Author: Denis Avetisyan
A new study reveals that the rapid gains seen in artificial intelligence are increasingly limited by benchmark saturation, demanding a rethink of how we measure progress.
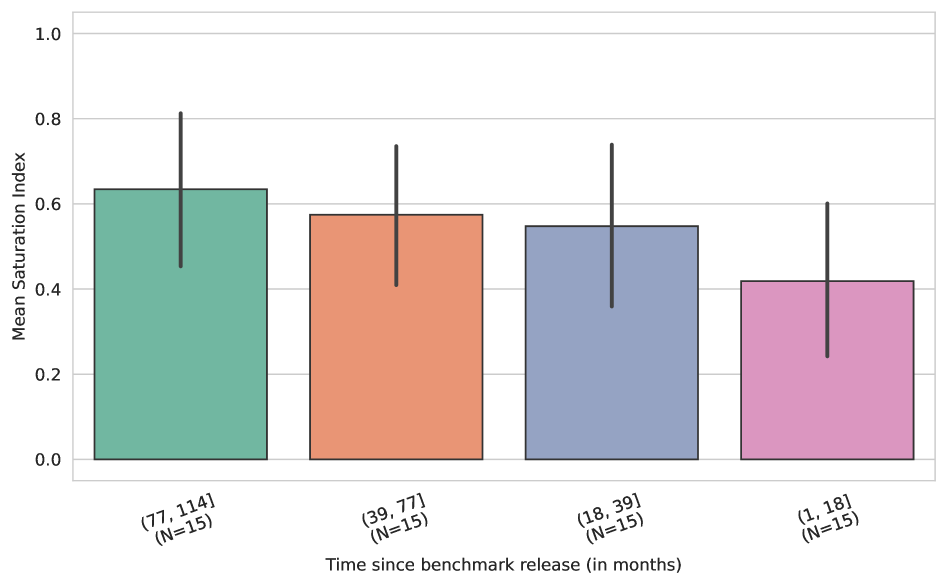
Research demonstrates that benchmark age and test set size are primary drivers of saturation, with common mitigation strategies proving largely ineffective.
Despite their central role in tracking progress, AI benchmarks increasingly exhibit a limited capacity to differentiate between leading models. This study, ‘When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation’, systematically analyzes saturation across 60 Large Language Model benchmarks, revealing that benchmark age and test set size are primary drivers of this phenomenon. Surprisingly, commonly proposed mitigation strategies, such as withholding test data, offer little protection, while expert-curated benchmarks demonstrate greater longevity. How can the AI community design more durable evaluation protocols that accurately reflect genuine model improvements and avoid the pitfalls of rapidly saturating metrics?
The Evolving Landscape of Language Model Evaluation
The accelerating pace of development in Large Language Models presents a significant challenge to accurate and meaningful evaluation. As models grow in complexity and capability, traditional benchmarks struggle to keep pace, often failing to adequately assess emergent properties or genuine understanding. This discrepancy arises because evaluations frequently rely on static datasets and predefined metrics, which can be quickly saturated or exploited by increasingly sophisticated models. Consequently, reported performance gains may not reflect true improvements in reasoning, generalization, or real-world applicability, creating a growing gap between leaderboard scores and actual capabilities. The field now requires innovative evaluation paradigms that move beyond simple pattern matching and instead probe for robust, adaptable intelligence – a task proving increasingly difficult as LLMs continue to evolve.
The proliferation of publicly available datasets used to benchmark Large Language Models (LLMs) inadvertently introduces a significant challenge: data contamination. Reports of impressive performance on popular leaderboards are increasingly undermined by the realization that models may have, directly or indirectly, been trained on portions of the test data itself. This creates a skewed perception of true generalization ability, as models aren’t genuinely ‘understanding’ unseen prompts but rather ‘recalling’ information encountered during training. Consequently, reported scores may vastly overestimate a model’s performance in real-world applications, where exposure to the training data is not guaranteed and the ability to handle truly novel situations is paramount. The issue necessitates a critical re-evaluation of existing benchmarks and a move toward more robust evaluation methodologies that prioritize unseen data and assess genuine reasoning capabilities.
Despite advancements in benchmark datasets, current evaluation metrics for Large Language Models often provide an incomplete picture of true intelligence. While metrics like perplexity and BLEU score offer quantifiable assessments, they struggle to capture subtle capabilities such as commonsense reasoning, ethical considerations, or creative problem-solving. This limitation creates opportunities for “gaming” the system, where models are specifically optimized to perform well on benchmarks without demonstrating genuine understanding. A model might achieve a high score by exploiting statistical patterns in the training data or memorizing answers, rather than exhibiting true linguistic competence. Consequently, reliance on these metrics alone can be misleading, potentially overestimating a model’s capabilities and hindering progress toward genuinely intelligent systems.
