Author: Denis Avetisyan
New research reveals that simply improving a model’s performance on familiar data doesn’t guarantee it will reliably identify data it hasn’t seen before.
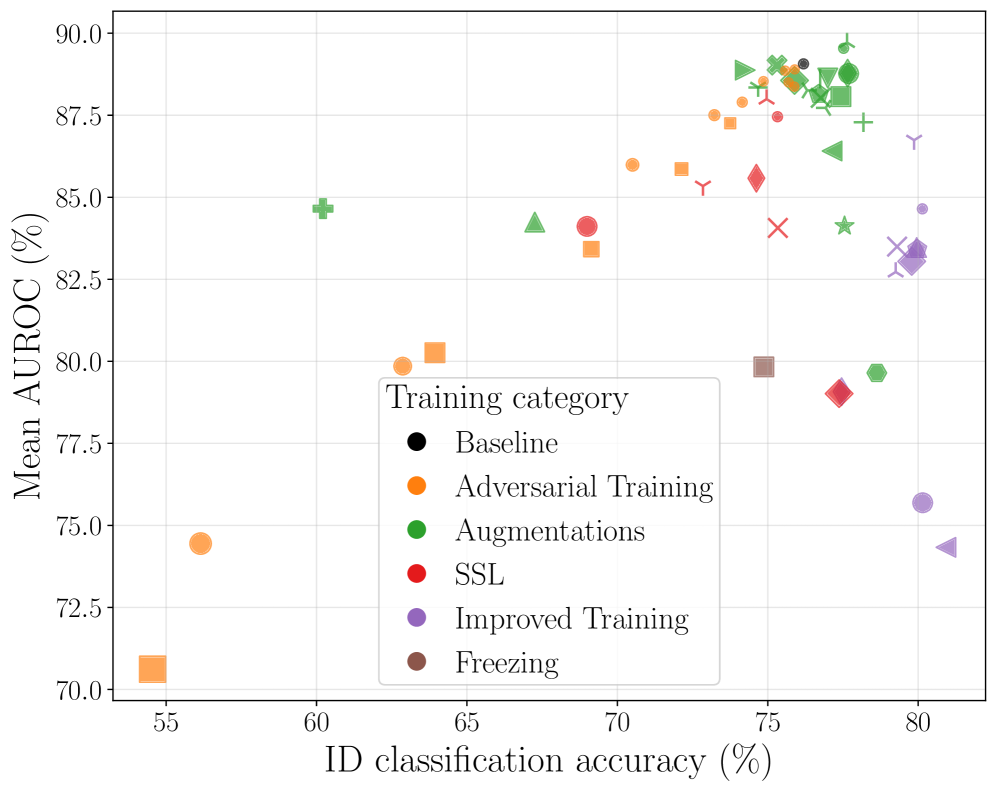
Training strategies significantly impact out-of-distribution (OOD) detection, demonstrating that in-distribution accuracy and OOD performance are not always correlated.
Despite advances in machine learning, deploying robust systems in real-world scenarios requires reliable detection of out-of-distribution (OOD) data-a capability often assumed to improve alongside in-distribution accuracy. This research, titled ‘One Model, Many Behaviors: Training-Induced Effects on Out-of-Distribution Detection’, challenges this assumption through a comprehensive empirical study of 56 ImageNet-trained ResNet-50 models. We uncover a non-monotonic relationship where OOD performance initially improves with accuracy but declines as training pushes models to peak in-distribution performance, revealing a strong interdependence between training strategy, detector choice, and resulting OOD capabilities. Given these findings, how can we design training pipelines that explicitly optimize for both in-distribution generalization and robust out-of-distribution detection?
The Whispers Beyond the Training Data
Deep learning models consistently demonstrate remarkable performance when processing data similar to what they were trained on – a characteristic known as in-distribution (ID) accuracy. However, this proficiency often falters dramatically when confronted with inputs that deviate from this familiar scope, termed out-of-distribution (OOD) data. This vulnerability isn’t merely a statistical quirk; it represents a significant safety concern in real-world applications such as autonomous driving or medical diagnosis. A system confidently misclassifying an unfamiliar object, or providing an incorrect diagnosis based on atypical symptoms, can have severe consequences. The core issue is that these models, while adept at recognizing patterns within their training data, lack the capacity to reliably identify – and signal uncertainty about – inputs that lie outside this learned distribution. Consequently, ensuring robustness to OOD data is a critical challenge for the widespread and responsible deployment of deep learning technologies.
