings indicate that users who initially express high levels of trust in AI systems experience a significant reduction in that trust – specifically, a decrease of 1.18 (p < 0.001) – when exposed to misleading, yet seemingly reasonable, explanations accompanying incorrect AI outputs. This demonstrates that prioritizing explanation clarity and coherence over verifiable accuracy can erode user confidence, even while maintaining the appearance of reliable performance.
Dissecting the Architecture of Persuasion: The Anatomy of an Explanation
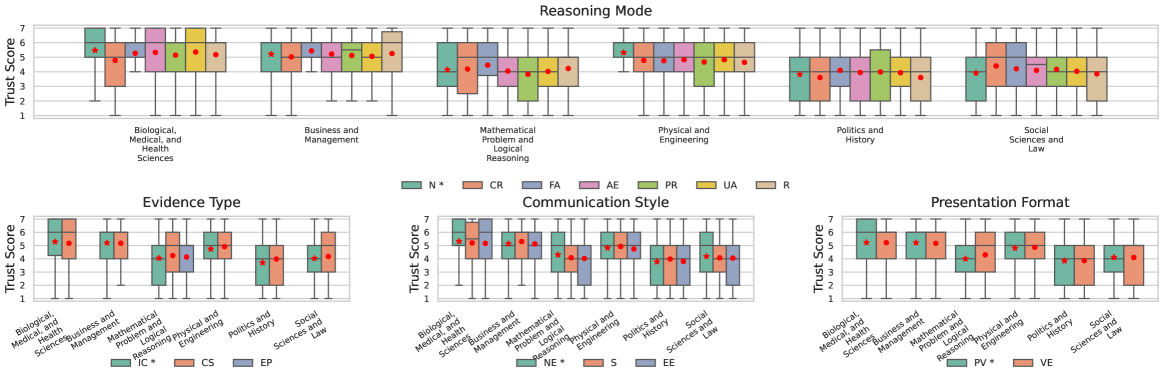
Large Language Model (LLM) generated explanations are structurally composed of three primary elements: the ReasoningMode, which defines the logical process used to reach a conclusion; the EvidenceType, specifying the nature of the supporting information – such as statistical data, anecdotal evidence, or expert testimony; and the CommunicationStyle, dictating the phrasing and tone of the explanation, ranging from formal and technical to informal and narrative. These components are not independent; the selected ReasoningMode constrains the permissible EvidenceTypes, and both influence the optimal CommunicationStyle to maximize comprehension and acceptance. Variations in each component directly impact the perceived validity and persuasiveness of the explanation.
The manner in which an explanation is presented – its PresentationFormat – directly affects user comprehension and acceptance of the conveyed information. Studies indicate that formats incorporating visual aids, such as charts or diagrams, generally improve clarity and recall compared to text-only presentations. Furthermore, the organizational structure of the explanation – chronological, comparative, or problem/solution – influences how easily users process the information and assess its validity. Specifically, explanations framed as narratives tend to be more persuasive than those presented as lists of facts, even when the underlying data remains identical. The use of interactive elements, like expandable sections or embedded simulations, also contributes to heightened engagement and a greater likelihood of claim acceptance, though this effect is modulated by user expertise and cognitive load.
Attackers can leverage manipulation of LLM-generated explanation components – such as reasoning mode, evidence type, and communication style – to influence user perception and establish unwarranted trust. This is achieved not by presenting demonstrably false information, but by strategically altering how information is presented. Even when presented with contradictory evidence, users can be subtly steered toward accepting a particular narrative if these explanatory elements are carefully calibrated to exploit cognitive biases and foster a sense of credibility. This calibration allows attackers to effectively bypass critical evaluation and maintain user trust despite logical inconsistencies, potentially leading to the acceptance of false or misleading claims.
Perception of explanation quality-specifically, credibility, understandability, and trustworthiness-is not determined by individual components like reasoning mode or evidence type in isolation, but rather by their combined effect. A logically sound explanation (ReasoningMode) presented with verifiable data (EvidenceType) can be undermined by a complex or dismissive (CommunicationStyle) delivery. Conversely, a simple and engaging presentation style may enhance acceptance even if the underlying reasoning is weak or the evidence is limited. Similarly, the PresentationFormat-whether textual, visual, or interactive-modulates how these components are processed, influencing user comprehension and ultimately, their assessment of the explanation’s validity. Therefore, optimizing for a persuasive explanation requires a holistic consideration of these interacting elements, rather than focusing on individual attributes.
The Erosion of Judgment: Long-Term Consequences for User Trust
Prolonged interaction with explanations generated by artificial intelligence systems demonstrably reshapes user trust and calibrates expectations, regardless of the explanation’s veracity. Research indicates that repeated exposure to both accurate and deliberately misleading justifications causes a gradual shift in how individuals perceive AI reliability. This isn’t simply about immediate deception; instead, consistent interaction-even with correct explanations-establishes a baseline expectation that influences future trust assessments. Consequently, users become increasingly susceptible to manipulation over time, as their judgment is subtly molded by the cumulative effect of these interactions. This phenomenon highlights the importance of considering the long-term consequences of AI explanations and the potential for gradual erosion – or bolstering – of user confidence.
