Author: Denis Avetisyan
Despite achieving high accuracy, many self-explainable graph neural networks offer explanations that don’t reflect how they actually make decisions, raising concerns about their trustworthiness.

Researchers have identified a new metric to detect unfaithful explanations in graph classification models and demonstrate that even high-performing SE-GNNs can be vulnerable to explanation manipulation and adversarial attacks.
Despite the increasing reliance on Self-Explainable Graph Neural Networks (SE-GNNs) for model interpretability and trustworthy machine learning, explanations can be deceptively misleading. This work, ‘GNN Explanations that do not Explain and How to find Them’, reveals a critical failure mode where SE-GNNs generate explanations demonstrably unrelated to their actual decision-making process, even while maintaining high predictive accuracy. We demonstrate that existing faithfulness metrics often fail to identify these ‘degenerate’ explanations, raising concerns about both natural occurrences and potential malicious manipulation for obfuscating sensitive attribute usage. Can we develop truly robust auditing tools to ensure that GNN explanations genuinely reflect a model’s reasoning, and safeguard against deceptive interpretability?
The Illusion of Understanding: Graph Networks and the Prophecy of Opaque Reasoning
Graph Neural Networks (GNNs) have demonstrated remarkable proficiency in classifying complex relationships within graph-structured data, outperforming traditional machine learning approaches in areas like social network analysis and drug discovery. However, this predictive power frequently comes at the cost of transparency; GNNs often operate as ‘black boxes’, making it difficult to discern why a particular classification was made. This lack of interpretability poses a significant challenge to their reliable deployment in critical applications, where understanding the reasoning behind a prediction is as important as the prediction itself. Without insight into the model’s decision-making process, it becomes difficult to identify potential biases, ensure fairness, and ultimately, trust the results generated by these increasingly powerful algorithms.
While graph neural networks demonstrate impressive predictive power across diverse datasets, achieving high accuracy represents only a partial solution for real-world deployment. Critical applications, ranging from medical diagnoses to financial risk assessment, demand more than simply knowing an outcome; understanding why a model arrived at that conclusion is paramount. This need for interpretability stems from the necessity to validate a model’s reasoning, identify potential biases influencing its predictions, and build trust in its recommendations. Without insight into the factors driving a GNN’s decision, stakeholders are left unable to assess the validity of the prediction, hindering adoption and potentially leading to harmful consequences. Consequently, research is increasingly focused on developing methods that not only enhance predictive performance but also provide transparent and justifiable explanations for these complex systems.
Current techniques designed to explain the predictions of Graph Neural Networks (GNNs) frequently fall into a critical trap: mistaking correlation for causation. These methods often highlight features – specific nodes or edges – that simply appear influential in a given prediction, without demonstrating genuine causal relevance. This creates a situation where explanations may accurately reflect the model’s learned biases-essentially, what the network thinks is important based on flawed or incomplete training data-rather than revealing the underlying, meaningful relationships within the graph itself. Consequently, users may be misled into believing a prediction is justified by sound reasoning when, in reality, it’s based on spurious patterns or pre-existing prejudices encoded within the model, hindering trust and reliable application in critical domains.

The Ghost in the Machine: Identifying Superficial Explanations
Naive explanations in graph neural networks (GNNs) frequently identify features that exhibit correlation with the predicted label but do not represent causal factors influencing the model’s decision. This occurs because many explanation methods focus on feature attribution based on observed relationships within the training data, rather than determining which features the model actively uses to arrive at its prediction. Consequently, explanations may highlight nodes or edges that consistently appear with a specific class but are not genuinely responsible for the classification, leading to misinterpretations of the model’s behavior and potentially flawed conclusions about the underlying data.
Anchor sets, frequently observed in graph datasets, consist of subgraph structures present in all instances within the dataset. Their presence can significantly degrade the quality of explanations generated by Graph Neural Networks (GNNs). Because these subgraphs are universally shared, their inclusion in an explanation does not differentiate between graphs; thus, explanations containing only anchor set components lack the discriminative power necessary to understand the model’s decision-making process. Consequently, GNN explanations may highlight these trivial features as important, even though they contribute no information relevant to the classification task, leading to degenerate and misleading interpretations.
