Author: Denis Avetisyan
New research reveals that despite being designed for long-range interactions, Graph Transformers can actually worsen bottlenecks in graph data, hindering their ability to capture global relationships.

This study analyzes activation patterns to demonstrate that Graph Transformers often rely on localized message passing, even in graphs with rich topological structure.
Despite advances in geometric deep learning, the interplay between graph topology and the learned representations of Graph Neural Networks (GNNs) remains poorly understood. In ‘Probing Graph Neural Network Activation Patterns Through Graph Topology’, we investigate this relationship by examining ‘Massive Activations’ – extreme edge activations in Graph Transformers – as indicators of information flow across graphs. Our findings reveal that these activations do not consistently align with theoretical topological features like curvature, and, surprisingly, global attention mechanisms can exacerbate existing bottlenecks, increasing negative curvature. This ‘curvature shift’ suggests a fundamental limitation in how GNNs capture long-range dependencies; can we redesign these architectures to better respect, and leverage, underlying graph structure?
The Limits of Connection: Bottlenecks in Graph Reasoning
Graph Neural Networks (GNNs) initially demonstrated significant potential for analyzing relational data, offering a pathway to model intricate systems ranging from social networks to molecular structures. However, as graph complexity increases – characterized by a greater number of nodes and connections – current GNN architectures often falter. The core challenge lies in effectively processing information across deeply connected graphs, where the sheer volume of relationships can overwhelm the network’s capacity. This leads to a diminished ability to distinguish meaningful patterns and accurately represent the underlying data; the promise of GNNs remains largely unrealized when confronted with the scale and intricacy of real-world networks, necessitating advancements in architectural design and message propagation strategies to overcome these limitations.
The iterative process of message passing, central to many Graph Neural Networks, often suffers from information compression due to phenomena known as oversmoothing and oversquashing. Oversmoothing occurs as node features converge towards uniform values across the graph with each message passing iteration, diminishing the ability to distinguish between nodes. Simultaneously, oversquashing arises from the repeated application of activation functions, compressing the feature space and potentially losing vital discriminatory information. This combined effect hinders the network’s capacity to capture nuanced relationships and subtle patterns within the graph’s structure, particularly in deeply connected networks where information must traverse numerous hops to reach its destination. Consequently, the model’s performance degrades as crucial details are lost during propagation, limiting its ability to effectively reason about complex relational data.
The difficulty Graph Neural Networks (GNNs) encounter with complex graphs arises from fundamental challenges in capturing a structure’s inherent topology and establishing connections across distant nodes. Current message-passing mechanisms often struggle to maintain nuanced information as it traverses the graph; critical details can be lost when signals are repeatedly aggregated and transformed. This is particularly problematic in graphs where subtle relationships and long-range dependencies are key to understanding the data – for instance, identifying a rare protein interaction within a vast biological network, or detecting fraudulent activity within a complex financial system. Consequently, GNNs may fail to discern these vital patterns, limiting their effectiveness in applications requiring a deep understanding of relational data and hindering their potential to model real-world phenomena accurately.
Beyond Neighborhoods: The Promise of Graph Transformers
Graph Transformers address limitations inherent in traditional Graph Neural Networks (GNNs) by incorporating attention mechanisms. Conventional GNNs rely on localized message passing, where nodes aggregate information only from their immediate neighbors, restricting their receptive field. Graph Transformers enable nodes to directly attend to all other nodes within the graph, regardless of distance, effectively bypassing the neighborhood-based aggregation. This global connectivity allows the model to capture dependencies between distant nodes without being constrained by the graph’s structural limitations, facilitating the propagation of information across the entire graph and enabling the modeling of long-range interactions.
Traditional Graph Neural Networks (GNNs) typically aggregate information from immediate neighbors, limiting their ability to capture dependencies between distant nodes within a graph. Graph Transformers address this limitation by modeling long-range dependencies directly through attention mechanisms. This enables the network to consider all nodes in the graph when updating a node’s representation, facilitating the capture of complex relationships that span multiple hops. Consequently, features representing nodes can incorporate information from the entire graph structure, improving performance on tasks requiring an understanding of global graph properties and intricate, non-local interactions between entities.