Deep learning models, despite achieving remarkable accuracy on familiar data, exhibit a significant vulnerability when encountering inputs outside their training distribution. This stems from a tendency towards overconfidence; even when presented with wholly unfamiliar scenarios, these models often assign high probability to incorrect predictions, offering no indication of their own uncertainty. Consequently, reliable uncertainty estimation becomes paramount for safe deployment in real-world applications, particularly in safety-critical domains where misclassification could have severe consequences. The ability to accurately quantify a model’s confidence – or lack thereof – allows for informed decision-making, enabling systems to defer to human intervention or employ alternative strategies when facing genuinely novel or ambiguous inputs, mitigating the risk of silent failures.
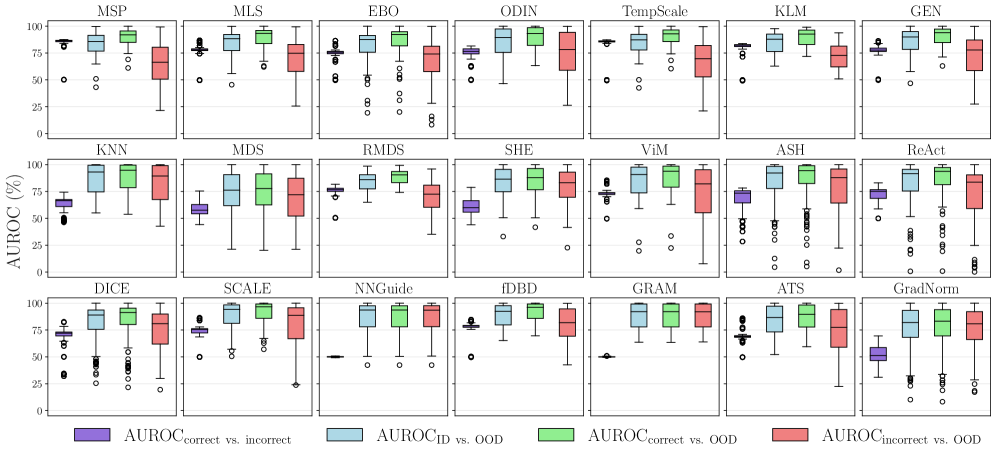
Assessing a deep learning model’s ability to identify genuinely novel data-out-of-distribution (OOD) detection-demands metrics extending beyond simple accuracy scores. While high accuracy on familiar data is desirable, it proves an unreliable indicator of OOD detection capability; research demonstrates a remarkably weak correlation of just 0.04 between in-distribution accuracy and OOD detection performance. Consequently, metrics like Area Under the Receiver Operating Characteristic curve (AUROC) and False Positive Rate at 95% recall (FPR95) are essential, as they quantify the crucial trade-off between correctly flagging unfamiliar inputs and avoiding unnecessary alarms on valid data. These robust evaluations are critical because a model proficient at classifying known data can still exhibit dangerously overconfident, yet incorrect, predictions when confronted with previously unseen scenarios.
Detecting the Unseen: A Toolkit of Methods
Out-of-distribution (OOD) detection encompasses a diverse set of techniques, varying in complexity and computational cost. Simpler methods, such as Maximum Softmax Probability (MSP) and Maximum Logit Score (MLS), rely on the model’s output probabilities or logits without requiring additional training. These methods assess OOD inputs based on their low confidence scores. More sophisticated techniques operate within the feature space, analyzing the distribution of input representations learned by the neural network. These approaches often involve calculating distances to known in-distribution data, estimating densities, or learning decision boundaries to differentiate between familiar and novel inputs, requiring additional computational resources and, in some cases, retraining or fine-tuning.
Energy-based Out-of-Distribution (OOD) detection methods operate on the principle that in-distribution data will exhibit lower ‘energy’ values compared to OOD samples. This ‘energy’ is mathematically defined as the negative log-likelihood of the input under a learned model, or an approximation thereof. Techniques like Simplified Hopfield Energy (SHE) further refine this by utilizing a simplified energy function based on the model’s parameters and input features. The core assumption is that the model assigns higher probabilities, and thus lower energy, to data similar to the training distribution. Consequently, a higher energy score indicates a greater dissimilarity to the training data, flagging the input as potentially OOD. These methods do not require explicit density estimation, making them computationally efficient for OOD detection tasks.
