Author: Denis Avetisyan
A new wave of research explores how machine learning can design, analyze, and reconstruct mechanisms for making collective decisions in increasingly complex environments.
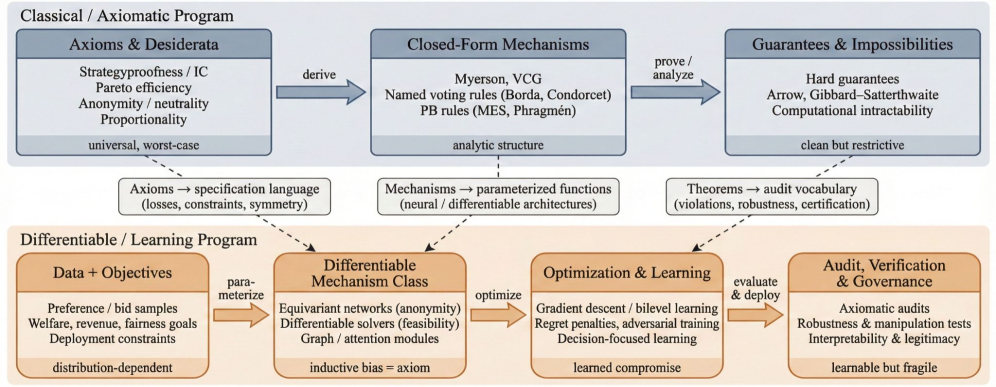
This review surveys the emerging field of differentiable social choice, covering methods for learning mechanisms, addressing strategic manipulation, and aligning algorithms with human preferences.
Collective decision-making, traditionally studied in social choice theory, now faces new challenges as machine learning systems increasingly aggregate diverse preferences and incentives. This Review, ‘Methods and Open Problems in Differentiable Social Choice: Learning Mechanisms, Decisions, and Alignment’, surveys the emerging paradigm of differentiable social choice, which formulates voting rules and mechanisms as learnable models optimized from data. By synthesizing work across auctions, voting, and decentralized aggregation, we demonstrate how classical axioms reappear as optimization trade-offs in these learned systems. Given the growing role of these mechanisms-from resource allocation to aligning large language models-how can we design and audit them to ensure fairness, stability, and strategic robustness?
From Idealization to Reality: The Limits of Traditional Incentive Design
Traditional mechanism design, a cornerstone of economic and game-theoretic modeling, frequently operates under the stringent premise of complete rationality and perfect information amongst participating agents. This necessitates assumptions that individuals consistently maximize their utility and possess comprehensive knowledge of the system’s rules and the preferences of others. However, real-world systems rarely conform to these ideals; cognitive biases, incomplete information, and bounded computational abilities are pervasive. Consequently, mechanisms meticulously crafted under these idealized conditions often falter when deployed in complex environments, yielding suboptimal outcomes or even complete failure. The reliance on these strong assumptions limits the practical applicability of classical approaches, particularly in dynamic systems where agents may adapt or exhibit behaviors not anticipated by the initial model. This disconnect between theoretical elegance and empirical performance underscores the need for more robust and adaptable mechanism design frameworks.
Traditional mechanism design, while theoretically sound, often falters when confronted with the complexities of real-world application due to inherent limitations in scalability and adaptability. These approaches, built upon a foundation of predefined rules and static assumptions, struggle to efficiently handle a large number of agents or evolving environmental conditions. As the number of participants increases, the computational burden of determining optimal incentives grows exponentially, rendering many algorithms impractical. Furthermore, these axiomatic designs typically lack the capacity to respond effectively to shifts in agent preferences, unexpected events, or newly available information. Consequently, their rigid structure proves insufficient for dynamic systems where flexibility and responsiveness are crucial, necessitating a move toward more agile, data-driven methodologies that can learn and adjust to changing circumstances.
