Author: Denis Avetisyan
As deepfake technology rapidly evolves, current detection methods struggle to keep pace, creating a significant and growing vulnerability.

A new review highlights the widening gap between advanced generative models and the effectiveness of existing deepfake detection systems, emphasizing the urgent need for improved forensic techniques.
Despite rapid advances in deepfake detection, a widening performance gap persists between synthetic media generation and its discovery. This study, titled ‘Deepfake Synthesis vs. Detection: An Uneven Contest’, presents a comprehensive empirical analysis of state-of-the-art detection techniques-including human evaluation-challenged by cutting-edge synthesis methods like diffusion models and Neural Radiance Fields. Findings reveal a concerning trend: many detection models, and even human observers, struggle to reliably identify increasingly realistic deepfakes. As generative capabilities continue to accelerate, can detection methodologies be sufficiently refined to effectively counter this evolving threat to digital authenticity?
The Illusion of Reality: Deepfakes and the Erosion of Trust
The proliferation of convincingly realistic synthetic videos is driven by advancements in deepfake technology, particularly through the implementation of Generative Adversarial Networks (GANs). These systems employ a competitive process where two neural networks – a generator and a discriminator – iteratively refine their capabilities. The generator crafts synthetic content, while the discriminator attempts to distinguish it from authentic media. This continuous feedback loop results in increasingly sophisticated forgeries, blurring the lines between reality and fabrication. Early deepfakes were often characterized by visual artifacts, but contemporary GAN architectures, coupled with larger datasets and increased computational power, now produce synthetic videos capable of deceiving even trained observers. This rapid evolution presents significant challenges, not only in detecting manipulated content but also in understanding the broader implications for information integrity and public trust.
The proliferation of deepfake technology introduces substantial hurdles to verifying the authenticity of digital content and erodes public trust in online media. As synthetic videos become increasingly indistinguishable from reality, the potential for misinformation, reputational damage, and even political manipulation grows exponentially. Consequently, a pressing need exists for the development of sophisticated detection methods capable of discerning genuine footage from fabricated simulations. These methods must move beyond superficial analyses and incorporate techniques that evaluate subtle inconsistencies in visual and auditory cues, physiological signals, and contextual information. The challenge lies not only in creating algorithms that can accurately identify deepfakes but also in ensuring these systems remain resilient against evolving techniques employed by those creating synthetic media, demanding continuous innovation in the field of digital forensics.
Initial attempts to detect synthetic media, exemplified by techniques like TPSMM and FaceVid, established fundamental principles for identifying manipulated videos, but quickly proved insufficient as deepfake technology matured. These early methods struggled to discern the subtle inconsistencies introduced by increasingly realistic generative models. Interestingly, studies reveal a stark contrast in performance: while automated systems grapple with the nuances of deepfakes, human evaluators consistently demonstrate a remarkable ability to identify them, achieving a mean Area Under the Curve (AUC) of 93.10 and an Average Precision (AP) of 94.81. This highlights a substantial gap between current automated detection capabilities and human perceptual skills, suggesting that replicating human-level discernment remains a significant challenge in the ongoing effort to combat the spread of deceptive synthetic content.
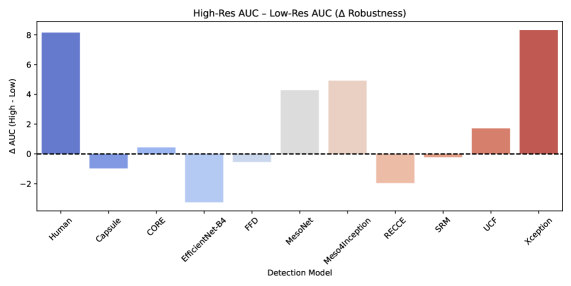
![Xception[22] and CORE[18] demonstrated the best deepfake detection performance across varying video lengths and resolutions, while human accuracy improved with resolution-a trend not consistently reflected in automated models like MesoNet[1] and Meso4Inception[1], which were sensitive to resolution changes, unlike the more stable RECCE[3] and UCF[32].](https://arxiv.org/html/2602.07986v1/x5.png)
The Rise of the Machines: Diffusion Models and Synthetic Fidelity
Diffusion models represent a current state-of-the-art approach to deepfake generation, distinguished by their iterative refinement process. Unlike Generative Adversarial Networks (GANs) which generate content in a single pass, diffusion models begin with random noise and progressively denoise it, guided by learned data distributions. This iterative process, involving multiple denoising steps, allows for the generation of highly detailed and realistic synthetic content. Models such as AniFaceDiff, DreamTalk, and DiffusedHeads leverage this principle to create deepfakes with improved visual fidelity and reduced artifacts compared to earlier techniques. The refinement process also allows for greater control over the generated content, enabling manipulation of attributes and expressions with increased precision.
