Author: Denis Avetisyan
A new benchmark dataset reveals that existing deepfake detection methods are increasingly vulnerable to highly realistic videos generated by advanced AI models.
SynthForensics introduces a comprehensive evaluation protocol and dataset to assess the robustness of deepfake detection techniques against emerging threats from text-to-video generation.
Existing deepfake detection benchmarks are increasingly inadequate given the rapid advancement of text-to-video (T2V) generation, which now produces synthetic content nearly indistinguishable from reality. To address this critical gap, we introduce SynthForensics: A Multi-Generator Benchmark for Detecting Synthetic Video Deepfakes, comprising a large-scale, human-validated dataset of 6,815 videos generated by five state-of-the-art, open-source T2V models, and available in multiple compression qualities. Our evaluation reveals that current detectors exhibit significant fragility and limited generalization on this new domain, with performance dropping by a mean of 29.19\% AUC and some methods failing to surpass random chance. Can training on more comprehensive benchmarks like SynthForensics offer a path toward robust and reliable detection of these increasingly sophisticated synthetic media threats?
The Evolving Landscape of Synthetic Reality
The landscape of visual media is undergoing a profound shift as text-to-video (T2V) models demonstrate accelerating capabilities. Recent advancements allow these systems to generate strikingly realistic video content solely from textual descriptions, moving beyond simple animations to convincingly simulate human actions, diverse environments, and complex scenarios. This progress isn’t merely incremental; the fidelity and coherence of synthetically produced videos have improved dramatically in a short period, blurring the lines between captured reality and artificial creation. Consequently, videos once requiring extensive filming and post-production can now be rendered digitally with increasing ease and at a decreasing cost, presenting both exciting possibilities and significant challenges for authenticating visual information.
Current deepfake detection systems were largely built and tested using datasets like DFDC, FaceForensics++, and Celeb-DF, which primarily feature videos of real individuals whose appearances have been altered. These benchmarks assess a detector’s ability to identify manipulations within existing footage – swapping faces, altering expressions, or adding subtle distortions. However, this approach overlooks a rapidly growing threat: videos generated entirely from scratch using text-to-video models. Consequently, detectors trained on manipulated real videos struggle with purely synthetic content, as they haven’t learned to identify the unique artifacts and inconsistencies inherent in entirely artificial creations. This fundamental mismatch in training data presents a significant challenge, leaving existing systems vulnerable to a new wave of sophisticated, entirely fabricated visual misinformation.
Current deepfake detection systems, honed on identifying manipulations within existing video footage, are proving surprisingly ineffective against a new wave of entirely synthetic content. Evaluations reveal a significant performance drop – achieving only 50-58% Area Under the Curve (AUC) – when these detectors are challenged with videos generated solely from text prompts. This discrepancy, termed a ‘domain gap’, highlights a fundamental limitation: existing algorithms are trained to spot artifacts introduced by manipulation, not the inherent characteristics of content created from scratch. Consequently, a growing vulnerability exists as text-to-video technologies mature, capable of producing increasingly realistic fabricated visuals that easily evade current detection methods and threaten the reliability of visual information.
The proliferation of highly realistic, synthetically generated videos presents a growing threat to the integrity of visual information and, consequently, to public trust. As text-to-video technologies rapidly mature, the ability to fabricate convincing yet entirely false scenarios becomes increasingly accessible, potentially fueling the spread of misinformation and eroding confidence in authentic visual evidence. Without robust detection methods capable of discerning between genuine and synthetic content, society risks a future where discerning truth from fabrication becomes exceptionally difficult, impacting everything from news reporting and legal proceedings to personal reputations and democratic processes. Bridging the detection gap is therefore not merely a technical challenge, but a crucial step in safeguarding the reliability of visual media and preserving a shared understanding of reality.

SynthForensics: A Benchmark for the Synthetic Age
SynthForensics represents a new benchmark specifically constructed for the evaluation of deepfake and manipulated media detection systems when applied to entirely synthetic video content. Existing benchmarks often rely on blends of real and synthetic material, which can introduce confounding factors in evaluation; SynthForensics addresses this limitation by focusing solely on videos generated through algorithmic processes. This targeted approach allows for a more precise assessment of a detector’s ability to identify artifacts and inconsistencies inherent in purely synthetic content, offering a clearer understanding of performance characteristics in the context of increasingly sophisticated generative models. The benchmark’s design facilitates the isolation and quantification of detector sensitivity to synthetic characteristics, independent of issues related to real video processing or blending artifacts.
