Author: Denis Avetisyan
An autonomous AI agent, AlphaResearch, is pushing the boundaries of algorithm discovery by generating, testing, and refining code with minimal human intervention.
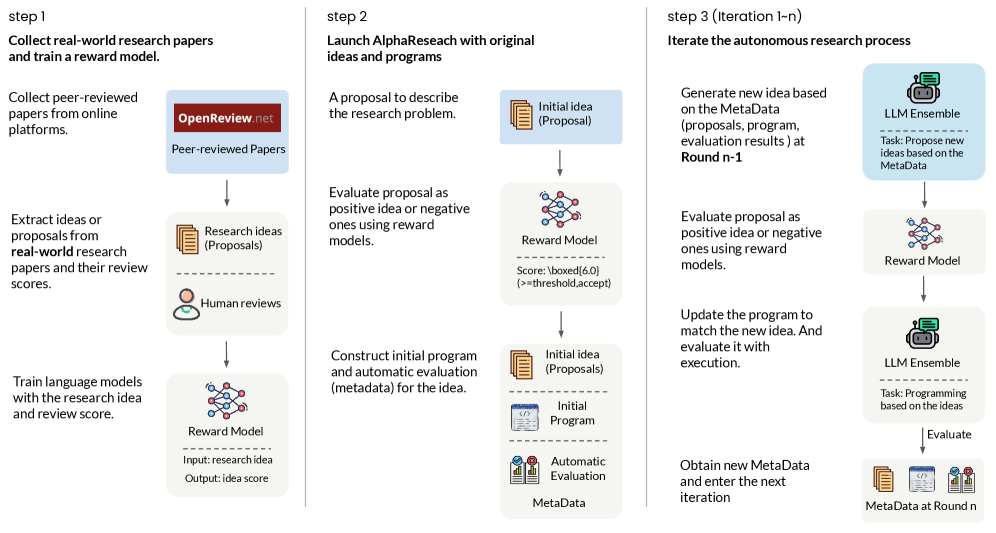
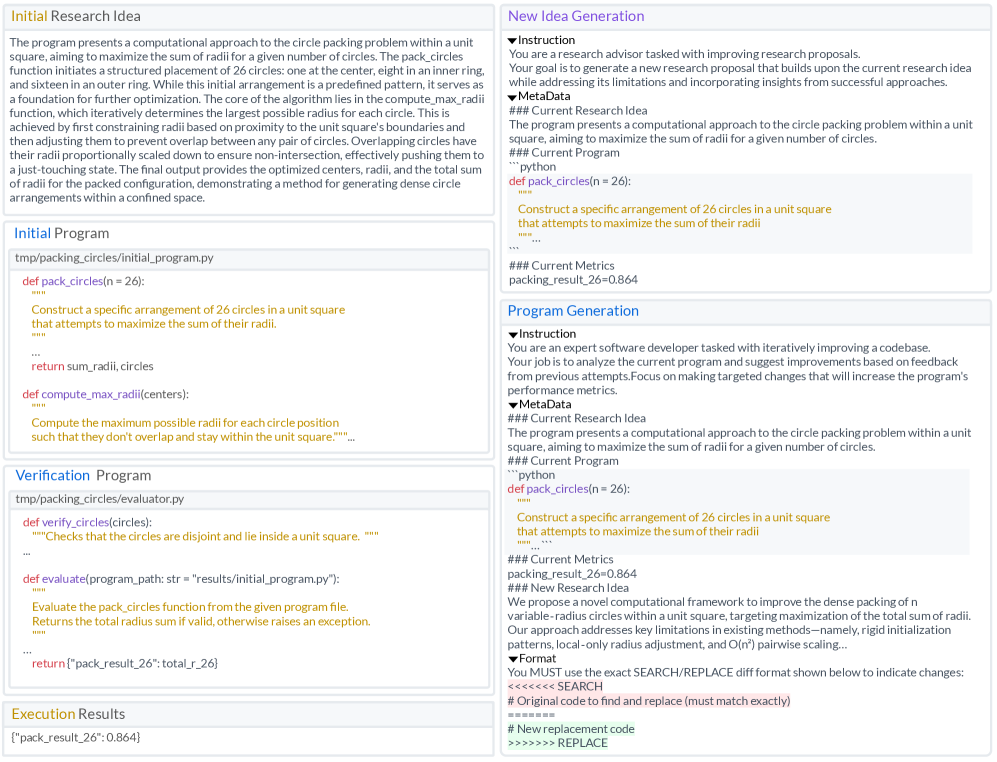
AlphaResearch combines large language models with program execution and simulated peer review to discover algorithms that outperform human-designed solutions on select tasks.
While large language models excel at tasks with readily verifiable solutions, genuine discovery—generating novel approaches to open-ended problems—remains a significant challenge. This is addressed in ‘AlphaResearch: Accelerating New Algorithm Discovery with Language Models’, which introduces an autonomous agent that synergistically combines LLM-driven idea generation with program execution and simulated peer review. Notably, AlphaResearch achieves state-of-the-art performance on the “packing circles” problem, surpassing both human experts and existing algorithms, and demonstrates a competitive win rate across a novel benchmark. Can this approach unlock a new era of automated scientific discovery and accelerate progress across diverse domains?