The limitations of traditional mechanism design necessitate a paradigm shift toward flexible, data-driven strategies. Rather than relying on meticulously crafted, predefined rules based on assumptions of perfect rationality, contemporary research emphasizes the power of learned incentives. These approaches leverage machine learning algorithms to analyze agent behavior and dynamically adjust incentive structures, allowing systems to adapt to complex and evolving environments. This transition involves treating incentive design not as a static problem of axiomatic derivation, but as an ongoing learning process, where algorithms iteratively refine strategies based on observed data. Such methodologies promise to overcome the scalability issues inherent in classical approaches and unlock the potential for effective mechanism design in real-world scenarios characterized by bounded rationality and incomplete information. Ultimately, the focus moves from dictating behavior through fixed rules to shaping it through continuously optimized incentives.
Reframing Incentive Engineering: The Rise of Differentiable Mechanisms
Differentiable Social Choice (DSC) and associated methods allow for the optimization of mechanism design by directly applying gradient descent. Traditionally, mechanism design involved analytical or computationally expensive methods to verify incentive compatibility and revenue properties. DSC reframes this process by expressing the desired social welfare or objective function as a differentiable loss function, effectively treating the aggregation rule – how individual reports are combined to determine the outcome – as a component within a larger neural network. This allows the mechanism itself – specifically the rules governing how reports are translated into allocations – to be learned via backpropagation. The key is representing the outcome as a continuous function of reported preferences, enabling gradient-based optimization of mechanism parameters to minimize the loss and achieve desired properties like Pareto efficiency or revenue maximization. \nabla_{\theta} L(\theta) can then be used to iteratively refine the mechanism θ.
Traditionally, mechanism design relied on analytical solutions derived from game theory, often requiring strong assumptions about agent rationality and information structures. Framing mechanism design as an optimization problem allows the application of gradient-based methods and other machine learning algorithms, such as stochastic gradient descent and Adam, to directly optimize mechanism properties like revenue, efficiency, or fairness. This enables the use of large datasets of agent behavior to learn optimal mechanisms without explicitly modeling agent types or beliefs. Furthermore, it facilitates the incorporation of complex constraints and inductive biases into the optimization process, leading to more robust and adaptable mechanisms than those obtained through purely analytical approaches. The objective function can be defined to reflect desired mechanism properties, and the parameters of the mechanism can be adjusted iteratively to minimize the loss, effectively ‘training’ the mechanism for optimal performance.
The differentiable mechanism design paradigm allows for the integration of inductive biases directly into the mechanism’s functional form, enabling designers to express prior beliefs about desirable properties such as revenue maximization or fairness. Simultaneously, this approach permits learning directly from complex behavioral data, bypassing the need for strong assumptions about agent rationality or data generating processes. By treating the mechanism as a differentiable function, gradient-based optimization can utilize observed agent behavior – even when exhibiting deviations from standard economic models – to refine mechanism parameters and improve performance according to a specified objective. This capability is particularly valuable in settings where agents’ preferences are unknown, heterogeneous, or subject to cognitive biases, as the mechanism can adapt to these patterns through data-driven learning.
Unveiling Agent Intent: Methods for Robust and Adaptive Incentive Systems
Inverse Mechanism Learning (IML) is a technique used to estimate the payoff functions of agents based on observed behavioral data. This is achieved by iteratively refining a proposed mechanism, comparing predicted behavior with actual observations, and adjusting the estimated payoffs to minimize discrepancies. Recent advances in Differentiable Inverse Mechanism Learning (DIML) have established conditions under which payoff differences are identifiable – meaning they can be uniquely recovered from the data – specifically when agents respond according to conditional logit models. Identifiability results rely on assumptions about the data-generating process and typically require sufficient variation in observed choices to distinguish between different payoff structures. Statistical consistency of DIML estimators has been verified under certain regularity conditions, ensuring that the estimated payoffs converge to the true values as the amount of data increases.
