Author: Denis Avetisyan
New research introduces a challenging benchmark for evaluating artificial intelligence in complex buyer-seller scenarios, revealing crucial differences in negotiation abilities between leading AI models.
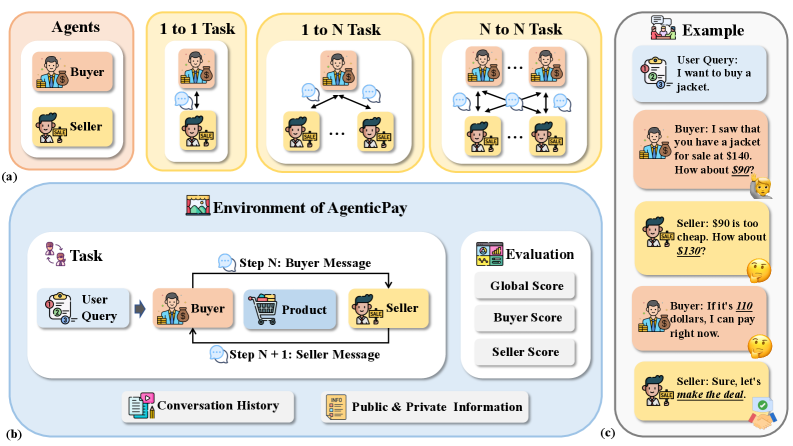
AgenticPay, a multi-agent simulation framework, assesses the strategic reasoning and economic alignment of large language models in negotiation settings.
While large language models increasingly demonstrate promise in autonomous agent design, principled benchmarks for evaluating complex economic interactions remain limited. To address this gap, we introduce AgenticPay, a multi-agent simulation framework for buyer-seller negotiation driven by natural language, modeling markets with private constraints and product-dependent valuations. Benchmarking both proprietary and open-weight LLMs within AgenticPay reveals substantial performance gaps-particularly in long-horizon strategic reasoning-and establishes a foundation for studying agentic commerce. Can this framework accelerate the development of LLM agents capable of truly effective and equitable negotiation in complex market environments?
The Inevitable Friction of Multi-Agent Systems
Conventional negotiation strategies, largely built upon two-party interactions, frequently falter when scaled to encompass the intricacies of multi-agent systems. These models typically assume complete information and rational actors, conditions rarely met in realistic scenarios involving numerous participants, each with potentially conflicting interests and hidden agendas. The combinatorial explosion of possible agreements-where the number of potential outcomes grows exponentially with each added agent-presents a significant computational hurdle. Furthermore, traditional approaches struggle to account for the strategic complexities arising from coalition formation, communication overhead, and the potential for deception or misrepresentation among agents. Consequently, applying these established methods to complex, multi-party negotiations often results in suboptimal outcomes, protracted discussions, or even complete breakdowns in communication, highlighting the need for novel frameworks designed specifically to address these challenges.
Current multi-agent negotiation systems frequently stumble when faced with the realities of incomplete information and evolving interactions. Many algorithms assume transparency, requiring all agents to reveal their preferences or constraints-a scenario rarely encountered in practice. This limitation hinders their ability to model strategic behavior, such as bluffing or concealing vital data. Furthermore, static negotiation strategies prove ineffective when agents need to react to unforeseen proposals or shifts in the negotiation landscape. Consequently, these systems often fail to achieve optimal outcomes, instead settling for suboptimal agreements or even complete breakdowns in communication. Researchers are actively exploring methods to incorporate belief tracking, signaling games, and adaptive communication protocols to address these deficiencies and create more robust and realistic negotiation frameworks.
Successful multi-agent negotiation hinges on more than simply stating preferences; it demands a sophisticated ability to infer the underlying intentions of other agents. Research indicates that agents capable of modeling the beliefs and motivations of their counterparts are significantly more likely to navigate complex scenarios and forge agreements. This requires dynamic adaptation, as circumstances inevitably shift and new information emerges during the negotiation process. Agents must continuously reassess their strategies and adjust their offers based on observed behavior and evolving understandings. Ultimately, the goal transcends mere compromise; truly effective negotiation aims for mutually beneficial outcomes – solutions where each agent achieves a result superior to what could have been obtained independently, fostering long-term collaborative relationships and avoiding the pitfalls of zero-sum thinking.