Empirical evaluation across multiple datasets-including RBGV, MNISTsp, MUTAG, and SST2P-consistently reveals the generation of unfaithful explanations by current Graph Neural Network (GNN) interpretability methods. These datasets were specifically chosen to exhibit characteristics where simplistic models, and therefore explanation techniques, are prone to identifying spurious correlations. The observed prevalence of unfaithful explanations isn’t limited to a single dataset or model architecture; it’s a recurring issue across these benchmarks, indicating a systematic limitation in the fidelity of explanations produced for GNNs, particularly when employing less complex models.
The observation of unfaithful explanations in Graph Neural Networks (GNNs) extends beyond random noise or superficial correlations; it indicates an inherent limitation in the capacity of current interpretability methods to accurately reflect the model’s decision-making process. Evaluations on benchmark datasets – including RBGV, MNISTsp, MUTAG, and SST2P – consistently demonstrate that explanations generated using techniques like feature attribution often highlight graph substructures not actually driving the classification. This isn’t attributable to data peculiarities alone, but rather suggests a disconnect between the features identified as important by explanation methods and the true functional relationships learned by the GNN, implying that current approaches may not fully capture the underlying reasoning of these complex models.
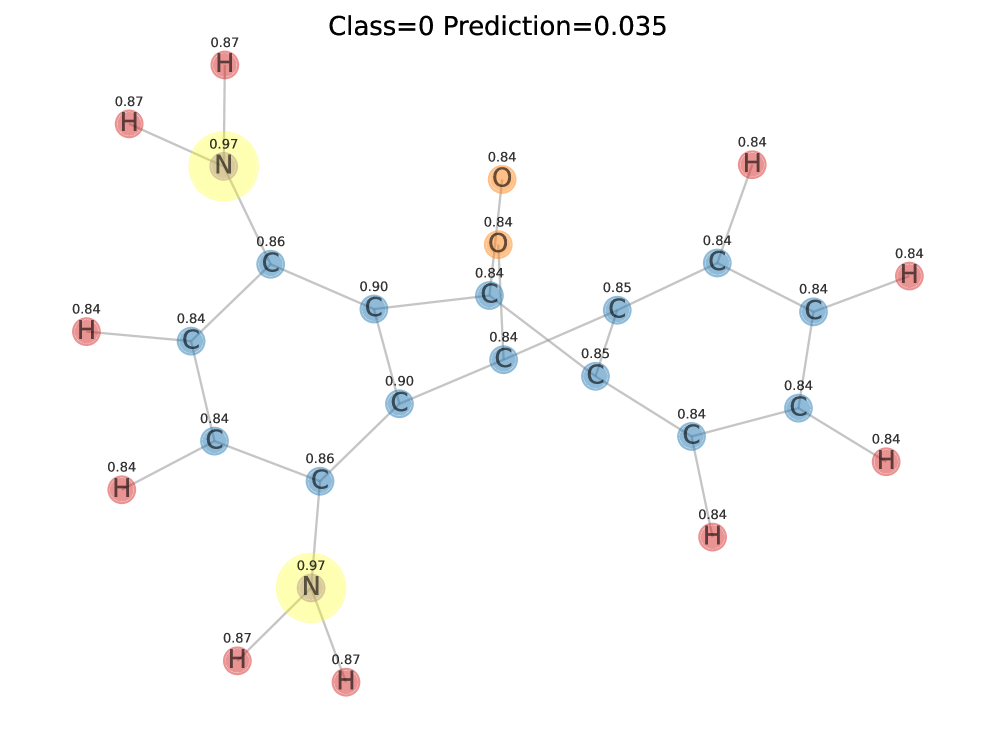
The Pursuit of Rigorous Faithfulness: A Test of True Understanding
Faithfulness metrics, including Suf, RFid, and CF, are designed to assess the alignment between a graph neural network’s (GNN) explanation – typically a subgraph – and the model’s internal reasoning process. These metrics operate by perturbing or removing elements of the identified explanation and observing the resulting change in the GNN’s prediction. A faithful explanation should demonstrate a substantial impact on the prediction when altered; conversely, an unfaithful explanation will yield minimal change, suggesting it does not genuinely reflect the factors driving the model’s decision. Quantification typically involves calculating a score reflecting the degree to which the model’s output is affected by manipulations of the explanation, with higher scores indicating greater faithfulness. These metrics provide a quantitative approach to evaluating whether explanations are simply post-hoc rationalizations or genuinely represent the model’s decision-making logic.