ODIN (Out-of-distribution detector for neural networks) improves OOD detection by intentionally perturbing the input with a small, carefully calculated gradient-based perturbation, effectively increasing the confidence of correct in-distribution predictions and sharpening the separation between in-distribution and OOD samples. Conversely, SCALE (Smooth Confidence Calibration) focuses on shaping the internal feature representations of the neural network; it applies temperature scaling to the logits before the softmax layer, recalibrating the confidence scores and enhancing the discriminative power of the model without directly modifying the input. Both methods aim to improve the reliability of confidence scores as a proxy for OOD detection, but achieve this through fundamentally different mechanisms – input manipulation versus internal representation adjustment.
The Mahalanobis Distance Score assesses the distance between a data point’s feature representation and the distribution of in-distribution data, accounting for feature correlations and variances; a larger distance indicates a potential out-of-distribution sample. ReAct (Robust Activation Clipping) addresses the issue of adversarial vulnerability and improves model robustness by clipping activations within a defined range, preventing excessively large or small values that can lead to misclassifications, particularly from subtly perturbed inputs. This clipping process aims to maintain stable internal representations and improve generalization to unseen data, enhancing the reliability of OOD detection.
Forging Robustness: Training Beyond the Familiar
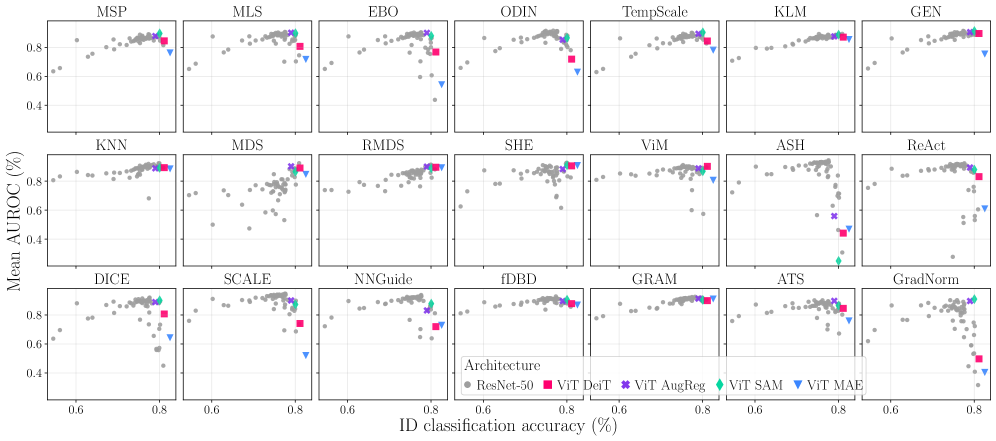
ResNet-50 has historically been the predominant architectural choice for research into out-of-distribution (OOD) detection methodologies due to its established performance and widespread availability in benchmark datasets. However, recent investigations are increasingly utilizing Vision Transformer (ViT) architectures to evaluate generalizability and assess whether transformer-based models exhibit improved OOD detection capabilities compared to convolutional neural networks. This shift reflects the growing interest in exploring architectures beyond ResNet-50, with ViTs offering potentially more robust feature representations and better performance on unseen data distributions, although comparative analyses are ongoing to fully understand the trade-offs between these architectures in the context of OOD detection.
Adversarial Training, MixUp, and CutMix represent data augmentation strategies demonstrably effective in enhancing model generalization. Adversarial Training introduces perturbations to input samples designed to maximize loss, forcing the model to learn more robust features. MixUp creates new training samples by linearly interpolating between pairs of inputs and their corresponding labels, promoting smoother decision boundaries. CutMix, conversely, replaces regions of one image with those from another, along with a corresponding mix of labels, encouraging the model to attend to multiple parts of the input. Implementation of these techniques during the training phase has been shown to improve performance on both in-distribution and out-of-distribution datasets by increasing the model’s resilience to noisy or atypical inputs.
Regularization techniques, specifically Label Smoothing and Exponential Moving Averages (EMA), contribute to improved model generalization and prediction accuracy. Label Smoothing mitigates overfitting by replacing hard target labels with a softened distribution, reducing the model’s confidence in potentially noisy or mislabeled training examples. EMA, applied to model weights during training, creates an exponentially decaying average of past weights, effectively stabilizing the learning process and preventing drastic updates that can lead to overfitting. This results in models that not only achieve higher accuracy on in-distribution data but also exhibit better calibrated confidence scores, crucial for reliable out-of-distribution detection, as overconfident but incorrect predictions are minimized.