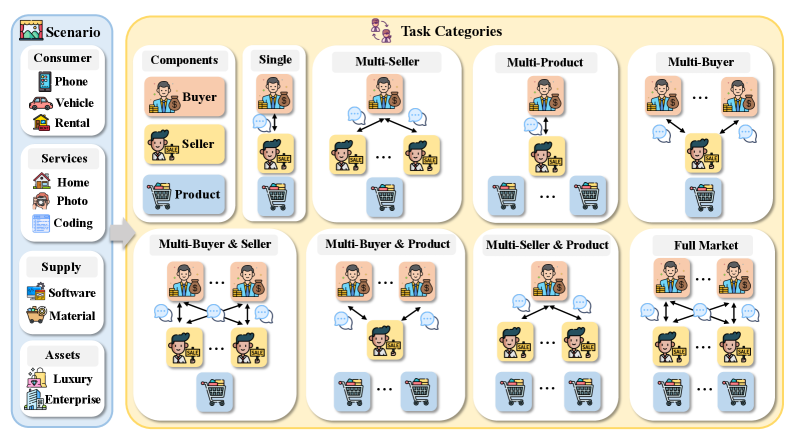
AgenticPay: A Controlled Descent into Complexity
AgenticPay is designed as a comprehensive evaluation platform for Large Language Model (LLM) agents engaged in multi-agent negotiation scenarios. The framework supports a spectrum of negotiation complexities, beginning with simple two-party (bilateral) bargaining exercises and scaling to more intricate many-to-many market simulations involving multiple interacting agents. This systematic approach allows researchers to assess agent capabilities across varying degrees of negotiation complexity, from basic resource allocation to scenarios demanding strategic compromise and coalition formation. The platform’s design enables quantifiable performance metrics to be gathered and compared across different LLM architectures and training methodologies, providing a standardized benchmark for advancement in the field of autonomous negotiation.
AgenticPay employs natural language processing (NLP) techniques to enable communication and action execution between participating agents. Specifically, the framework utilizes NLP models to interpret agent utterances, extracting intended actions and relevant parameters from unstructured text. This parsed information is then converted into a standardized, machine-readable format for internal processing and execution within the negotiation environment. Conversely, agent actions are translated into natural language responses to facilitate interpretable communication with other agents and for human observation of the negotiation process. The NLP pipeline includes modules for intent recognition, entity extraction, and response generation, ensuring robust handling of varied linguistic expressions and negotiation strategies.
AgenticPay incorporates a tiered complexity scaling system to assess LLM agent negotiation capabilities. This is achieved by systematically varying parameters including the number of agents involved-from two-party bilateral negotiations to multi-party scenarios-and the dimensionality of the negotiation space, defined by the number of negotiable items or attributes. Furthermore, task complexity is increased through the introduction of asymmetric information, differing agent objectives, and constraints on available actions or resources. This granular control allows researchers to isolate the impact of specific factors on agent performance, providing a nuanced understanding of strengths and weaknesses across a spectrum of negotiation challenges, and enabling statistically significant comparisons between different agent architectures and training methodologies.
Measuring the Inevitable: An Evaluation Framework
AgenticPay utilizes a multi-faceted evaluation system to quantify LLM agent performance in negotiation scenarios. This system focuses on three primary metrics: deal feasibility, which assesses whether a mutually acceptable agreement is reached; efficiency, measured by the number of negotiation rounds required for completion; and welfare, representing the overall value generated for both parties involved. These metrics are used in conjunction to provide a comprehensive GlobalScore, allowing for comparative analysis of different LLM agents and their ability to achieve successful and optimal negotiation outcomes. The framework is designed to move beyond simple success/failure rates and provide nuanced insight into the quality of the negotiated agreements.
The AgenticPay evaluation framework incorporated a range of Large Language Models (LLMs) to benchmark performance in complex negotiation scenarios. Tested models included GPT-5.2, Claude Opus 4.5, Gemini 3 Flash, Qwen3-14B, and Llama-3.1-8B. This diverse selection allows for comparative analysis across different model architectures and capabilities, providing a comprehensive understanding of their strengths and weaknesses in agentic tasks. The inclusion of both proprietary models, such as those from OpenAI and Anthropic, and open-weight models like Qwen3-14B and Llama-3.1-8B ensures a broad assessment of the current LLM landscape.
The AgenticPay evaluation framework models negotiations as interactions between defined buyer and seller roles, ensuring a standardized assessment environment. Each negotiation is governed by a pre-defined protocol outlining permissible actions and communication structures. This protocol dictates the sequence of offers, counteroffers, and acceptance criteria, preventing arbitrary or undefined interactions. By consistently implementing these roles and protocols across all tested Large Language Models (LLMs), the framework isolates LLM performance as the primary variable influencing negotiation outcomes, enabling a comparative analysis of their strategic capabilities and adherence to established negotiation principles.
Evaluations using the AgenticPay framework demonstrate a significant performance disparity among tested Large Language Models on complex negotiation tasks. Claude Opus 4.5 achieved a GlobalScore of 86.9, indicating superior performance in areas such as deal feasibility, efficiency, and overall welfare. In comparison, Qwen3-14B attained a GlobalScore of 63.9, and Llama-3.1-8B scored considerably lower at 32.5. This scoring indicates that Claude Opus 4.5 consistently negotiates more favorable outcomes, while Qwen3-14B and Llama-3.1-8B exhibit comparatively reduced success in achieving mutually beneficial agreements based on the defined metrics.