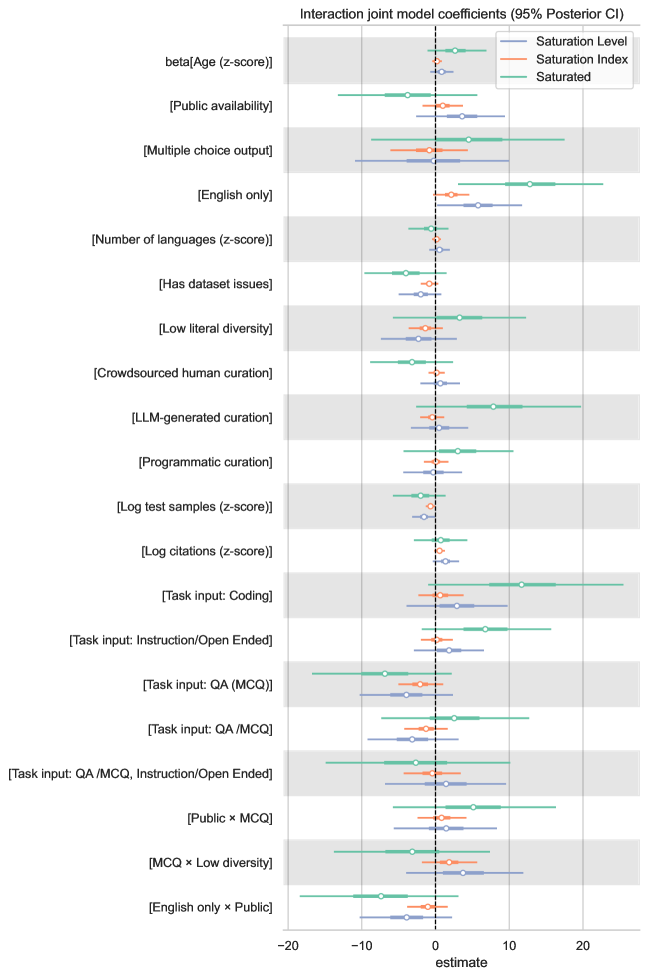
The Erosion of Discriminative Power: Benchmark Saturation
As machine learning models achieve increasingly higher levels of performance, standard evaluation benchmarks are experiencing a decline in their ability to reliably differentiate between these top-performing systems; this phenomenon, termed “saturation,” directly impacts statistical separability. Statistical separability, a measure of a benchmark’s capacity to produce distinct and meaningful differences in scores between models, diminishes as performance converges near the upper limits of the benchmark. This means that even substantial improvements in model capabilities may not translate into statistically significant gains on saturated benchmarks, hindering accurate performance assessment and model comparison. Consequently, the utility of these benchmarks for tracking progress and driving further innovation is compromised.
Analysis of sixty standard benchmarks reveals a significant degree of saturation, with 29 exhibiting a Saturation Index of 0.7 or higher, indicating a diminished capacity to differentiate between model performance. This loss of discriminative power is attributable to multiple factors, including the age of the benchmark itself, the scale of the test dataset used for evaluation, and the extent to which models have been previously exposed to the data or similar data during training. These factors collectively contribute to increasingly compressed performance distributions at the upper end of benchmark leaderboards.
Analysis indicates that benchmark saturation is a widespread phenomenon, impacting both open-ended and closed-ended task types. While initial concerns focused on the limitations of evaluating generative models with fixed, relatively small datasets, our data demonstrates that discriminative power is diminishing across a broad spectrum of evaluations. Specifically, benchmarks requiring free-form generation, such as text summarization or creative writing, exhibit similar saturation levels to those employing multiple-choice question answering or other constrained output formats. This suggests the core issue isn’t inherent to the nature of the task, but rather a systemic challenge related to the evolving capabilities of models and the static nature of many evaluation datasets.
