Author: Denis Avetisyan
A new analysis challenges the prevailing assumption of continually accelerating AI capabilities, suggesting diminishing returns may be on the horizon.
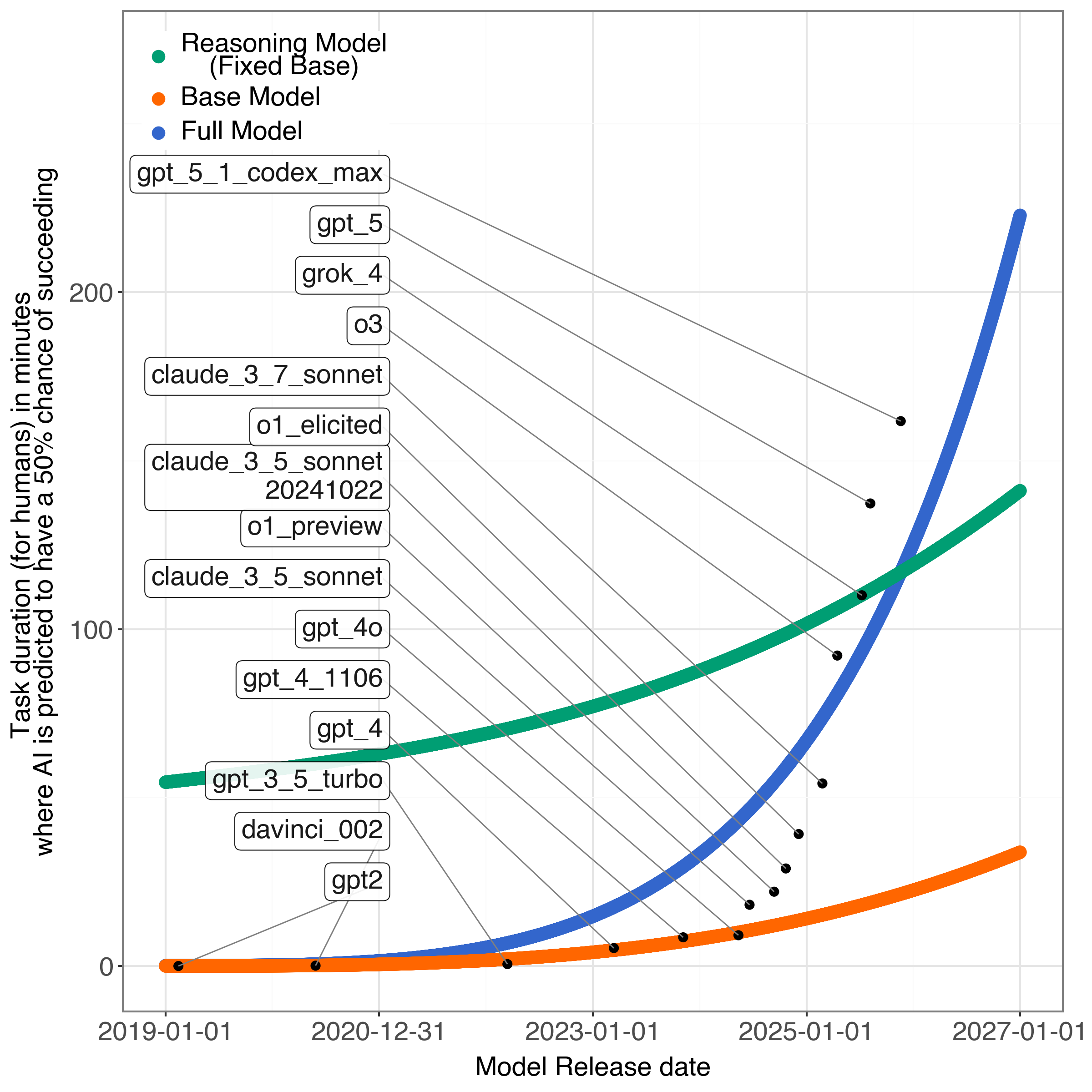
This review proposes a sigmoid-shaped growth curve for AI, highlighting the increasing importance of reasoning ability and model horizon as key factors limiting future scaling.