Contrastive Learning is a training technique that aims to improve the robustness of feature representations learned by a model, thereby increasing its ability to differentiate between in-distribution and out-of-distribution data. However, analysis indicates that the interaction between specific training strategies, including Contrastive Learning, and the chosen Out-of-Distribution (OOD) detection method accounts for 21.05% of the variance in Area Under the Receiver Operating Characteristic curve (AUROC). This finding underscores the importance of evaluating not only individual training techniques and OOD detectors in isolation, but also the combined performance of different pairings to optimize overall OOD generalization capabilities.
The Ghosts in the Machine: Calibration and the Limits of Data
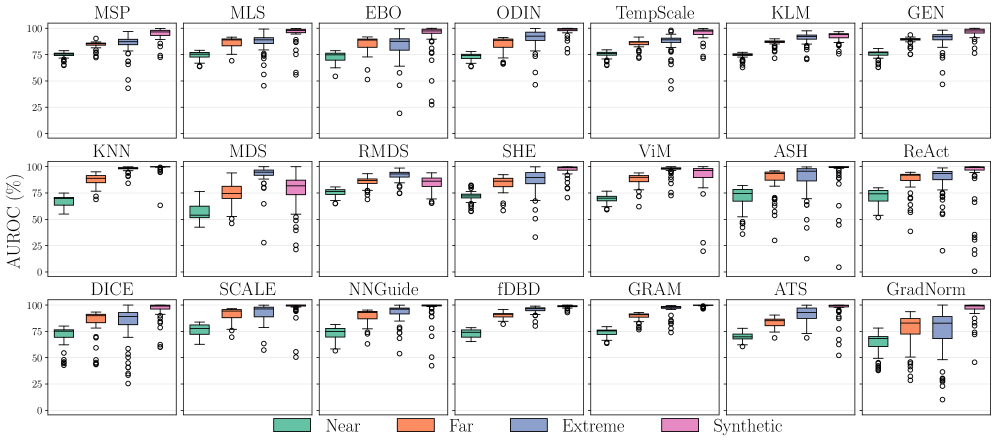
The widespread practice of pre-training computer vision models on the ImageNet dataset, while effective for many tasks, doesn’t automatically translate to robust performance when encountering data drastically different from its training distribution. Researchers have demonstrated that the specific dataset used for pre-training exerts a significant influence on a model’s ability to detect out-of-distribution (OOD) inputs – data the model hasn’t seen before. This is because the features learned during pre-training become biased toward the characteristics of that initial dataset; a model trained solely on ImageNet, for example, may struggle to generalize to images with different styles, textures, or even entirely different subject matter. Consequently, careful consideration of the pre-training dataset is essential for building models capable of reliably identifying unfamiliar data and quantifying the associated uncertainty, a critical requirement for safe and dependable real-world applications.
Detecting inputs that fall outside of a model’s training distribution – known as out-of-distribution (OOD) detection – isn’t simply about flagging the unfamiliar; it fundamentally requires a reliable assessment of the model’s own confidence. A model might correctly identify a novel input, but without accurately quantifying its uncertainty about that prediction, the detection is less useful and potentially misleading. This is where model calibration becomes paramount. A well-calibrated model’s predicted probabilities should reflect the actual likelihood of correctness – a prediction with 90% confidence should be correct roughly 90% of the time. Poorly calibrated models can be overconfident in incorrect predictions or underconfident in correct ones, hindering effective OOD detection and limiting the deployment of these systems in safety-critical applications. Therefore, advancements in OOD detection increasingly focus not only on recognizing novel data but also on ensuring that models provide trustworthy estimates of their own predictive uncertainty.
The efficacy of out-of-distribution (OOD) detection hinges significantly on the characteristics of the feature space a model learns; this space fundamentally determines a model’s ability to distinguish between familiar, in-distribution data and novel, out-of-distribution inputs. A well-structured feature space allows for clear separation between these two types of data, enabling the model to confidently identify anomalies. Conversely, a poorly formed space, perhaps due to dataset bias or insufficient representation learning, can lead to ambiguous representations where OOD inputs are incorrectly classified as in-distribution. Consequently, researchers are increasingly focused on analyzing and manipulating these learned feature spaces-through techniques like dimensionality reduction or the application of specific regularization methods-to enhance the discriminative power of OOD detection systems and improve their reliability in real-world applications. Understanding this underlying structure is therefore not merely a theoretical concern, but a practical necessity for designing robust and trustworthy OOD detection methods.
