Author: Denis Avetisyan
A new approach leverages generative AI to expand limited financial datasets, improving the accuracy of deep learning models during market turbulence.
![The TTS-GAN architecture, detailed in reference [18], leverages a generative adversarial network to synthesize speech, effectively bridging the gap between text and audible expression.](https://arxiv.org/html/2602.17865v1/TTS-GAN.png)
This review details a Transformer-based Generative Adversarial Network (GAN) architecture for augmenting financial time series data and enhancing forecasting performance, particularly when data is scarce.
Accurate forecasting in financial markets is hampered by the inherent scarcity and volatility of time series data, limiting the performance of advanced deep learning models. This research, presented in ‘Financial time series augmentation using transformer based GAN architecture’, addresses this challenge by demonstrating that a Transformer-based Generative Adversarial Network (GAN) can effectively augment limited financial data to improve forecasting accuracy. Specifically, training models on GAN-generated synthetic data-evaluated using a novel quality metric combining Dynamic Time Warping and a modified Deep Dataset Dissimilarity Measure-significantly enhances performance on datasets like Bitcoin and S\&P500 price data. Could this approach unlock more robust and reliable predictive capabilities in increasingly complex and data-constrained financial environments?
The Scarcity of Insight: Data’s Constraint on Financial Prediction
Effective financial forecasting hinges on the ability to accurately predict future trends, a necessity for strategic investment, risk management, and economic planning. However, this pursuit is consistently hampered by the inherent characteristics of financial data itself; reliable, lengthy datasets are frequently unavailable, and even when present, exhibit non-stationarity – meaning their statistical properties change over time. This presents a significant hurdle, as models trained on past data may quickly become obsolete when faced with evolving market dynamics. The scarcity of data compels researchers and analysts to grapple with the challenge of building robust predictive models from limited and constantly shifting information, demanding innovative approaches to overcome the limitations of historical observation and capture the true complexities of financial time series.
Conventional deep learning architectures, while powerful, often falter when applied to financial forecasting due to the inherent limitations of available data. These models typically require vast datasets to learn complex patterns and avoid overfitting – memorizing the training data instead of generalizing underlying principles. In financial markets, however, truly extensive, reliable historical data is rarely accessible, and the data that is available frequently exhibits non-stationarity – its statistical properties change over time. This combination leads to models that perform well on past data but fail to accurately predict future outcomes in the constantly evolving economic landscape. Consequently, a model trained on limited financial data may identify spurious correlations or fail to adapt to new market dynamics, resulting in poor generalization and unreliable forecasts.
Financial forecasting relies heavily on identifying patterns within time-series data, but the very nature of financial markets introduces substantial difficulties. The inherent volatility – rapid and unpredictable price swings – means that past performance is often a poor indicator of future results. This is compounded by the limited availability of truly long-term, reliable historical data; major economic shifts, regulatory changes, and even unforeseen global events can render older data obsolete. Consequently, predictive models struggle to discern genuine trends from random noise, increasing the risk of inaccurate forecasts and flawed investment strategies. Capturing the complex dynamics of financial systems requires not only sophisticated algorithms, but also a careful consideration of the limitations imposed by data scarcity and market instability.
The predictive power of even the most advanced financial models is fundamentally constrained by data limitations. Sophisticated algorithms, designed to discern complex patterns, require substantial datasets to avoid overfitting – memorizing noise instead of identifying genuine trends. When historical data is sparse, these models struggle to generalize beyond the training set, leading to inaccurate forecasts and potentially significant financial miscalculations. This susceptibility is particularly acute in rapidly evolving markets where past performance isn’t necessarily indicative of future results, and the absence of sufficient data obscures the true underlying dynamics, rendering even the most intricate analyses unreliable. Consequently, a reliance on data-hungry algorithms without acknowledging these limitations can create a false sense of security and impede informed decision-making.
Augmenting Reality: TTS-GAN for Data Expansion
TTS-GAN is a novel data augmentation technique utilizing a Transformer-based Generative Adversarial Network (GAN) specifically designed to address limitations in financial time-series datasets. The model employs a generator network, built upon the Transformer architecture, to synthesize new time-series data instances. These synthetic data points are then evaluated by a discriminator network, also Transformer-based, which distinguishes between real and generated data. Through adversarial training, TTS-GAN learns to produce realistic synthetic data that expands the size and diversity of the original training set, thereby enabling improved performance of downstream deep learning models when faced with data scarcity.