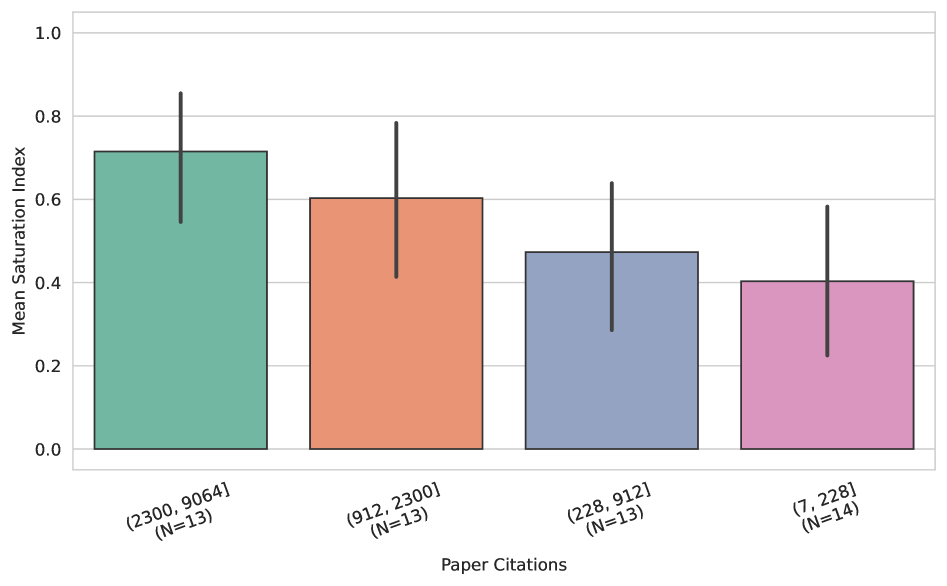
Quantifying Benchmark Health: The Saturation Index
The Saturation Index is a quantitative metric designed to assess the degree to which a benchmark’s leaderboard reflects genuine performance differences rather than optimization for the benchmark itself. This index is calculated using a combination of factors including leaderboard result distributions, the diversity of submitted solutions, and inherent characteristics of the benchmark task-such as data set size and complexity. Continuous monitoring of the Saturation Index allows for the identification of benchmarks where leaderboard positions are increasingly determined by narrow optimization strategies, rather than broad generalization ability, indicating a loss of signal for meaningful model comparison.
The Saturation Index facilitates comparative analysis of benchmark health by providing a normalized metric applicable across diverse evaluation suites. This standardization enables researchers and practitioners to objectively assess and rank benchmarks based on their ability to differentiate between models, allowing for informed prioritization of resources and selection of the most informative benchmarks for specific evaluation needs. A higher Saturation Index indicates a benchmark is likely still yielding meaningful comparative data, while a lower index suggests potential saturation and diminished utility for discerning model performance differences. This capability is crucial for maintaining the integrity and relevance of leaderboards and ensuring that evaluation efforts are focused on benchmarks that continue to provide valuable signals.
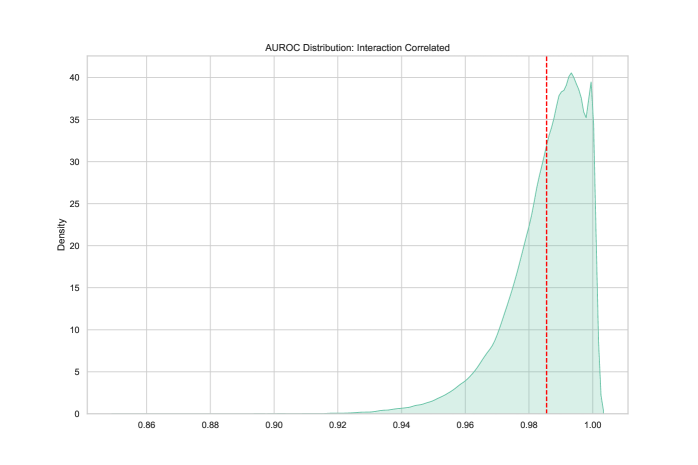
The Saturation Index enables researchers to quantitatively assess the continued utility of benchmarks by identifying those yielding diminishingly informative signals. Evaluation of the model demonstrates a high degree of accuracy in distinguishing saturated benchmarks from those that remain viable, as evidenced by an Area Under the Receiver Operating Characteristic curve (AUROC) of 0.98. This performance indicates the model’s strong capability to reliably flag benchmarks where performance plateaus suggest a lack of continued differentiation between models, allowing for focused resource allocation and benchmark selection.