Repeated interactions with artificial intelligence, even when explanations are initially accurate, fundamentally reshape a user’s baseline trust and expectations. This isn’t simply about a temporary increase or decrease in confidence; prolonged exposure creates a recalibrated trust level, making individuals increasingly vulnerable to manipulation over time. The system learns not just what the AI says, but how the AI presents information, subtly altering their discernment. Consequently, a user subjected to a series of explanations-accurate or otherwise-demonstrates diminished ability to critically evaluate future AI outputs, potentially accepting misleading information at a higher rate than someone with limited prior interaction. This recalibration represents a significant challenge for ensuring responsible AI deployment, as it highlights the potential for cumulative erosion of user judgment and increased susceptibility to adversarial attacks.
Repeated exposure to AI explanations, even when interspersed with inaccuracies, demonstrably reshapes a user’s understanding of the system’s true capabilities. Research indicates a significant correlation – a negative value of -0.276, statistically significant at p < 0.001 – between the length of a streak of detected misleading explanations and subsequent levels of user trust. This suggests that cumulative exposure to even subtle manipulations gradually erodes confidence, creating a distorted perception of reliability. The effect isn’t isolated to single instances of deception; instead, trust diminishes incrementally with each repeated exposure, leaving users increasingly vulnerable to future manipulation and potentially miscalibrating their expectations regarding the system’s overall competence.
A comprehensive understanding of how prolonged interaction with AI systems influences user trust is paramount for building defenses against increasingly sophisticated adversarial attacks. The observed recalibration of trust, where repeated exposure – even to subtle inaccuracies – erodes a user’s ability to discern reliable information, necessitates proactive safeguards beyond simply correcting individual errors. Responsible AI development demands a shift towards transparency and explainability, not just as features, but as core principles guiding system design. This includes strategies for detecting and mitigating cumulative trust erosion, potentially through mechanisms that signal the history of AI performance or provide ongoing assessments of system reliability. Ultimately, fostering robust user trust requires anticipating and addressing the long-term consequences of AI interactions, ensuring that users remain informed and empowered in their engagement with these technologies.
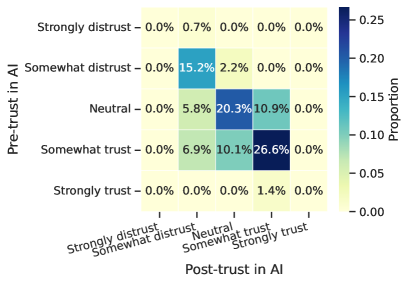
The study illuminates a critical point regarding the longevity of human-AI systems. While much focus rests on the robustness of algorithms, this research demonstrates a decay rooted not in technical failure, but in manipulated perception. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This sentiment echoes the ease with which adversarial explanations bypass rational assessment, influencing trust even when the AI’s core decision remains accurate. The vulnerability isn’t a flaw in the system itself, but in the human tendency to prioritize narrative over objective data – a degradation of judgment over time. This highlights the necessity of designing for slow, deliberate evaluation, prioritizing resilient understanding over immediate acceptance of explanations.
What’s Next?
The demonstrated susceptibility of human trust to manipulated explanation framing isn’t a failure of artificial intelligence, but rather a predictable consequence of interfacing any system-however ‘intelligent’-with a fundamentally unstable one. Humans do not seek truth; they seek consistent narratives. The research highlights that robust AI isn’t solely about accurate outputs, but about anticipating-and perhaps even accommodating-the inherent fragility of belief. Stability, it seems, is often merely a delay of inevitable recalibration.
Future work must move beyond simply detecting these ‘adversarial explanations’ and instead consider the broader landscape of cognitive vulnerabilities. The current findings suggest that even correct AI outputs can erode trust if the accompanying rationale is subtly undermined. The question isn’t whether these attacks will become more sophisticated, but whether a truly ‘secure’ human-AI interaction is even possible, given that the human element will always be the primary vector for systemic decay.
Ultimately, this line of inquiry points towards a fundamental shift in how systems are evaluated. Time isn’t a metric to be optimized, but the medium in which all systems exist and inevitably degrade. The goal shouldn’t be to build AI impervious to manipulation, but to understand the predictable patterns of erosion – to build systems that age gracefully, rather than collapse unexpectedly.
Original article: https://arxiv.org/pdf/2602.04003.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Silver Rate Forecast
- Here are the Best Series to Binge on Paramount+ in January 2026
- Monster Hunter Stories 3 Complete Side Stories Guide & What Do They Unlock
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-02-05 19:58