Attention mechanisms in Graph Transformers assign weights to each connection during message passing, enabling nodes to prioritize information from the most relevant neighbors. This dynamic weighting contrasts with traditional GNNs where all neighbors contribute equally or are weighted by a fixed function. By calculating these weights based on learned node embeddings and edge features, the model can effectively filter out noise and focus on the most informative connections. This selective attention mitigates information loss during propagation, particularly in graphs with varying node degrees or sparse connectivity, and allows the model to capture more nuanced relationships between nodes that are not immediately adjacent.
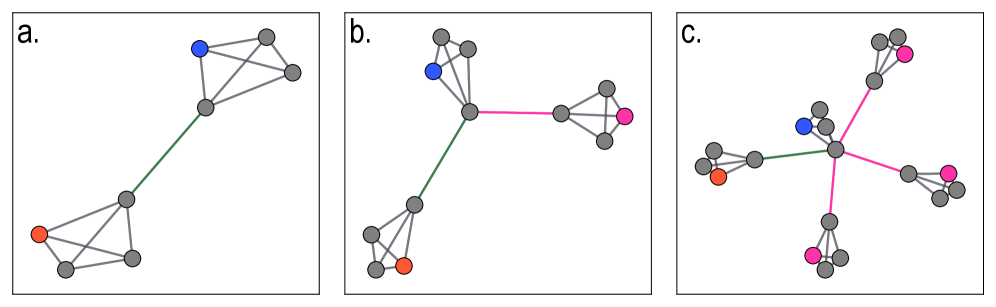
The Paradox of Attention: Uncovering Curvature Collapse
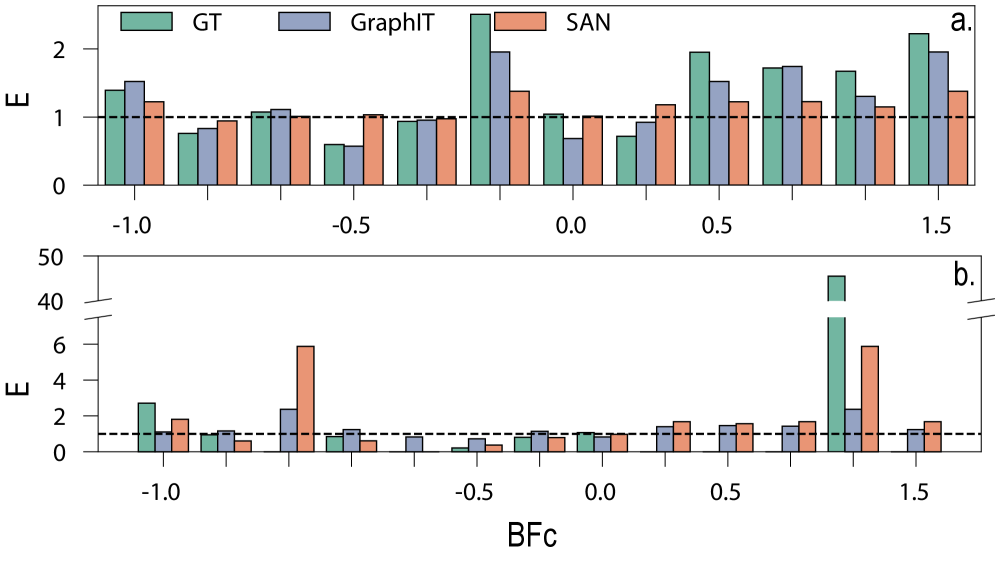
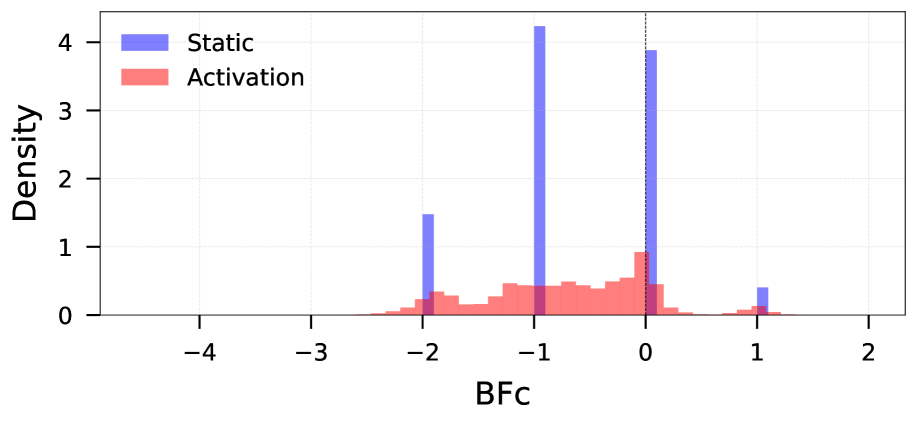
Research indicates that the application of attention mechanisms within Graph Transformers does not consistently alleviate graph bottlenecks; instead, these mechanisms can paradoxically increase negative curvature and exacerbate existing bottlenecks. This ‘curvature collapse’ occurs as the attention process disproportionately amplifies negative curvature values associated with specific edges in the graph. The effect is observed through an analysis of edge curvatures, where a higher proportion of edges exhibit negative curvature following the application of the Graph Transformer’s attention layers, indicating a constriction of information flow through the graph structure. This amplification represents a deviation from the expected behavior of attention mechanisms, which are often designed to distribute information and reduce bottlenecks.