The SynthForensics benchmark utilizes a paired-source methodology wherein existing real video footage serves as the foundation for generating synthetic counterparts. This approach establishes a direct semantic link between the real and synthetic data, ensuring that the generated videos maintain consistency in terms of actions, objects, and scenes. By anchoring the synthetic generation process to real-world video, the benchmark mitigates the risk of producing unrealistic or semantically incoherent synthetic content, which is critical for robust detector evaluation and allows for precise assessment of a detector’s ability to identify manipulations rather than simply flagging unusual content.
The SynthForensics benchmark utilizes a variety of text-to-video (T2V) generation models to create a diverse dataset of synthetic videos. Currently, the framework incorporates Wan2.1, CogVideoX, and SkyReels-V2, each representing differing architectural approaches and capabilities in video synthesis. Employing multiple T2V models is critical to ensure the robustness of detector evaluation, as it exposes detectors to a wider range of potential synthetic artifacts and generation styles. This diversity aids in assessing whether a detector generalizes well beyond the specific characteristics of any single generative model and improves its capacity to identify synthetic content created by unseen or future T2V technologies.
SynthForensics integrates a human validation stage to guarantee the semantic accuracy of generated synthetic videos and address potential ethical concerns related to content manipulation. This process involves human annotators assessing the correspondence between the original real videos and their synthetic counterparts, ensuring that the generated content maintains a consistent meaning and does not introduce harmful or misleading information. This rigorous evaluation allows detectors trained on SynthForensics to achieve Area Under the Curve (AUC) scores up to 99.99% when identifying synthetic videos created by in-domain text-to-video (T2V) models, specifically Wan2.1, CogVideoX, and SkyReels-V2.
The Architectural Evolution of Synthetic Generation
Contemporary text-to-video (T2V) models demonstrate a shift from convolutional U-Net architectures to diffusion transformers to enhance spatio-temporal coherence in generated video. U-Nets, while effective in initial generative models, exhibit limitations in capturing long-range dependencies crucial for realistic motion and consistent scene understanding. Diffusion transformers leverage the attention mechanisms inherent in transformer networks, allowing the model to directly relate distant frames and features, resulting in improved temporal consistency and a reduction in artifacts common in U-Net based approaches. This architectural change allows for more effective modeling of video dynamics and facilitates the generation of visually plausible and coherent video sequences.
Diffusion models operate by progressively adding Gaussian noise to data – images or videos – until it resembles pure noise, and then learning to reverse this process to generate new samples. This iterative refinement is achieved through a series of denoising steps, each subtly improving the quality of the generated output. The number of these steps directly impacts fidelity; a greater number of steps typically results in higher-quality, more detailed outputs, but also increases computational cost. This process differs from single-step generation methods and provides a stable training procedure, addressing limitations observed in earlier generative models. Consequently, diffusion models establish a robust foundation for subsequent architectural innovations like diffusion transformers.
Generative Adversarial Networks (GANs) represented an early breakthrough in generative modeling, utilizing a two-network system – a generator and a discriminator – to produce synthetic data. However, GAN training is notoriously unstable, often resulting in oscillations or complete failure to converge. A significant problem was ‘mode collapse’, where the generator learns to produce only a limited variety of samples, failing to capture the full diversity of the training data distribution. Diffusion models address these issues by employing a forward diffusion process that gradually adds noise to data, followed by a learned reverse process to reconstruct the original data. This approach provides greater training stability and mitigates mode collapse by learning a more robust and complete representation of the data distribution, leading to higher-quality and more diverse generated samples.
The evolving architectures of generative models – specifically the shift from GANs to diffusion models and now diffusion transformers – introduce distinct artifacts and patterns into synthetic video content. These “fingerprints” stem from the underlying mathematical processes and implementation details of each architecture; for example, diffusion transformers inherently exhibit specific frequency-domain characteristics due to their reliance on attention mechanisms. Consequently, effective detection strategies must be tailored to recognize these unique signatures, moving beyond generic anomaly detection to focus on architecture-specific vulnerabilities. Analyzing the noise patterns, frequency distributions, and temporal coherence properties generated by each model type allows for the development of targeted forensic techniques, improving the accuracy and robustness of synthetic video detection systems.

Evaluating Detection: From Fine-Tuning to Zero-Shot Resilience
SynthForensics provides a uniquely versatile platform for rigorously testing methods designed to identify synthetic videos, accommodating a broad spectrum of training paradigms. Researchers can assess detector performance starting with readily available pre-trained models, subtly adapted through fine-tuning to recognize telltale signs of manipulation. Alternatively, the benchmark facilitates a more exhaustive evaluation by enabling training from a completely blank slate, allowing for a deeper understanding of what features a detector learns to associate with synthetic content. This flexibility is crucial, as it moves beyond simply measuring if a detector works, to understanding how it works and what foundational approaches yield the most robust results across diverse synthetic generation techniques, ultimately pushing the boundaries of forgery detection capabilities.