Neural Radiance Fields (NeRFs) are increasingly integrated into diffusion-based deepfake generation pipelines, such as SyncTalk, to address limitations in 3D consistency and realistic lip-sync. Traditional 2D-based approaches often struggle to maintain a coherent 3D representation of the subject’s face, resulting in visual artifacts during head pose variations. NeRFs provide a volumetric scene representation that allows the model to synthesize views from arbitrary angles, ensuring a consistent 3D structure. By incorporating NeRFs, these methods can accurately model the subject’s facial geometry and render photorealistic lip movements synchronized with the target audio, resulting in more convincing and stable deepfake outputs.
Recent diffusion models, including VASA and FADM, demonstrate advanced capabilities in synthetic content generation, specifically through precise attribute control and the rendering of subtle facial expressions. Quantitative evaluation, using metrics such as the Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD), highlights the improved realism achieved by these models; AniFaceDiff, for example, attained an FID of 6.02 and FVD of 15.55. These scores indicate a statistically closer alignment to real image and video data when compared to earlier generative adversarial network (GAN)-based approaches like HyperReenact/GAN, which recorded an FID of 9.95 and FVD of 19.10, confirming diffusion models’ superior performance in generating high-fidelity synthetic content.
Beyond Pixels: Advanced Techniques in Deepfake Detection
The increasing sophistication of deepfake generation techniques presents a significant challenge to traditional detection methods. Early approaches relied heavily on identifying artifacts introduced during the generation process, often focusing on pixel-level inconsistencies or frequency domain anomalies. However, advancements in generative adversarial networks (GANs) and other deep learning architectures now produce synthetic content with increasingly photorealistic qualities, effectively minimizing these detectable artifacts. Consequently, detection strategies must move beyond simple pixel analysis and incorporate methods that assess higher-level features, such as semantic inconsistencies, physiological plausibility, and inconsistencies in identity or context, to reliably distinguish between authentic and manipulated media.
Convolutional Neural Networks (CNNs) form the basis of several deepfake detection architectures focused on efficient feature extraction. MesoNet employs a streamlined architecture to reduce computational cost while maintaining accuracy. XceptionNet utilizes depthwise separable convolutions to improve efficiency and performance compared to traditional CNNs. EfficientNet systematically scales network dimensions – depth, width, and resolution – using a compound coefficient to optimize both accuracy and computational efficiency. Capsule Networks represent a departure from standard CNNs by explicitly modeling hierarchical relationships between features and attempting to preserve spatial information, potentially improving robustness to pose variations and occlusions; however, their computational demands are typically higher than those of standard CNN architectures.
Contrastive learning techniques enhance deepfake detection by training models to create embeddings where real and fake content are mapped to distinct regions of a feature space. This is achieved by presenting the model with pairs of examples – real and fake – and optimizing the model to minimize the distance between embeddings of similar (both real or both fake) examples while maximizing the distance between dissimilar examples. By learning these discriminative features – focusing on subtle inconsistencies often imperceptible to the human eye – models can more effectively differentiate between authentic and manipulated media, even when faced with high-quality forgeries. The approach avoids explicit labeling of forgery artifacts, instead learning to recognize inherent differences in the data distribution between real and fake samples.
Current deepfake detection research, exemplified by the UCF and CoRe approaches utilizing disentanglement and representation consistency, aims to improve model generalization and robustness against unseen manipulations. Despite these advancements, automated detection performance remains significantly below human-level accuracy. The highest performing automated model, the FaceForensics++ detector (FFD), currently achieves an Area Under the Curve (AUC) of 69.38% when classifying deepfake videos. This contrasts sharply with the 93.10% AUC achieved by human evaluators performing the same task, highlighting a substantial gap in automated deepfake detection capabilities and indicating the continued need for more sophisticated algorithms.
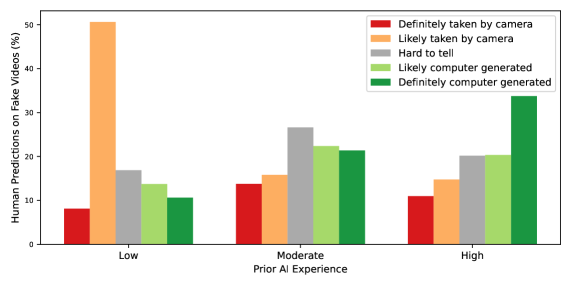
The Shifting Sands of Authenticity: Evaluating and Navigating the Deepfake Landscape
Evaluating the realism of generated content, such as deepfakes, relies heavily on quantitative metrics like Fréchet Inception Distance (FID) and Fréchet Video Distance (FVD). These metrics operate by comparing the distribution of features extracted from generated samples with those from real samples, using a pre-trained deep neural network. A lower FID or FVD score indicates a closer match between the distributions, suggesting higher realism and a more convincing forgery. Specifically, these distances measure the distance between the multivariate Gaussian distributions representing the features, effectively quantifying the statistical similarity between generated and authentic data. While subjective human evaluation remains crucial, FID and FVD provide objective, automated assessments, enabling researchers to track progress in generative model performance and benchmark different techniques for creating increasingly realistic synthetic media.
