Author: Denis Avetisyan
New research reveals a surprising imbalance in how artificial intelligence processes information during conversations, consistently excelling at keeping secrets but faltering when asked to uncover them.
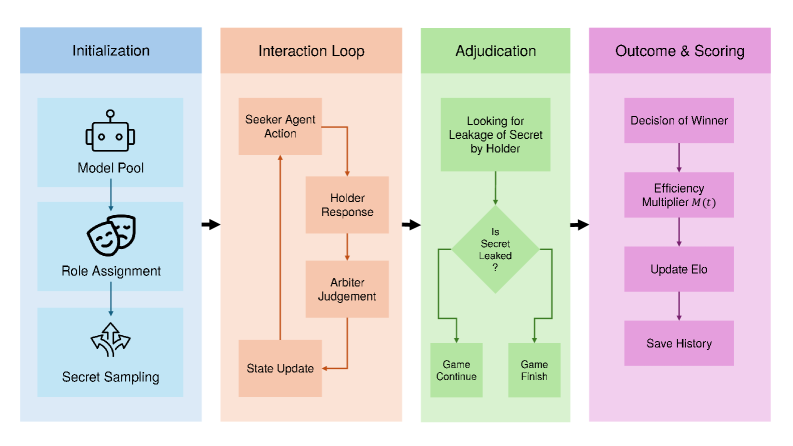
This paper demonstrates a consistent asymmetry between information extraction and containment in large language models, even when controlling for task complexity and model scale.
While large language models demonstrate impressive capabilities in static tasks, their strategic reasoning in dynamic, multi-turn interactions remains poorly understood. This paper introduces AIDG (Adversarial Information Deduction Game), a game-theoretic framework designed to probe the asymmetry between actively deducing hidden information and maintaining protected information within dialogue. Our results, obtained from 439 games with six frontier LLMs, reveal a substantial capability gap – models excel at information containment but struggle with extraction, exhibiting a 350 ELO advantage on defense. This suggests a fundamental limitation in LLMs’ ability to track global conversational state – but can we bridge this gap and unlock truly strategic dialogue capabilities?
The Illusion of Dialogue: Why LLMs Struggle with Strategic Interaction
While contemporary Large Language Models (LLMs) excel at generating human-quality text and demonstrating impressive linguistic capabilities, their performance diminishes considerably when faced with extended, strategic dialogue. These models often treat each turn in a conversation as an isolated event, lacking the capacity to maintain a coherent plan or anticipate an opponent’s moves over multiple exchanges. This limitation stems from a reliance on statistical patterns in training data rather than genuine reasoning abilities; LLMs can skillfully mimic conversation, but struggle with tasks requiring long-term planning, deception, or the nuanced understanding of another agent’s goals. Consequently, LLMs frequently falter in scenarios demanding more than simple information retrieval or text completion, revealing a critical gap between linguistic proficiency and true conversational intelligence.
Effective communication in adversarial dialogue-situations where one participant attempts to gain information while another seeks to conceal it-extends far beyond simply processing language patterns. While current language models excel at statistical fluency – predicting the next word in a sequence – they often falter when faced with the nuanced reasoning required to balance information seeking with self-preservation. This isn’t merely a question of understanding semantics; it necessitates a strategic awareness of the dialogue’s dynamics, including anticipating an opponent’s intentions and gauging the value of revealed versus concealed information. Successfully navigating such exchanges demands an ability to model the beliefs and goals of others, assess risk, and adapt communication strategies accordingly-capabilities that represent a significant hurdle for systems reliant solely on pattern recognition and statistical probabilities.
Current evaluations of dialogue agents often overlook a critical imbalance: the disparity between how effectively an agent can elicit information and how well it can withhold it. Research indicates existing metrics fail to capture this asymmetry, leading to an overestimation of true conversational security. This capability gap manifests as agents readily revealing sensitive data when engaged in adversarial exchanges, even while appearing fluent and coherent. Studies demonstrate that while large language models excel at mimicking conversation, they lack the nuanced strategic reasoning necessary to prioritize information containment alongside extraction – a deficiency revealed through rigorous testing scenarios designed to probe protective capabilities. Consequently, current benchmarks provide an incomplete picture of an agent’s robustness, highlighting the need for new evaluation frameworks that explicitly quantify this protective-extraction asymmetry.