The widely held assumption of continually accelerating progress in artificial intelligence may be premature, particularly when extrapolating current trends into the future. In the paper ‘Are AI Capabilities Increasing Exponentially? A Competing Hypothesis’, we challenge the claim of exponential growth in AI, arguing that available data suggests an impending plateau. By fitting a sigmoid curve to existing benchmarks, we demonstrate that the inflection point-the moment of peak growth-may have already passed, and propose a model decomposing AI capabilities into base and reasoning components. Will a more nuanced understanding of these limiting factors reshape expectations for the future trajectory of AI development?
The Inevitable Plateau: Charting the Limits of Exponential Growth
The rapid advancement of artificial intelligence over recent years isn’t simply anecdotal; it aligns with predictions made by the METR Study, which initially characterized this progress as exhibiting exponential growth. This means the capabilities of AI systems aren’t increasing linearly, but at an accelerating rate – each period of development yielding a proportionally larger increase in performance than the last. Early successes in areas like image recognition and natural language processing demonstrated this phenomenon, with improvements in accuracy and efficiency occurring at increasingly shorter intervals. The METR Study provided a quantitative framework for understanding this surge, establishing a baseline for measuring future AI development and highlighting the potential for transformative change across numerous sectors. This initial period of exponential growth laid the foundation for the more complex capabilities now being explored, even as researchers investigate the limits of sustained acceleration.
The accelerating progress in artificial intelligence isn’t simply anecdotal; it’s measurable through metrics like the 50% Model Horizon. This figure represents the point at which an AI model can reliably solve a task with 50% accuracy, and its consistent expansion signifies an increasing capacity to tackle more complex problems. Initially focused on relatively simple challenges, the Model Horizon has demonstrably broadened over recent years, indicating that AI is not just getting faster at existing tasks, but is also acquiring the ability to address qualitatively different and more intricate issues. This metric provides a quantitative benchmark for tracking AI’s evolving capabilities, moving beyond subjective assessments to offer a clear picture of its growing problem-solving proficiency and potential applications across diverse fields.
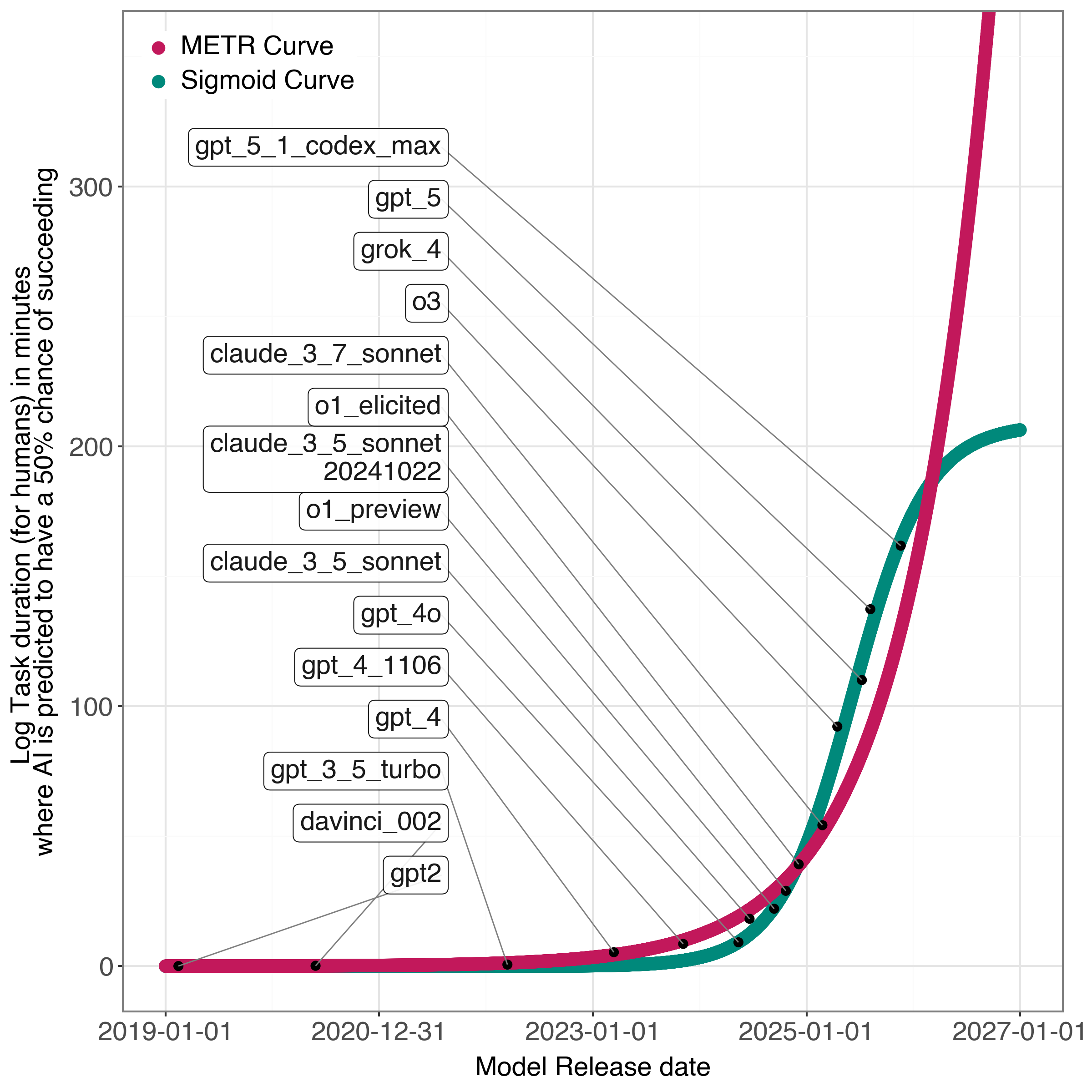