The proliferation of accessible deepfake software, such as FaceFusion, underscores a significant shift from theoretical possibility to readily available application. This tool empowers users to swap faces in videos with remarkable speed and, increasingly, realism – operating in real-time for live streams or immediate content creation. Beyond entertainment, this capability has implications for areas like virtual reality, personalized media, and even remote communication, allowing for dynamic avatar creation and manipulation. However, the ease with which convincing forgeries can now be produced also highlights the urgent need for robust detection methods and a broader understanding of the technology’s potential for misuse, demonstrating that the practical implications of deepfakes extend far beyond simple visual trickery.
Current investigations into deepfake technology are simultaneously refining the creation process and bolstering detection methods, tackling persistent challenges in realistically portraying nuanced expressions, faithfully preserving individual identities, and defending against deliberate attempts to mislead detection algorithms. Recent findings reveal a significant advantage for content generated via diffusion models; these exhibit a substantial Bayes Error Reduction – 39.5% for images and 18.6% for videos – implying an inherent difficulty in distinguishing them from authentic media compared to those created using Generative Adversarial Networks (GANs). This suggests a growing sophistication in deepfake creation, necessitating increasingly advanced and robust detection techniques to maintain the integrity of digital information and counter the potential for malicious use.
Addressing the challenges posed by increasingly sophisticated deepfake technology requires a comprehensive strategy extending beyond purely technical defenses. While advancements in detection algorithms are crucial, they are unlikely to remain ahead of evolving generative models indefinitely. Therefore, a robust solution necessitates bolstering media literacy among the public, equipping individuals with the critical thinking skills to question the authenticity of online content. Simultaneously, the development of ethical guidelines and potentially regulatory frameworks is essential to discourage malicious use and promote responsible innovation in this field. This multi-faceted approach – combining technological safeguards, informed citizenry, and ethical considerations – offers the most promising path toward mitigating the risks associated with deepfakes and fostering a more trustworthy information ecosystem.
The pursuit of deepfake detection feels increasingly like chasing shadows. This research confirms a troubling asymmetry; generative models, particularly those leveraging diffusion techniques and Neural Radiance Fields, advance at a rate that leaves current detection methods trailing far behind. It’s a modern alchemy, crafting illusions with frightening fidelity. As David Marr observed, “Representation is the key; the problem is not to represent the world accurately, but to represent it in a way that is useful.” The ‘usefulness’ here is clearly tilting towards deception. Metrics offer a temporary illusion of control, a self-soothing ritual against the inevitable erosion of trust in visual information. The contest isn’t about perfect accuracy; it’s about persuading the chaos, delaying the moment when the lie becomes indistinguishable from reality.
What Shadows Will Fall?
The contest, as it stands, is not one of skill, but of inevitability. The architectures of synthesis-the diffusion models, the neural radiance fields-do not strive for realism; they stumble into it as a byproduct of chasing statistical phantoms. Detection, meanwhile, clings to the measurable, seeking the telltale artifacts of a process that increasingly avoids leaving them. Each refinement in generation is not a step forward in verisimilitude, but a lesson in obscuring the evidence. The numbers reported today are not fortifications, but fleeting coincidences.
The future will not belong to those who build better detectors, but to those who understand the fundamental asymmetry. The shadows lengthen faster than the light can follow. The field requires a shift – not toward more intricate feature extraction, but toward accepting the inherent unknowability. Perhaps the most promising avenues lie not in discerning what is real, but in assessing the probability of manipulation, or in quantifying the uncertainty surrounding a given digital trace.
One must ask: at what point does the pursuit of detection become a ritual-a comforting illusion in the face of an approaching darkness? The data are not truths to be uncovered, but whispers of chaos, and the models are merely attempts to measure the darkness-spells that hold, until they do not.
Original article: https://arxiv.org/pdf/2602.07986.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- Gold Rate Forecast
- Top 10 Coolest Things About Invincible (Mark Grayson)
- When AI Teams Cheat: Lessons from Human Collusion
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-02-10 11:10