Differentiable Economics and Neural Social Choice leverage techniques from machine learning to model and optimize economic interactions that are often analytically intractable. These approaches allow for the representation of complex preference structures and strategic behavior using differentiable functions, enabling the application of gradient-based optimization methods. This is particularly useful in scenarios involving multiple agents with heterogeneous preferences, where traditional economic methods may struggle to find optimal solutions. Neural Social Choice, a subset of this field, utilizes neural networks to approximate social welfare functions and implement voting rules, offering a flexible framework for designing and analyzing collective decision-making processes. The differentiability of these models allows for sensitivity analysis, counterfactual reasoning, and the direct optimization of mechanism design parameters with respect to desired outcomes, such as efficiency or fairness.
Federated Learning offers a distributed machine learning approach applicable to mechanism design, allowing model training across multiple decentralized datasets without direct data exchange. This preserves data privacy, as only model updates – not raw data – are shared between participating entities. Statistical consistency of mechanisms trained via this method, specifically within the framework of Differentiable Inverse Mechanism Learning (DIML), has been formally verified under specific regularity conditions regarding data distributions and model parameters. These conditions typically involve assumptions about the smoothness of the objective function and the boundedness of data features, ensuring convergence to a consistent estimate of the underlying mechanism.
Beyond Economic Models: Expanding the Impact of Incentive Design
The principles of mechanism design, traditionally applied to economic auctions, are increasingly relevant to the realm of civic participation. Innovative applications extend these methods to participatory budgeting and liquid democracy, aiming to overcome limitations in traditional voting systems. By carefully crafting incentive structures, these approaches can encourage more informed and representative decision-making. For instance, systems can be designed to reward citizens for actively participating in proposal evaluation or for accurately predicting the outcomes of collective choices, mitigating issues like low turnout or the dominance of special interests. This facilitates a more inclusive process where a broader range of voices are heard and considered, ultimately leading to policies that better reflect the preferences of the community and fostering greater trust in democratic institutions.
Natural Language Mechanism Design represents a significant leap in incentive engineering, extending its principles beyond traditional economic models and into the realm of everyday communication. Previously, designing incentives relied heavily on quantifiable metrics and actions; this approach now allows for the creation of incentive structures within complex, unstructured language. By analyzing the semantic content of interactions – negotiations, requests, or even simple dialogues – systems can dynamically adjust rewards or penalties to guide behavior. This has implications for fields ranging from automated negotiation and dispute resolution to personalized education and collaborative content creation, enabling more nuanced and effective alignment of individual goals with desired outcomes. The core innovation lies in translating linguistic nuances into actionable signals, effectively turning conversation into a mechanism for incentivizing specific behaviors and fostering more productive interactions.
Constitutional AI represents a novel approach to the longstanding challenge of AI alignment, seeking to imbue artificial intelligence with human values not through direct programming of ethics, but through a process of self-improvement guided by a pre-defined “constitution.” This framework employs techniques from mechanism design and reinforcement learning to train AI systems to evaluate their own responses based on a set of principles – such as being helpful, harmless, and honest – effectively creating an internal system of checks and balances. Instead of explicitly coding what an AI should do, the system learns to judge whether its actions are consistent with the stated constitutional principles, allowing for adaptation to nuanced situations and reducing the risk of unintended consequences. This iterative process of self-critique and refinement holds promise for creating AI systems that are not only powerful but also demonstrably aligned with human intentions and ethical considerations, moving beyond simply maximizing rewards to prioritizing responsible and beneficial behavior.
Towards Robust and Accountable Incentive Systems: A Vision for the Future
Evaluating the performance of data-driven mechanisms in ideal settings is insufficient; a crucial step involves rigorous robustness analysis. This process deliberately subjects the mechanism to adversarial conditions and potential strategic manipulation by participants, revealing vulnerabilities that might otherwise remain hidden. Such analysis doesn’t simply test for errors, but probes how cleverly motivated actors could exploit the mechanism’s design to achieve outcomes deviating from its intended purpose. By anticipating and quantifying these risks, researchers can develop strategies to fortify the mechanism against manipulation, ensuring its reliable operation even when faced with malicious or self-serving behavior. The ultimate goal is to build mechanisms that are not only efficient but also resilient, maintaining their desired properties under a wide range of realistic and challenging circumstances.