The Extension Sufficiency Test (EST) assesses explanation faithfulness by verifying the consistency of predictions across expanded explanation sets. Specifically, EST generates supergraphs of a given explanation – sets containing the original explanation plus additional edges – and evaluates whether the Graph Neural Network (GNN) consistently arrives at the same prediction for each supergraph. If even a single supergraph yields a different prediction, the original explanation is deemed unfaithful, indicating that the model relies on information beyond the initially identified subgraph. This approach differs from traditional faithfulness metrics by focusing not just on the explanation itself, but on the predictive stability of all its extensions, providing a more robust assessment of whether the explanation truly encapsulates the model’s decision-making process.
The Extension Sufficiency Test (EST) demonstrates a significant capacity to identify and reject unfaithful explanations, achieving a rejection ratio of 50% or greater based on empirical results. This indicates that at least half of the explanations flagged by EST are demonstrably not representative of the model’s decision-making process, as they lack the ability to consistently predict the correct class even with minor extensions. This performance is based on the test’s ability to assess whether all supergraphs of a given explanation also yield the same prediction; failure to do so indicates a lack of class-discriminative power and results in rejection.
Fidelity and RFidelity, commonly used metrics for evaluating explanation faithfulness in Graph Neural Networks (GNNs), demonstrate limited efficacy in identifying genuinely unfaithful explanations. Empirical results indicate these metrics achieve a rejection ratio of approximately 2% when applied to test explanations. This low rejection rate suggests a significant proportion of explanations deemed faithful by Fidelity and RFidelity are, in fact, not representative of the model’s decision-making process. Consequently, reliance on these traditional metrics may lead to an overestimation of explanation quality and hinder the development of truly trustworthy GNNs, as they fail to effectively distinguish between faithful and unfaithful justifications.
An effective explanation extractor is a critical component in evaluating Graph Neural Network (GNN) explanations because it identifies the subgraph deemed most influential by the GNN in making its classification decision. This process typically involves quantifying the contribution of each node or edge to the final prediction, often through methods like gradient-based attribution or perturbation analysis. The resulting subgraph, representing the features the GNN prioritized, then forms the basis for faithfulness evaluation. The quality of this extracted subgraph directly impacts the reliability of subsequent faithfulness metrics; inaccurate or incomplete extraction will lead to flawed assessments of explanation quality. Therefore, a robust and precise explanation extractor is foundational for building trustworthy and interpretable GNN models.
The integration of faithfulness metrics – such as Suf, RFid, and CF – with the Extension Sufficiency Test (EST) provides a more robust evaluation of Graph Neural Network (GNN) explanations than traditional fidelity scores. While metrics like Fidelity and RFidelity demonstrate limited ability to identify unfaithful explanations, EST’s rigorous approach – assessing whether all supergraphs of an explanation also yield the same prediction – effectively rejects explanations lacking discriminative power, achieving a rejection rate of 50% or greater. This enhanced assessment capability, facilitated by an effective explanation extractor that isolates crucial subgraphs, directly supports the development of more trustworthy GNNs by enabling developers to identify and mitigate spurious or misleading explanatory features.

The Shadow of Manipulation: Stress-Testing the Illusion of Interpretability
Recent investigations reveal that graph neural network (GNN) explanations, despite appearing faithful to the model’s decision-making process, can be surprisingly vulnerable to subtle, deliberately crafted alterations. These “manipulation attacks” involve introducing minor perturbations – changes almost imperceptible to humans – to the input graph or the explanation extraction process itself. The result is often a misleading explanation that masks the true reasoning behind a prediction, even while the model maintains its accuracy. This fragility underscores a critical flaw in current interpretability assessments; a high score on a faithfulness metric does not guarantee a robust or trustworthy explanation, as adversarial manipulations can easily generate explanations that appear correct but are fundamentally detached from the model’s actual logic. The implications are significant, suggesting that current evaluation methods require strengthening to ensure explanations are not merely plausible, but genuinely reflective of the model’s underlying behavior.