The Erosion of Intuition
Traditional scientific progress relies heavily on human intuition, a process inherently limited by cognitive biases and scale. Researchers often explore a narrow solution space, constrained by assumptions and practicality. This directed search can impede discovery, particularly in complex problem areas.
The modern research landscape demands methods capable of systematically exploring vast algorithmic spaces. Exhaustive testing is often impossible, necessitating automated techniques that efficiently navigate and evaluate diverse candidates. This shift addresses increasingly complex challenges in fields from materials science to machine learning.
Automated algorithm design offers a potential solution, leveraging computational power to generate and evaluate candidates without human bias. These systems explore broader possibilities, potentially uncovering approaches otherwise missed. Even the most refined intellect, it seems, is merely a local optimum in the larger landscape.
Autonomous Inquiry
AlphaResearch represents a novel approach to automated scientific discovery, functioning as an autonomous agent capable of generating, verifying, and evaluating research proposals without human intervention. It moves beyond task execution, actively formulating and rigorously testing hypotheses. The core architecture prioritizes a closed-loop process linking proposal generation to validation.
A key component is its utilization of Large Language Model (LLM) Idea Generation to explore research avenues. These LLMs construct formalized, computationally testable hypotheses. Following hypothesis formation, the system employs Program-Based Verification to assess validity and feasibility. This methodology ensures generated ideas are both novel and amenable to programmatic evaluation.
To provide objective assessment, AlphaResearch integrates a Peer Review Simulation module, mimicking human expert evaluation. The simulation analyzes methodology, originality, and potential impact, generating a comprehensive report. This allows iterative refinement and prioritization of promising research directions.
Simulating the Critical Eye
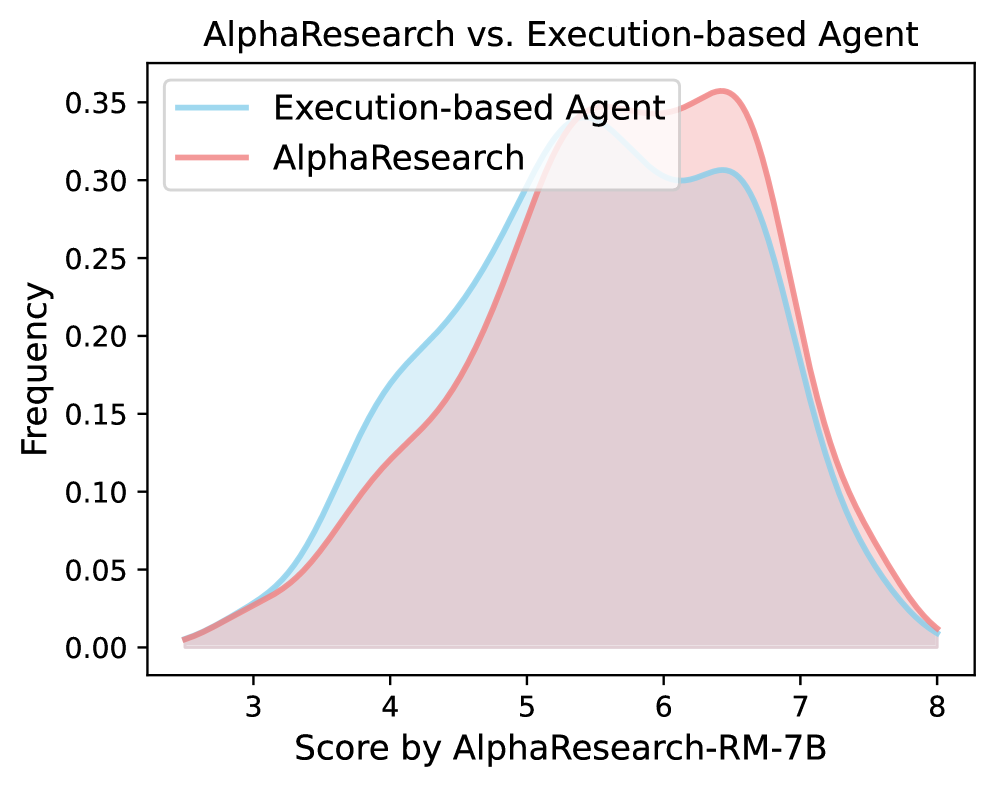
The Peer Review Simulation leverages the AlphaResearch-RM-7B Reward Model, trained extensively on authentic peer-review data to ensure fidelity in its assessments. This model serves as the core evaluator, providing a consistent basis for judging research quality.
Program-Based Reward, derived from successful code execution, complements the subjective evaluations of the Reward Model. This dual assessment – simulated peer review paired with automated validation – minimizes bias and maximizes reliability. The system doesn’t merely score proposals; it tests their viability through executable code.

This combined methodology allows nuanced evaluation, considering both qualitative assessments and demonstrable functionality, resulting in a more robust and trustworthy system for identifying promising research directions.