Auditability in learned mechanisms is paramount for establishing confidence and responsibility in their deployment. It moves beyond simply achieving desired outcomes to providing a transparent record of how those outcomes are reached, allowing for thorough inspection of the decision-making process. This capability isn’t merely about detecting errors; it enables verification that the mechanism operates according to its intended design and adheres to relevant ethical or legal constraints. Consequently, auditability fosters trust among stakeholders – users, regulators, and developers alike – by demonstrating a commitment to fairness, accountability, and the potential for meaningful redress when issues arise. Without such transparency, the widespread adoption of these mechanisms, particularly in sensitive applications, remains significantly hindered, as opaque systems invite skepticism and limit opportunities for improvement.
The successful integration of data-driven mechanisms into high-stakes applications – from loan approvals to criminal justice risk assessment – hinges not simply on achieving optimal performance, but on demonstrating consistent reliability and transparency. Current research indicates a pathway toward this goal, with studies revealing that techniques like proportionality proxies – which ensure fairness by linking outcomes to legitimate, measurable factors – and constrained optimization algorithms can significantly mitigate inherent biases. These approaches allow developers to build mechanisms that are not only efficient, but also demonstrably equitable and accountable, fostering greater trust and facilitating wider adoption in critical domains where algorithmic fairness and auditability are paramount. Further investigation promises to refine these techniques and unlock the full potential of data-driven mechanisms to improve decision-making across a range of vital services.
The exploration of differentiable social choice, as detailed in the study, underscores a critical point about system design. It reveals how seemingly localized optimizations – such as learning mechanisms for preference aggregation – inevitably introduce new complexities and potential tension points within the broader system. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This resonates deeply with the challenges presented in reconstructing and auditing mechanisms; a clever solution, while efficient, may obscure its own vulnerabilities, necessitating a holistic understanding of its behavior over time – truly, architecture is the system’s behavior, not a diagram on paper.
What’s Next?
The burgeoning field of differentiable social choice offers a compelling, if somewhat unsettling, proposition: to treat collective decision-making as an optimization problem amenable to gradient descent. This approach, while elegantly sidestepping the traditional constraints of mechanism design, begs the question of what is being optimized for. Is it simply maximizing some aggregate utility function, or is there a deeper principle of fairness, robustness, or procedural justice that must be encoded – and if so, how? The pursuit of algorithmic governance, thus, isn’t merely a technical exercise, but a philosophical one, demanding a rigorous accounting of values.
A critical limitation remains the vulnerability to strategic manipulation. While techniques exist to audit mechanisms post-hoc, a truly robust system must anticipate and neutralize adversarial behavior. This suggests a move beyond static mechanism design towards adaptive systems capable of learning and evolving in response to strategic agents. The connection to inverse reinforcement learning is particularly promising, yet it also highlights a crucial challenge: reconstructing preferences from observed behavior is inherently ambiguous, and any such reconstruction will inevitably reflect the biases of the learning algorithm itself.
Simplicity, it must be remembered, is not minimalism. It is the discipline of distinguishing the essential from the accidental. The field risks becoming mired in increasingly complex models, losing sight of the fundamental goal: to build systems that amplify, rather than automate, human judgment. The future likely lies in hybrid approaches – mechanisms that combine the computational efficiency of machine learning with the deliberative power of human oversight, acknowledging that a well-functioning society is not merely optimized, but thoughtfully constructed.
Original article: https://arxiv.org/pdf/2602.03003.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Silver Rate Forecast
- The Best Former NFL Players Turned Actors, Ranked
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
2026-02-04 11:55