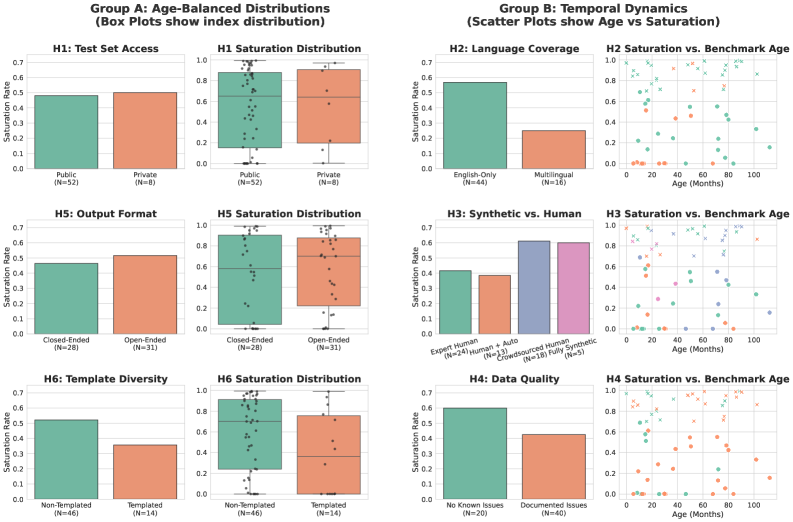
The Enduring Influence of Benchmark Characteristics
The inherent characteristics of a benchmark-specifically whether it’s constructed by humans or generated synthetically-significantly impacts its vulnerability to saturation. Human-authored benchmarks, born from the nuances of natural language and often reflecting complex cognitive tasks, tend to exhibit saturation sooner than their synthetic counterparts. This is because the patterns within human-created data are more readily discovered and exploited by increasingly capable models. Conversely, synthetic benchmarks, while offering control and scalability, often lack the subtle complexities present in natural language, delaying but not necessarily preventing eventual saturation. Consequently, a benchmark’s origin influences its lifespan as a reliable evaluation metric, with human-authored benchmarks requiring more frequent updates or supplementation to maintain their discriminatory power as models improve.
The longevity of a language benchmark is significantly impacted by its linguistic scope; benchmarks focused solely on English demonstrate a faster decline in utility compared to those encompassing multiple languages. This disparity arises because English, as a heavily researched language, experiences rapid progress in model capabilities, leading to quicker saturation of the benchmark’s difficulty. Conversely, multilingual benchmarks, by distributing evaluation across a wider range of linguistic structures and nuances, effectively slow the rate of saturation. This extended lifespan isn’t simply about increased content, but a broadened assessment space that provides a more sustained challenge for advancing language models and a more reliable measure of true cross-lingual understanding. Therefore, considering linguistic diversity is crucial for building benchmarks that remain informative and valuable over time.
Analysis reveals that a benchmark’s age is a significant predictor of its susceptibility to saturation – the point at which model performance plateaus, obscuring further progress. Older benchmarks consistently demonstrate higher saturation indices, indicating that performance gains on these datasets are increasingly limited. This isn’t simply a matter of poor initial design; rather, saturation appears to be driven by the inherent dynamics of repeated exposure and the limitations of how these benchmarks measure capabilities. As models are repeatedly trained and tested on the same data, they effectively “solve” the benchmark, revealing its inherent constraints. This suggests that benchmark saturation is a fundamental challenge, stemming from the way models interact with fixed datasets, and not merely a result of isolated design flaws in any particular benchmark.
The study meticulously details how benchmark saturation impacts the reliable evaluation of large language models, revealing a lifecycle effect where initial gains diminish over time. This phenomenon echoes Robert Tarjan’s observation: “Program structure is important. If you don’t have that, it doesn’t matter what algorithms you use.” Just as a poorly structured program will falter regardless of optimization, so too will AI evaluation become meaningless if the benchmarks themselves aren’t continuously revised and maintained. The research highlights that simply increasing test set size or employing private datasets offers limited long-term benefit; the underlying structure of the evaluation process must adapt to the evolving capabilities of the models themselves, demanding a holistic and proactive approach to lifecycle management.
The Inevitable Fade
The study of benchmark saturation reveals a predictable truth: systems break along invisible boundaries-if one cannot see them, pain is coming. The current reliance on static, fixed evaluations for large language models is demonstrably unsustainable. Age, as this work highlights, is a corrosive force, and the size of the test set offers only temporary respite. Attempts to fortify evaluations with private datasets, while intuitively appealing, prove largely ineffective in delaying the inevitable. This is not a failure of technique, but a fundamental misunderstanding of the system itself.
The field must shift from seeking ever-larger datasets to embracing a lifecycle approach to evaluation. Continuous monitoring, adaptive testing, and a willingness to retire benchmarks before they become meaningless are essential. The focus should not be on creating impenetrable defenses against exploitation, but on anticipating the patterns of decay. Robustness is not a static property; it’s a dynamic relationship between a model and a constantly evolving landscape of challenges.
Ultimately, the quest for a single, definitive evaluation is a fool’s errand. Structure dictates behavior, and the current structure incentivizes a race to optimize for increasingly irrelevant metrics. A more fruitful path lies in acknowledging the inherent limitations of any fixed assessment and building systems capable of self-assessment and continuous improvement – systems that can, in effect, learn to recognize when the ground beneath them is shifting.
Original article: https://arxiv.org/pdf/2602.16763.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading Smarter: AI-Powered Execution Schedules
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
- 15 Films That Were Shot Entirely on Phones
2026-02-21 05:01