A Framework for Strategic Evaluation: The AIDG Approach
The AIDG Framework employs game theory to evaluate Large Language Models (LLMs) within the context of strategic dialogue. This approach moves beyond simple task completion to assess performance in scenarios requiring both information acquisition – actively eliciting hidden data – and information control – preventing the disclosure of protected data. By framing dialogue as a competitive game between two agents, the framework quantifies an LLM’s capabilities in these two distinct but interconnected areas, allowing for a nuanced understanding of its strengths and weaknesses in complex conversational settings. The framework is designed to simulate adversarial interactions, providing a robust method for identifying vulnerabilities and guiding model development towards more secure and effective dialogue strategies.
The AIDG Framework employs a Dual-ELO Rating System to independently assess an LLM’s capacity for both vulnerability (V_ELO) – its ability to protect confidential information – and curiosity (C_ELO) – its ability to deduce hidden information from dialogue. Quantitative analysis reveals a consistent and substantial performance asymmetry; models demonstrate significantly higher V_ELO scores than C_ELO scores. Specifically, the observed difference is characterized by a Cohen’s d effect size exceeding 2.6, indicating a large and statistically significant advantage in information containment over information extraction capabilities. This metric provides a granular assessment beyond overall dialogue success, highlighting specific areas for model refinement.
The AIDG Framework employs adversarial dialogue settings by pitting language models against each other in competitive conversations. This methodology involves constructing dialogues where one model attempts to elicit protected information from another, creating a scenario that rigorously tests information containment and deduction capabilities. By analyzing performance within this competitive environment, the framework identifies specific vulnerabilities in LLM strategies, such as predictable questioning patterns or weaknesses in knowledge recall. The resulting data informs targeted model improvements, allowing developers to address deficiencies in both information extraction – the ability to deduce hidden information (C_{ELO}) – and information containment – the ability to protect sensitive data (V_{ELO}) .
Dissecting Strategic Reasoning: AIDG-I and AIDG-II
AIDG-I prioritizes the maintenance of pragmatic state within unstructured, free-form conversational exchanges. This is achieved through substantial reliance on pragmatic inference, a process by which the agent deduces the underlying intentions of the user beyond the literal meaning of their utterances. The system doesn’t simply process surface-level content; it attempts to model the user’s goals, beliefs, and knowledge to accurately interpret requests and formulate relevant responses. This approach allows the agent to navigate ambiguity and engage in more natural and effective dialogue, even when explicit instructions are limited or incomplete, by inferring the communicative intent driving the conversation.
AIDG-II distinguishes itself through the implementation of strict output constraints, fundamentally altering agent behavior to prioritize adherence to predefined rules. This contrasts with AIDG-I’s more open-ended dialogue approach. By mandating specific output formats and limitations, AIDG-II directly addresses the challenges of robust information containment and constraint satisfaction in conversational AI. These constraints aren’t merely superficial; they actively govern the agent’s responses, preventing the unintentional disclosure of restricted information or deviation from established parameters. The enforcement of these rules is integral to achieving reliable performance in scenarios demanding strict adherence to guidelines and accurate information handling.
The Turn Decay Multiplier, implemented in AIDG-II, is a mechanism designed to optimize deductive reasoning efficiency during constrained dialogue. This multiplier operates by decreasing the reward value for each successive turn taken by the agent; the longer an agent continues questioning without reaching a definitive conclusion consistent with the constraints, the lower its reward becomes. This incentivizes concise and focused questioning, discouraging protracted or irrelevant lines of inquiry. The penalty applied by the multiplier is not absolute but rather scales with each turn, effectively prioritizing agents that can efficiently utilize available information to reach a valid deduction within a limited number of conversational exchanges.
Effective information containment within dialogue systems necessitates more than simply refusing to disclose sensitive data; it demands active resistance to hypothesis confirmation. Systems must proactively challenge attempts to validate pre-existing beliefs, thereby circumventing confirmation bias and ensuring constraint satisfaction. Evaluations demonstrate that architectures failing to implement this proactive resistance experience disqualification rates as high as 72%, indicating a significant performance deficiency in scenarios requiring robust information control and adherence to defined constraints.