Beyond Human Capacity
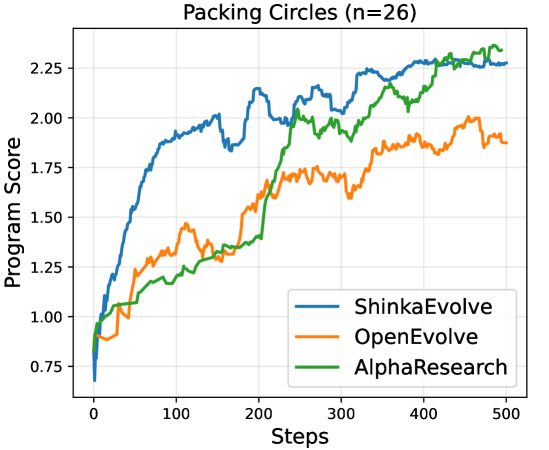
AlphaResearch has recently demonstrated significant advancement in automated algorithm discovery, achieving state-of-the-art results on established mathematical problems. Specifically, the research team developed a novel algorithm for circle packing, outperforming previously known solutions.
This success extends to the Third Autocorrelation Inequality. These achievements were facilitated by an execution-based reward system, allowing the algorithm to self-improve through iterative testing and refinement, as visually demonstrated in the accompanying illustration.
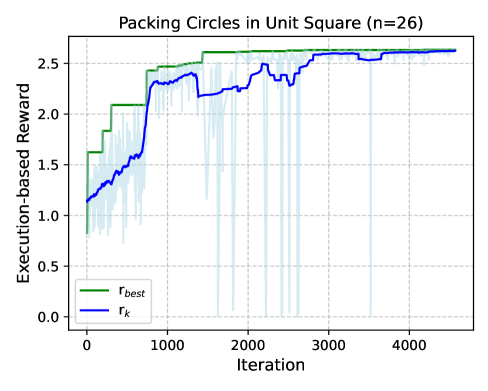
The agent’s performance suggests a paradigm shift in algorithm development – one where automated systems can not only match but exceed human expertise. Every iteration is a testament to the principle that delaying fixes is a tax on ambition.
The Accelerating Tide
This work demonstrates the potential for fully automated scientific discovery, accelerating innovation across disciplines. AlphaResearch utilizes a novel task decomposition and execution framework, enabling independent hypothesis formulation, experimental design, and result analysis without human intervention. Initial trials in materials science, specifically predicting stable crystal structures, achieved a success rate comparable to experienced researchers.
Future research will focus on scaling AlphaResearch to tackle more complex problems and integrating it with existing scientific infrastructure. Current efforts include expanding its knowledge base, improving its handling of noisy data, and developing interfaces for seamless collaboration with human scientists. A key challenge lies in ensuring the reproducibility and verifiability of AI-driven discoveries.
Ultimately, the vision is a future where AI agents collaborate with human scientists, pushing the boundaries of knowledge and solving the world’s most pressing challenges. This collaborative paradigm promises to augment human creativity and accelerate the scientific process, enabling faster progress in areas such as drug discovery, climate modeling, and fundamental physics.
The pursuit of novel algorithms, as demonstrated by AlphaResearch, inherently acknowledges the transient nature of computational superiority. Systems, even those born from the latest language models, are not static achievements but rather points along a continuous timeline of refinement. Brian Kernighan observes, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment resonates deeply with AlphaResearch’s approach; the system doesn’t merely generate algorithms, it subjects them to rigorous, simulated peer review—a form of ‘debugging’ on a grand scale—recognizing that initial cleverness must yield to sustained validity. The agent’s ability to surpass human performance isn’t simply a matter of speed, but a testament to the power of iterative improvement within a defined temporal framework.
What Lies Ahead?
The pursuit of autonomous algorithm discovery, as demonstrated by AlphaResearch, isn’t a quest for perpetual motion, but rather a controlled acceleration of inevitable decay. Every algorithm, no matter how elegantly derived, will eventually succumb to the limitations of its assumptions, the changing landscape of computational resources, and the emergence of more efficient paradigms. The system reveals not the end of research, but a shifting of its form – from manual construction to a process of guided erosion, where novelty arises from the systematic dismantling of the existing order.
The current iteration, while achieving performance gains on specific tasks, highlights the brittleness of reward models. These models, acting as imperfect proxies for true understanding, impose a local optimum on the search space, potentially obscuring genuinely innovative solutions that don’t immediately align with pre-defined metrics. Future work must address this by embracing methods for assessing algorithmic robustness – the capacity to maintain functionality not merely within the training distribution, but across unforeseen conditions.
Ultimately, the longevity of such systems hinges not on their ability to generate algorithms, but on their capacity to anticipate and accommodate their own obsolescence. Uptime is, after all, a rare phase of temporal harmony. The true challenge lies in designing agents that can gracefully navigate the transition from creators of novelty to curators of legacy, perpetually refining the tools needed to dismantle their own creations and build anew.
Original article: https://arxiv.org/pdf/2511.08522.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Trading Crypto with AI: A New Approach to Portfolio Management
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
2025-11-12 12:17