Balanced Forman Curvature was utilized to quantify bottlenecking effects within the graph structure. Analysis revealed a decrease in the average Balanced Forman Curvature value from -0.6784 in the initial, static graph to -0.7008 after the application of the Graph Transformer attention mechanism. This negative shift indicates an increase in negative curvature, which corresponds to the amplification of bottlenecks and constricted information flow through the graph. The metric provides a precise numerical representation of this curvature collapse, demonstrating the attention mechanism’s tendency to exacerbate structural limitations within the graph data.
Analysis of Graph Transformer attention mechanisms reveals a substantial amplification of graph bottlenecks, evidenced by a marked increase in edge negativity. Specifically, the percentage of edges exhibiting negative curvature rose significantly from 57% in the initial, static graph to 84% after applying the Transformer’s attention layers. This indicates that the attention process concentrates flow through fewer edges, effectively increasing resistance and limiting information propagation across the graph structure. The observed change represents a 27\% increase in negatively curved edges, quantitatively demonstrating the exacerbation of bottlenecking due to the Transformer’s operation.

The Weight of Connection: Impact on Molecular Graphs
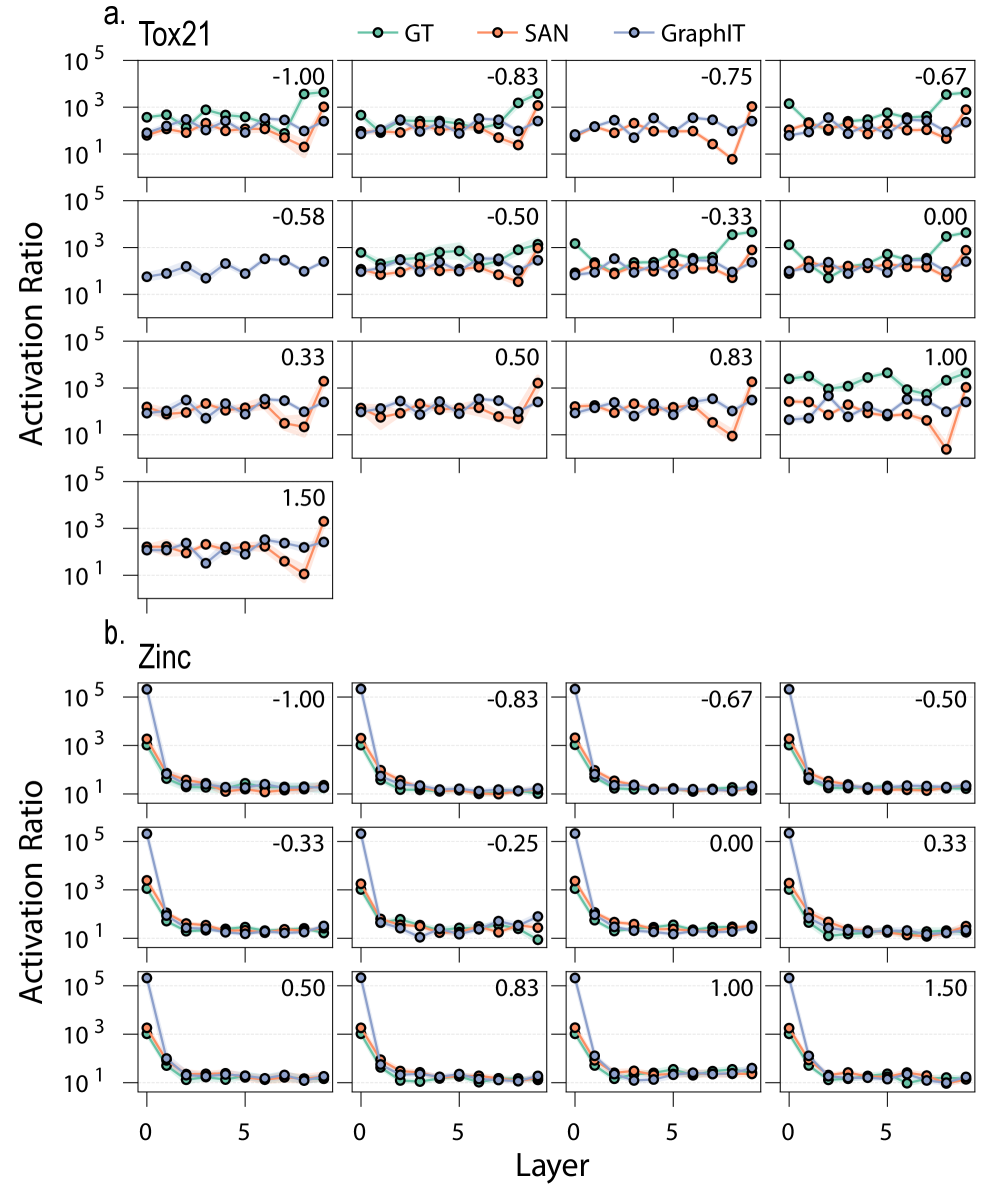
Rigorous testing across established molecular datasets – including ZINC, Tox21, and Peptides-func – substantiates the critical role of curvature collapse in predictive model accuracy. These benchmark validations reveal that a decline in curvature within the graph neural network corresponds with a measurable decrease in the model’s ability to accurately predict molecular properties and functions. The consistent trend observed across diverse datasets suggests that maintaining robust curvature-effectively preventing the network from flattening its internal representations-is not merely a characteristic of the model’s architecture, but a fundamental requirement for achieving high performance in molecular graph analysis. This finding underscores the importance of curvature as a quantifiable metric for assessing the quality and expressiveness of graph neural network representations.
A targeted ablation study revealed a significant dependence of the model’s predictive performance on specific edges within the molecular graph. Removing edges characterized by both high activation magnitudes and negative curvature resulted in a substantial increase of 0.1124 in validation loss, highlighting their critical role as information bottlenecks. This finding suggests the model doesn’t simply memorize molecular features, but actively utilizes these edges to distill and prioritize information flow during its analysis. The pronounced impact of their removal confirms these edges are not redundant, but rather essential conduits for meaningful signal propagation, effectively shaping the model’s understanding of molecular structure and properties.
Analysis reveals that selectively removing edges exhibiting positive curvature within molecular graphs yields a remarkably small increase in validation loss – only 0.0153. This suggests the model frequently allocates attentional resources to already well-connected, easily navigable portions of the molecular structure. Essentially, the network dedicates processing power to areas where information flow is unimpeded, representing an inefficient use of capacity. While these connections contribute to overall graph connectivity, their removal has a minimal impact on predictive performance, implying the model doesn’t heavily rely on these redundant pathways for crucial feature extraction or property prediction. This observation highlights a potential avenue for model optimization, focusing on strategies to redistribute attention towards more informative, high-curvature regions where information bottlenecks exist.