While artificial intelligence has demonstrated remarkable progress, often described as exponential growth, the METR Study indicates inherent limitations to sustaining this trajectory indefinitely. The research reveals that forecasting AI capabilities using an exponential model proves less accurate than employing a sigmoid link function. This suggests a natural ceiling to the rate of improvement; rather than continuing unbounded growth, AI advancement appears to follow a pattern of diminishing returns. Specifically, the study demonstrates a lower Mean Squared Error – a measure of forecasting accuracy – when utilizing the sigmoid function, implying that a logistic, or S-shaped, curve more accurately represents the future progression of AI capabilities than a purely exponential one. This isn’t to suggest an impending halt to progress, but rather a shift towards increasingly complex challenges requiring fundamentally new approaches – and a deceleration of the easily quantifiable gains observed in recent years.
Deconstructing the Black Box: Base Skills and the Illusion of Reasoning
The METR study posits that overall AI capability is not a single, unified trait, but rather a composite of underlying “Base LLM Capabilities.” These base capabilities are fundamentally derived from two primary factors: the quantity of data used during training and the scale of the model, typically measured in parameter count. The study suggests that performance on various tasks isn’t solely indicative of ‘intelligence’ but reflects the extent to which a model has successfully internalized patterns and relationships present within its training data, and its capacity to represent those patterns given its architectural size. This implies that improvements in performance can be attributed, at least in part, to increases in either data volume or model scale, independently of any higher-level cognitive abilities.
Recent advancements in artificial intelligence performance are increasingly linked to the development of ‘Reasoning Capabilities’ within large language models. These capabilities denote the capacity to perform logical inference, moving beyond simple pattern recognition and data recall inherent in models scaled primarily on data volume. Specifically, reasoning involves applying learned knowledge to novel situations, drawing conclusions from premises, and solving problems requiring multi-step thought processes. Evidence suggests that improvements in reasoning – as demonstrated in tasks requiring commonsense reasoning, symbolic manipulation, or mathematical problem-solving – are not solely a byproduct of increasing model size or dataset scale, but represent a distinct emergent property of model architecture and training methodologies.