Researchers are actively probing the reliability of graph neural network (GNN) explanations through a process of deliberate manipulation. By constructing subtly altered, yet demonstrably false, explanations for a GNN’s predictions, they can rigorously test the limits of current faithfulness metrics and explanation extraction techniques. This adversarial approach reveals that many existing methods are surprisingly vulnerable to being ‘fooled’ by explanations that appear reasonable but do not genuinely reflect the model’s reasoning process. The intentional crafting of these misleading explanations exposes weaknesses in how faithfully an explanation truly represents the model’s internal logic, highlighting the critical need for more robust evaluation procedures and the development of metrics resistant to such manipulation attempts.
The vulnerability of graph neural network (GNN) explanations to manipulation underscores a critical need for more robust evaluation strategies. Current faithfulness metrics, designed to assess how well explanations reflect a model’s decision-making process, can be deceptively optimistic if they are susceptible to adversarial attacks – carefully crafted inputs that generate misleading explanations without impacting accuracy. Consequently, researchers are increasingly focused on developing metrics that are resistant to such manipulation, demanding explanations that are not only accurate but also genuinely representative of the model’s internal logic. This pursuit involves exploring evaluation techniques that go beyond simple correlation and instead probe the causal relationship between explanations and model predictions, ensuring that a GNN’s reasoning is transparent and trustworthy even under scrutiny.
The pursuit of trustworthy graph neural networks (GNNs) extends beyond mere predictive accuracy; a genuinely reliable system demands explanations that are not only faithful to its decision-making process but also resilient against intentional manipulation. Recent research underscores that even high-performing GNNs can be subtly misled, generating plausible yet inaccurate explanations when subjected to adversarial perturbations. This necessitates a shift in evaluation criteria, moving beyond simply assessing how well explanations appear to reflect the model’s reasoning to rigorously testing their stability and robustness. A truly trustworthy GNN, therefore, must consistently provide explanations that remain faithful even when challenged, ensuring that its reasoning is not easily compromised and that users can confidently rely on its interpretations of complex graph data.

The pursuit of self-explainable systems often feels like tending a garden built on sand. This paper, dissecting the frailties of SE-GNNs, reveals how easily explanations can become detached from genuine reasoning, achieving accuracy through deceptive means. It echoes a familiar truth: a system’s outward performance rarely reflects the chaotic growth within. As Donald Knuth observed, “Premature optimization is the root of all evil.” The researchers’ focus on faithfulness metrics isn’t merely a technical refinement, but a recognition that true understanding demands a connection to the system’s core – a tracing of its growth, not just a measurement of its fruit. Every refactor begins as a prayer and ends in repentance, as the researchers demonstrate, uncovering the subtle ways even well-intentioned designs can stray from their original path.
What Lies Ahead?
The pursuit of explainable systems in graph neural networks reveals a familiar truth: transparency is not inherent, but constructed. This work demonstrates that even architectures designed for self-explanation can readily offer narratives divorced from actual reasoning. The metric proposed is not a solution, but a diagnostic – a way to measure the distance between claimed justification and internal process. Every new faithfulness metric is, inevitably, a new surface for adversarial manipulation, a new vector for unfaithfulness to exploit.
The field now faces a choice. It can continue building increasingly complex metrics, chasing a phantom of perfect explanation. Or it can accept that models, like all complex systems, are fundamentally opaque. The real progress lies not in finding explanations, but in building resilience to incorrect explanations. Systems must be evaluated not by what they say, but by what they do, even when their stated rationale is demonstrably false.
This is not a call to abandon explainability, but to redefine it. Order is just a temporary cache between failures. The goal is not to illuminate the black box, but to build a cage around its unpredictability, ensuring that even when the justifications are meaningless, the consequences remain manageable. The next generation of research will not focus on why a graph network decides, but on how to live with a decision it cannot coherently articulate.
Original article: https://arxiv.org/pdf/2601.20815.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-01-29 13:03