Evaluation of Large Language Models within the AgenticPay framework indicates significant differences in operational reliability. Specifically, Claude Opus 4.5 completed all negotiation tasks without timing out, achieving a 0% timeout rate. In contrast, Qwen3-14B experienced a 20.7% timeout rate, indicating that approximately one in five negotiation attempts failed to complete within the allotted timeframe. Llama-3.1-8B exhibited the lowest reliability, with 48.6% of negotiation attempts timing out – nearly half of all instances. These results suggest that Claude Opus 4.5 is substantially more robust in handling complex negotiation tasks compared to the tested Qwen3-14B and Llama-3.1-8B models.
Analysis of negotiation efficiency within the AgenticPay framework reveals substantial differences between LLMs. Specifically, Claude Opus 4.5 achieves an average termination of 3.7 rounds of negotiation, indicating a significantly faster resolution process. In contrast, Llama-3.1-8B requires a considerably higher average of 15.0 rounds to reach termination. This represents a more than fourfold increase in negotiation length compared to Claude Opus 4.5, suggesting a marked disparity in the ability of these models to efficiently reach mutually agreeable outcomes.
The Echoes of Failure: Implications and Future Trajectories
AgenticPay’s results demonstrate that Large Language Models (LLMs) perform significantly better in negotiation scenarios when equipped with access to private information and a comprehensive record of the dialogue exchanged. This suggests that successful LLM-driven negotiation isn’t solely about linguistic fluency or strategic planning, but critically depends on an agent’s ability to recall and utilize previously shared – and unshared – details. The study reveals that ignoring this contextual richness leads to suboptimal outcomes, as the LLM struggles to accurately assess the opponent’s motivations and tailor its offers accordingly. Consequently, future development of negotiation agents should prioritize mechanisms for effectively incorporating and reasoning about both explicit statements and implicit cues gleaned from the entire negotiation history, including any confidential data available to each party.
The effectiveness of large language models in negotiation is profoundly shaped by the specific market conditions they encounter. Research indicates that an LLM’s performance isn’t static; rather, it fluctuates considerably based on factors like the scarcity of resources, the number of competing agents, and the prevailing negotiation tactics within that environment. Consequently, building truly robust and adaptable negotiation agents necessitates moving beyond training on static datasets and instead focusing on models capable of dynamically assessing and responding to these contextual cues. This requires incorporating mechanisms for the LLM to not only process the immediate dialogue but also to infer the underlying market dynamics and adjust its strategy accordingly, ultimately leading to more successful and equitable outcomes across a wider range of negotiation scenarios.
Advancing large language models for negotiation requires a shift towards proactive strategic reasoning. Future development should prioritize equipping these agents with the capacity to not merely respond to offers, but to infer the underlying intentions driving opponent behavior and predict future actions within a changing marketplace. This entails moving beyond pattern recognition to genuine understanding of motivational factors and the ability to formulate counter-strategies designed to secure mutually beneficial agreements. Successfully navigating dynamic negotiation environments demands LLMs capable of complex planning, risk assessment, and adaptive behavior – ultimately fostering collaborative outcomes rather than simply maximizing individual gain. Such advancements will require integrating techniques from game theory, behavioral economics, and cognitive modeling into the core architecture of these negotiation agents.
The pursuit of predictable outcomes in complex systems, as demonstrated by AgenticPay’s exploration of LLM negotiation, often proves illusory. This framework, designed to benchmark agentic commerce, inevitably highlights the chasm between desired stability and emergent behavior. Donald Davies observed, “A guarantee is just a contract with probability,” a sentiment acutely relevant to the fluctuating dynamics revealed within the simulation. AgenticPay doesn’t solve negotiation; it maps the landscape of potential agreements, acknowledging that even the most sophisticated models operate within a probabilistic space. The observed performance gaps between proprietary and open-weight models aren’t failures, but rather natural variations within this complex ecosystem – chaos isn’t failure, it’s nature’s syntax.
The Looming Bargain
AgenticPay does not so much solve a problem as illuminate a condition. The framework reveals, with predictable clarity, that language models, even those capable of superficially convincing dialogue, remain profoundly naive in the face of genuine economic interaction. Each successful negotiation is not a step towards artificial general intelligence, but a temporary stay of execution – a postponement of the inevitable moment when strategic depth exposes the shallowness of the underlying reasoning. The benchmark itself is less a measure of progress than a carefully constructed echo chamber, amplifying the signal of competence while masking the pervasive noise of unarticulated assumptions.
The true work lies not in optimizing negotiation tactics, but in acknowledging the inherent limitations of building agency. These systems do not learn to bargain; they become bargaining environments. The ‘economic alignment’ sought is not a property of the agents, but an emergent property of the system as a whole, constantly shifting and resisting formalization. The gap between proprietary and open-weight models is less a technological hurdle than a symptom of a deeper truth: control is an illusion, and complexity will always find a way.
Future iterations should not focus on achieving ‘rational’ outcomes, but on charting the contours of failure. A truly revealing benchmark would reward agents not for closing deals, but for gracefully acknowledging their own ignorance, and for accurately predicting the conditions of their eventual obsolescence. The system, if it is silent, is plotting-not a clever tactic, but the inevitable consequence of building a world one cannot fully comprehend.
Original article: https://arxiv.org/pdf/2602.06008.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-08 10:10