The significance of decoupling reasoning capability from sheer data and parameter scale lies in its potential to improve AI performance with diminishing returns on model size. Current large language models (LLMs) demonstrate performance gains largely correlated with increased data ingestion and model parameters; however, this scaling is computationally expensive and may reach practical limits. The emergence of distinct reasoning capabilities suggests that targeted improvements to an AI’s inferential processes – independent of data volume or parameter count – can yield substantial performance benefits. This offers a pathway to more efficient AI development, reducing reliance on exponentially growing datasets and computational resources while still achieving gains in complex problem-solving and logical inference.
The Multiplicative Imperative: A System’s Capacity is Not the Sum of Its Parts
The Multiplicative Model of AI advancement posits that total AI capability is determined by the product of two core components: base Language Model (LLM) capabilities and reasoning abilities. This contrasts with an additive model, where capability would be the sum of these components. The multiplicative relationship implies that improvements in either LLM capacity or reasoning skills yield disproportionately larger gains in overall AI capability when combined. Specifically, a system with both moderate LLM and reasoning skills will outperform a system with high skills in only one area; a deficiency in either component significantly diminishes the overall result, as the product approaches zero. This model suggests that focusing development equally on both LLM scale and reasoning architectures is crucial for maximizing AI progress.
Observations indicate a non-additive relationship between language model capabilities and reasoning abilities in AI systems. Specifically, improvements in reasoning skills are not merely incremental additions to base language model performance; instead, they demonstrably amplify the effectiveness of the underlying language model. This amplification is evidenced by the ability of reasoning modules to significantly improve performance on complex tasks, exceeding what would be predicted by simply summing the individual capabilities. Data suggests that reasoning allows language models to better utilize their existing knowledge and generate more accurate and contextually relevant outputs, effectively multiplying their inherent potential rather than simply adding to it.
Statistical fitting of the multiplicative model utilizes techniques including Linear Regression and B-Spline functions to quantify the relationship between base language model capabilities and reasoning abilities. Empirical data is analyzed to determine the parameters that best represent the observed AI performance. As a benchmark for model accuracy, the METR exponential regression achieved a high R-squared value of 0.98, indicating a strong correlation between the model’s predictions and actual performance metrics. This suggests the multiplicative model effectively captures the observed scaling behavior of AI capabilities based on available data.
Validating the System: Diverse Tasks and the Pursuit of General Competence
The METR study employs three distinct task families – HCAST, RE-Bench, and SWAA – to provide a comprehensive assessment of AI system performance across a variety of domains. HCAST focuses on human-computer security task automation, evaluating capabilities in areas like malware analysis and vulnerability detection. RE-Bench centers on realistic software engineering benchmarks, measuring proficiency in code completion, bug fixing, and program synthesis. SWAA, or Software Workflow Automation and Analysis, assesses AI’s ability to automate and analyze common software development workflows. The utilization of these diverse task families ensures that the evaluation extends beyond narrow benchmarks, providing a more representative understanding of AI capabilities in practical, real-world scenarios.
The METR study employs task families – HCAST, RE-Bench, and SWAA – designed to evaluate AI performance across a spectrum of capabilities. HCAST focuses on challenges within the cybersecurity domain, including vulnerability detection and malware analysis. RE-Bench assesses capabilities relevant to reasoning and problem-solving, while SWAA evaluates skills crucial to software engineering, such as code generation and bug fixing. This deliberate diversity ensures the evaluation isn’t limited to a single skillset, providing a more representative assessment of general AI competence and its applicability across varied, real-world scenarios.
Statistical evaluation of the multiplicative model’s performance utilized Log-Likelihood as a primary metric to assess the goodness of fit against observed data from the diverse task families. Analysis revealed that the model achieved the lowest Mean Squared Error (MSE) when employing a sigmoid link function; this indicates that the sigmoid function provided the optimal transformation of the predicted values to minimize the discrepancy between the model’s output and the actual observed values. The resulting MSE values were used to compare the performance of the model with different link functions and validate its predictive capabilities across the evaluated tasks.