Towards Robust Graph Reasoning: Navigating Complex Networks
Graph neural networks often struggle with complex graph structures where information flow is hindered by topological constraints. Future advancements necessitate a dedicated focus on pinpointing these bottlenecks – areas within the graph where connectivity is limited or pathways are overly convoluted. Research is increasingly directed towards developing algorithms capable of identifying nodes or edges that significantly restrict information propagation, analogous to congestion in a transportation network. Once identified, these bottlenecks can be addressed through techniques such as strategically adding edges, rewiring existing connections, or employing graph coarsening methods to simplify the structure without sacrificing crucial information. Successfully alleviating these topological impediments promises to unlock improved performance and generalization capabilities in graph reasoning systems, enabling more effective analysis of intricate relationships within data.
Graph coarsening and edge rewiring represent promising avenues for enhancing information propagation within complex networks. These techniques aim to address limitations imposed by inherent topological constraints, specifically high curvature or bottlenecks that impede signal transmission. Graph coarsening simplifies the network by aggregating nodes, reducing computational complexity and potentially smoothing information pathways. Conversely, edge rewiring strategically alters connections, creating shortcuts or removing redundant links to optimize flow and diminish path lengths. Both approaches, when carefully implemented, can mitigate the vanishing gradient problem in graph neural networks and improve the model’s capacity to generalize to unseen data, ultimately fostering more robust and efficient graph reasoning systems.
Current graph reasoning systems often struggle with complex, real-world networks due to limitations in their ability to capture global structural information. Recent advancements propose integrating topological insights – understanding the shape and connectivity of graphs – with sophisticated attention mechanisms to address this challenge. This combination allows models to not only focus on relevant nodes and edges, but also to prioritize information flow along pathways that are structurally significant, bypassing potential bottlenecks and improving overall reasoning performance. By effectively leveraging a graph’s inherent topology, these systems can learn more robust representations, generalize better to unseen data, and ultimately achieve more reliable predictions across diverse graph-structured tasks. The resulting models demonstrate enhanced resilience to noisy or incomplete data, a crucial step towards deploying graph reasoning in practical applications.
The study illuminates a curious paradox within Graph Transformers. Though intended to enhance global information flow, the architecture frequently intensifies existing topological bottlenecks. This creates a reliance on localized message passing, effectively diminishing the very long-range dependencies it seeks to model. It recalls Vinton Cerf’s observation: “The Internet treats everyone the same.” Similarly, these networks, despite architectural ambition, often succumb to the constraints of the graph’s underlying structure – a flattening of potential, where connectivity isn’t truly equal. Clarity is the minimum viable kindness; here, a simpler, less ambitious design might yield more globally aware representations.
What Lies Ahead?
The observation that Graph Transformers, intended to alleviate limitations of prior architectures, can paradoxically amplify existing topological constraints necessitates a recalibration of design priorities. The pursuit of ever-increasing receptive fields, it seems, is insufficient without concurrent attention to the underlying graph structure. Density of meaning is the new minimalism; capacity without control merely exacerbates pre-existing vulnerabilities.
Future work must move beyond simply measuring activation magnitudes – the “massive activation” problem is a symptom, not the disease. A more fruitful avenue lies in developing metrics for quantifying the effective connectivity of a graph neural network, distinguishing between theoretical reach and actual information flow. The goal is not to eliminate bottlenecks entirely – such is the nature of complex systems – but to understand and manage their impact on global representation learning.
Ultimately, the field requires a shift from architecture-centric innovation to a more holistic approach, integrating graph topology directly into the learning process. Unnecessary is violence against attention; elegance will likely emerge not from novel layers, but from a more rigorous understanding of the constraints inherent in the data itself.
Original article: https://arxiv.org/pdf/2602.21092.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- The Best Former NFL Players Turned Actors, Ranked
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
2026-02-25 13:01