A detector’s ability to accurately identify synthetic videos it hasn’t encountered during training-its zero-shot performance-represents a crucial test of its true generalization capability. SynthForensics leverages this concept by evaluating how well detection strategies perform on unseen synthetic content, offering a stringent measure beyond simply recognizing videos generated by the same models used for training. This is particularly important as synthetic media generation rapidly evolves; a detector strong on today’s techniques may quickly falter when faced with novel generation methods. Consequently, zero-shot results on benchmarks like SynthForensics provide a more realistic assessment of a detector’s long-term robustness and adaptability, highlighting its capacity to maintain accuracy in the face of ever-changing synthetic media landscapes.
The creation of robust synthetic data for deepfake detection traditionally relies on manual prompt engineering, a process prone to inconsistency and bias. SynthForensics addresses this challenge by leveraging Vision-Language Models (VLMs) to automate and standardize the generation of prompts used to create synthetic videos. This approach allows researchers to exert precise control over the characteristics of the generated content – specifying details like lighting, pose, and expression – resulting in datasets with greater consistency and reproducibility. By systematically varying these parameters through VLM-generated prompts, the benchmark facilitates a more rigorous evaluation of detection algorithms, revealing their sensitivities to specific types of manipulations and enabling targeted improvements in their generalization capabilities. This controlled methodology moves beyond arbitrary data creation, providing a pathway to more reliable and interpretable results in the ongoing effort to combat the spread of manipulated media.
SynthForensics offers a uniquely controlled environment for dissecting the performance of synthetic video detection methods, revealing significant vulnerabilities even in state-of-the-art systems. Analysis of Equal Error Rates (EER) demonstrates a wide spectrum of performance, from near-perfect detection (0.00%) on certain generated content to a notable 20.00% error rate depending on the specific generator employed. While detectors achieve impressive Average Precision (AP) scores – peaking at 99.99% when tested on generators similar to their training data – performance plummets to just 51.77% when challenged with the more complex MAGI-1 generator utilizing the GenConViT model, highlighting a critical gap in generalization ability and the need for more robust detection strategies.
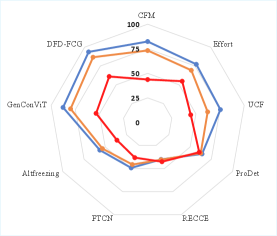
The SynthForensics benchmark, with its focus on rigorously evaluating deepfake detection across multiple generative models, highlights a fundamental truth about any system built upon complexity. It isn’t merely about identifying flaws, but acknowledging their inevitable emergence. As Henri Poincaré observed, “Mathematics is the art of giving reasons.” This pursuit of reasoned understanding is vital when dealing with rapidly evolving synthetic media. The study reveals that existing detection methods struggle with high-fidelity deepfakes, demonstrating the fragility of solutions when faced with unforeseen advancements. The benchmark’s multi-generator approach acknowledges that a system’s robustness isn’t determined in isolation, but by its resilience across a diverse range of potential challenges. SynthForensics, therefore, isn’t simply a dataset; it’s a necessary calibration against the entropic forces inherent in technological progress.
What’s Next?
The introduction of SynthForensics is less a resolution than a carefully documented accrual of debt. Every commit in the annals of deepfake detection now bears the weight of this new benchmark, each version a chapter revealing the limitations of prior approaches. The dataset doesn’t solve the problem of synthetic video detection; it exposes a widening gap between the ambition of generative models and the robustness of forensic techniques. Existing methods, it turns out, were largely optimizing for a phantom menace – a past iteration of the technology.
Future work, inevitably, will focus on bridging this divide. Yet, simply pursuing higher accuracy scores feels… transactional. A more fruitful path lies in acknowledging the inherent ephemerality of any such defense. Generative models will continue to evolve, and detection methods will perpetually play catch-up. The real challenge isn’t achieving perfect detection, but designing systems that degrade gracefully as the adversary adapts. Delaying fixes, in this context, is a tax on ambition.
The field must now consider not merely if a video is synthetic, but how – what specific generative process created it, and what subtle artifacts remain as fingerprints of that process. Such an approach shifts the focus from a binary classification to a more nuanced understanding of the synthetic video’s provenance – a history written in pixels, slowly eroding with each new generation.
Original article: https://arxiv.org/pdf/2602.04939.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Vecna’s Ultimate Goal on STRANGER THINGS 5 and How The Party Can Defeat Him
2026-02-08 06:49