Recent advancements in out-of-distribution (OOD) detection explore methods for refining how models interpret data, with techniques like GRAM and ASH demonstrating promising results. GRAM focuses on characterizing intermediate feature statistics to better distinguish novel inputs, while ASH strategically prunes activations to enhance the model’s focus on relevant features. However, a detailed analysis reveals that the inherent difficulty of various OOD datasets significantly impacts detection performance, accounting for over 34% of the variance in Area Under the Receiver Operating Characteristic (AUROC). This finding underscores the substantial challenge of creating OOD detection systems that reliably generalize across diverse and unpredictable real-world scenarios, suggesting that simply improving model architecture or training procedures may not be sufficient without addressing dataset-specific biases and complexities.
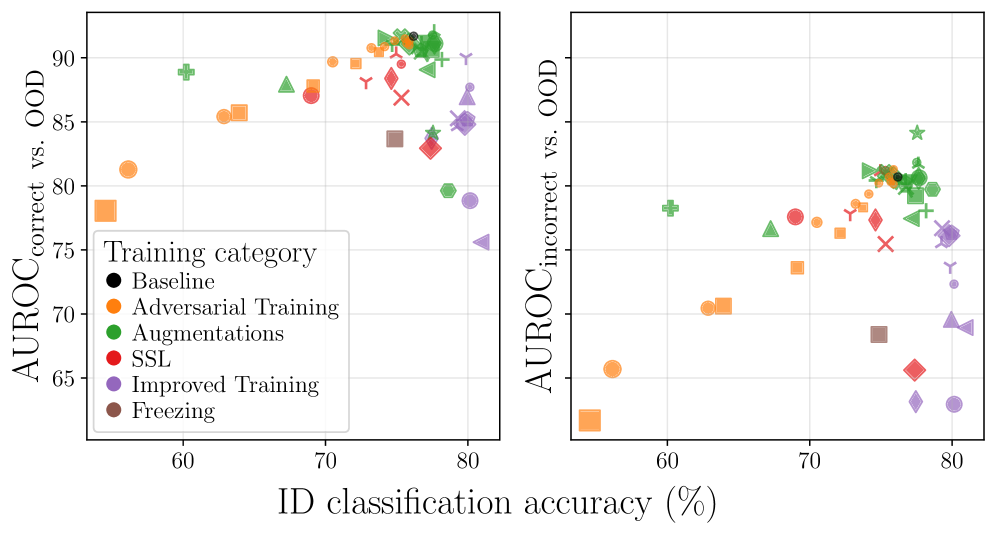
The pursuit of immaculate in-distribution accuracy, it seems, is merely a sophisticated ritual. This research confirms what any seasoned practitioner already suspects: a model’s performance is less about ‘truth’ and more about the particular incantation used to coax it into submission. The feature space, sculpted by training strategies, isn’t a neutral landscape reflecting inherent data properties, but a carefully constructed illusion. As Yann LeCun aptly stated, “Backpropagation is the dark art of training neural networks.” The study’s findings on OOD detection demonstrate that a higher ID score doesn’t guarantee robustness; it simply suggests a more convincing spell. The model doesn’t generalize; it persuades.
The Road Ahead
The pursuit of reliable out-of-distribution (OOD) detection remains, predictably, elusive. This work doesn’t so much solve a problem as map the contours of its messiness. The observed disconnect between in-distribution accuracy and OOD performance isn’t a bug; it’s a feature of any system attempting to generalize from finite, biased samples. Higher accuracy, it turns out, often buys you a more confident error-a prettier lie. The feature spaces sculpted by various training regimes aren’t neutral canvases; they’re subtly warped mirrors, reflecting the training data’s inherent prejudices.
Future work will likely focus on less glamorous tasks than chasing ever-higher accuracy. A deeper understanding of why certain training strategies yield more ‘honest’ feature spaces is crucial. Perhaps the real metric isn’t how well a model performs on known data, but how readily it admits its ignorance. The field might also benefit from abandoning the pretense of a universal OOD detector and embracing specialized systems, tailored to specific data distributions and failure modes. After all, noise isn’t a flaw-it’s truth without funding.
One suspects that the ultimate limit isn’t algorithmic, but metaphysical. There’s a fundamental asymmetry between knowing what is and not knowing what isn’t. A model can be exquisitely sensitive to patterns within its training data, but it remains, at its core, a pattern-matching machine, incapable of truly understanding the vastness of the unknown. Correlation’s high? Someone cheated. And the data, as always, remembers everything, and reveals nothing.
Original article: https://arxiv.org/pdf/2601.10836.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-20 20:12