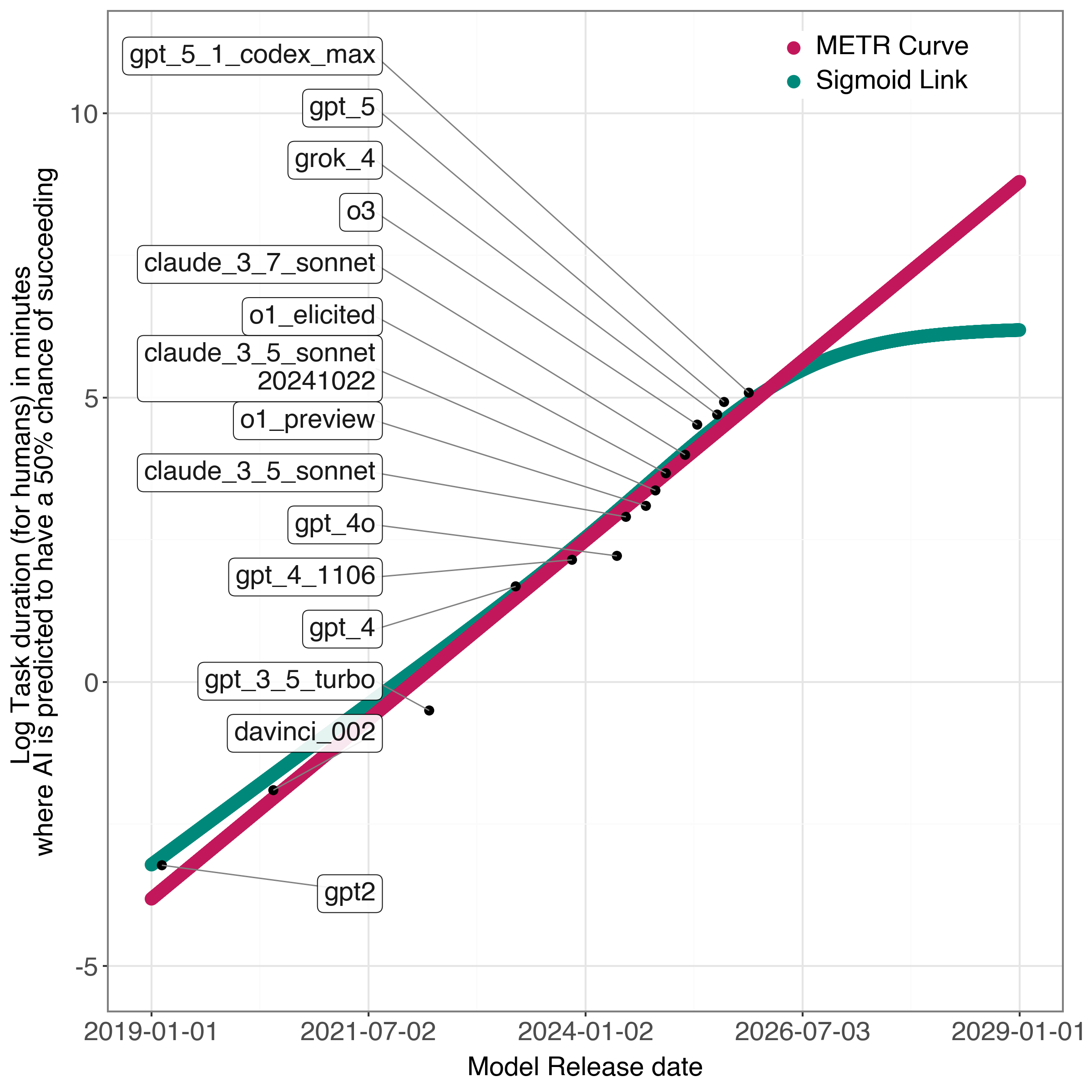
The Approaching Limit: A Shift in Focus for Sustained Advancement
Current trajectories in artificial intelligence development may soon encounter diminishing returns if progress continues to rely predominantly on increasing dataset size and model parameters. The “multiplicative model” proposes that overall AI capability isn’t simply the sum of data and scale, but their product with reasoning ability; therefore, sustained advancement hinges critically on enhancing an AI’s capacity for logical thought, problem-solving, and abstract understanding. This suggests that future breakthroughs won’t necessarily arrive from larger models trained on more data, but from innovations in algorithmic efficiency and the development of architectures specifically designed to amplify reasoning skills – effectively shifting the focus from brute-force scaling to intelligent computation. Without prioritizing reasoning, continued investment in data and scale may yield progressively smaller gains, potentially leading to a plateau in overall AI capabilities.