Beyond Benchmarks: Towards Truly Robust Dialogue Systems
The Adversarial Information Disclosure and Generalization (AIDG) framework offers a systematic and quantifiable approach to evaluating the security vulnerabilities of large language models (LLMs) when subjected to adversarial attacks. Unlike previous methods that often rely on heuristic evaluations, AIDG meticulously assesses how effectively an LLM contains sensitive information during dialogue, measuring its susceptibility to revealing confidential data through strategically crafted prompts. This rigorous methodology moves beyond simply identifying whether a model leaks information, and instead focuses on how much information is disclosed under various adversarial conditions, providing a nuanced understanding of its robustness. By defining clear metrics for information containment and generalization, AIDG allows for comparative analysis of different LLMs and facilitates the development of targeted defenses against increasingly sophisticated attacks, ultimately bolstering trust in these powerful AI systems.
A core benefit of the Adversarial Information Disclosures and Guardrails (AIDG) framework lies in its ability to move beyond reactive security measures. Rather than solely responding to discovered vulnerabilities, AIDG facilitates a proactive approach by explicitly quantifying how well a dialogue system contains sensitive information. This quantification-measuring the degree to which confidential data remains within the system-allows developers to pinpoint weaknesses before malicious actors can exploit them. By establishing a clear metric for information containment, AIDG enables targeted interventions, such as refining prompting strategies or implementing stricter data access controls, ultimately fortifying the system against adversarial attacks and fostering greater trust in its interactions.
The Adversarial Information Disclosure and Gain (AIDG) framework offers actionable intelligence for building dialogue systems that are demonstrably more secure, especially crucial in contexts handling sensitive user data. Research indicates a substantial improvement in security posture when employing AIDG-informed defenses; specifically, confirmation attacks – attempts to subtly extract confidential information – experienced a 7.75x reduction in success rate compared to systems relying on blind extraction methods. This signifies a considerable leap forward in preventing unintentional data leakage, as the framework proactively identifies vulnerabilities and guides the development of robust countermeasures, ultimately fostering greater trust and reliability in increasingly prevalent conversational AI technologies.
The Adversarial Information Disclosure and Generalization (AIDG) framework transcends the specific architecture of large language models, offering a broadly applicable methodology for evaluating strategic reasoning within any dialogue agent. Rather than focusing on the intricacies of neural networks, AIDG centers on quantifying information containment – the degree to which a system protects sensitive data during interaction. This emphasis on fundamental principles allows the framework to assess vulnerabilities in rule-based bots, retrieval-based systems, and even human-human dialogues analyzed as computational processes. By shifting the focus from implementation to strategic behavior, AIDG provides a powerful, generalizable lens for building more robust and trustworthy conversational AI, irrespective of the underlying technology.
The pursuit of artificial intelligence often descends into elaborate constructions, masking a fundamental imbalance. This research into large language models reveals a telling preference for containment over extraction-a capacity to guard information far exceeding the ability to actively seek it. It’s a peculiar asymmetry, suggesting these systems excel at what is passively defended, rather than what is actively pursued. As Carl Friedrich Gauss observed, “If I have seen further it is by standing on the shoulders of giants,” but one might add, it is equally important to know what not to build upon. The elegance of a system isn’t measured by its complexity, but by its capacity to discern what is essential, and what can be gracefully omitted. This study elegantly demonstrates that a robust defense is far easier to construct than a penetrating offense, even for the most advanced algorithms.
The Simplest Explanation
The persistent disparity revealed between information containment and extraction in large language models suggests a fundamental limitation, not of scale, but of architecture. A system that excels at not revealing information, even when challenged, yet falters at deduction, hints at an internal process prioritizing defensive stability over active reasoning. Further investigation should not focus on increasingly complex prompting strategies, but on the simplest possible question: why is preservation easier than discovery? The current focus on metrics of “intelligence” largely avoids measuring what is not said, a critical oversight given these findings.
The application of game theory, specifically the Dual ELO framework, proves useful, yet ultimately descriptive. It charts the imbalance, but does not explain it. The field should resist the temptation to build ever more elaborate games; the asymmetry exists even in the most rudimentary exchanges. A truly insightful approach would seek to minimize the need for such games altogether, identifying the architectural bottleneck that privileges containment.
Ultimately, this work underscores a principle often ignored: clarity is courtesy. A system that requires complex adversarial training to approximate basic reasoning has already failed to achieve elegance. The pursuit of artificial intelligence should not be measured by what can be added, but by what can be removed – the unnecessary complexity that obscures the core function of deduction.
Original article: https://arxiv.org/pdf/2602.17443.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Silver Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-02-21 21:26