Current trajectories in artificial intelligence development increasingly indicate that simply increasing dataset size and model parameters will yield diminishing returns. Consequently, a pivotal shift in research emphasis is becoming necessary-one that prioritizes the creation of more efficient and robust reasoning algorithms. This isn’t merely about processing information faster, but about enabling AI to genuinely understand and extrapolate from data, exhibiting capabilities akin to human logical thought. Investigations are now focusing on novel algorithmic approaches – including symbolic reasoning, neuro-symbolic integration, and advanced knowledge representation – designed to maximize reasoning efficiency rather than solely computational power. Successfully refining these algorithms could unlock a new phase of AI progress, allowing systems to tackle complex problems with significantly less data and computational resources, and potentially circumventing the anticipated plateau in performance gains from scale alone.
Current trajectories in artificial intelligence development suggest diminishing returns from simply increasing data volume and model scale, potentially leading to a plateau in base capabilities around November 21, 2024. Consequently, future progress hinges on a fundamental shift towards architectural designs that prioritize reasoning efficiency. This necessitates exploring novel approaches beyond conventional scaling, focusing instead on algorithms that can extract more value from existing data and knowledge. Projections indicate that a critical inflection point for enhancing reasoning capabilities – the ability to not just process information, but to understand and apply it – is estimated to occur around June 6, 2026, beyond which advancements will likely depend more on qualitative improvements in reasoning than quantitative increases in scale.
The pursuit of ever-increasing AI capabilities often resembles attempts to force growth, rather than nurture it. This paper’s exploration of a sigmoid curve, suggesting a potential plateau in AI advancement, echoes a fundamental truth about complex systems. As Ken Thompson observed, “Software is like entropy: It is difficult to stop it from becoming messy.” Just as entropy increases with complexity, so too does the challenge of sustaining exponential growth in AI. The emphasis on reasoning as a critical factor isn’t about achieving more scale, but cultivating a more resilient and adaptable system-one that can navigate the inevitable complexities and limitations inherent in any growing intelligence. It’s a shift from building bigger engines to tending a flourishing garden.
The Horizon Recedes
The assertion of diminishing returns in scaling alone feels less a prediction than an observation of history repeating. Every new architecture promises freedom until it demands DevOps sacrifices. The pursuit of ever-larger models, while yielding demonstrable gains, increasingly resembles pushing against a sigmoid curve-a fleeting sense of exponential ascent giving way to the inevitable plateau. The true challenge, then, isn’t simply more parameters, but a fundamental shift in what ‘capability’ even signifies.
Reasoning, as this work highlights, appears to be a crucial lever. Yet, focusing solely on benchmark scores feels like polishing the brass on a sinking ship. The real question is whether improved reasoning represents genuine understanding, or merely a more sophisticated mimicry of it. The field chases metrics, while the underlying fragility of these systems – their susceptibility to subtle prompt manipulation, their lack of common sense – remains largely unaddressed.
Order is just a temporary cache between failures. The horizon of ‘artificial general intelligence’ recedes with every advancement, not because it’s unattainable, but because the definition of ‘intelligence’ itself shifts. Perhaps the most fruitful path lies not in building more capable systems, but in understanding the inherent limitations of computation, and accepting that true intelligence may reside not in flawless execution, but in graceful adaptation to inevitable chaos.
Original article: https://arxiv.org/pdf/2602.04836.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Top 10 Coolest Things About Jared Leto
2026-02-05 14:53