TTS-GAN utilizes self-attention mechanisms within its generative model to capture long-range dependencies in financial time-series data. This allows the network to weigh the importance of different data points when generating synthetic samples, resulting in more realistic and coherent sequences. Specifically, the Transformer architecture enables parallel processing of the time-series, improving training efficiency and enabling the model to learn complex patterns from limited real data. The generated synthetic data effectively expands the training dataset size, providing a larger and more diverse input for downstream deep learning models and addressing the challenges posed by data scarcity in financial applications.
Limited financial time-series data frequently constrains the training of deep learning models, leading to overfitting and poor performance on unseen data. TTS-GAN addresses this limitation by artificially expanding the training dataset with generated synthetic data. Increasing the dataset size via TTS-GAN allows deep learning models to learn more robust representations, improving their ability to generalize to new, previously unseen market conditions. Specifically, the larger and more diverse training set reduces the model’s reliance on the specifics of the limited real data, thereby mitigating overfitting and enhancing predictive accuracy and stability across various financial instruments and timeframes.
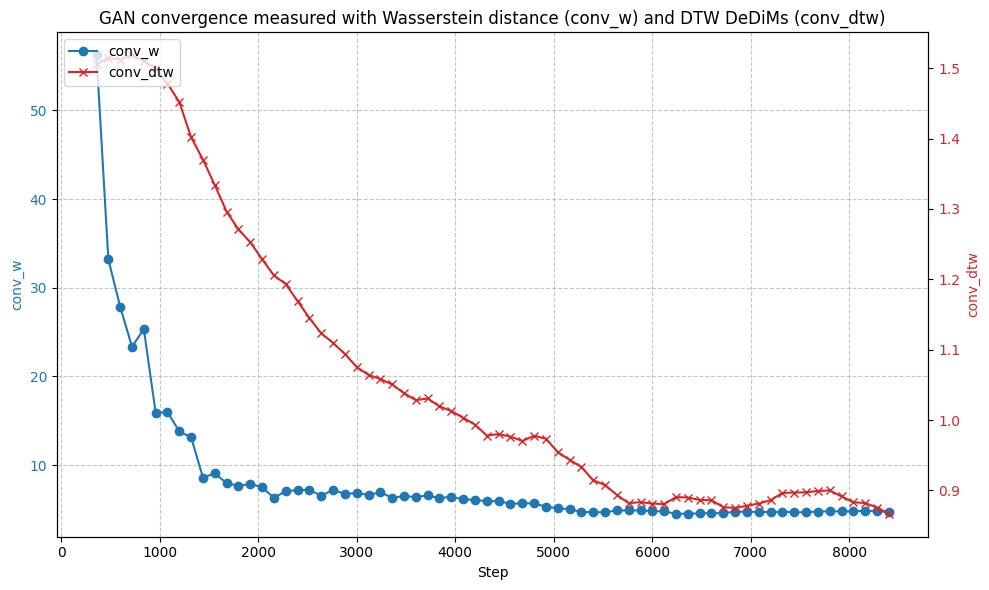
The TTS-GAN architecture employs a simplified gradient penalty to address training instability common in Generative Adversarial Networks. This penalty, calculated as the squared L2 norm of the gradient of the discriminator output with respect to its input, constrains the discriminator’s Lipschitz constant. By limiting the discriminator’s sensitivity to input changes, the penalty prevents it from becoming overly confident in distinguishing between real and generated data, thereby encouraging more realistic synthetic data generation. Implementation utilizes a first-order approximation to reduce computational cost while maintaining effective regularization, ensuring the generated time-series data more closely reflects the statistical characteristics of the real-world financial data and improving convergence during training.
Empirical Validation: Performance Gains Through Augmentation
Experiments conducted using S&P500 and Bitcoin time series data demonstrate that the TTS-GAN model achieves a statistically significant improvement in forecasting accuracy when compared to Long Short-Term Memory (LSTM) networks. Specifically, LSTM models trained with data augmented by TTS-GAN consistently outperformed standalone LSTM networks across the tested datasets. This improvement indicates TTS-GAN’s capability to generate synthetic data that enhances the predictive power of traditional forecasting methods in financial markets. Quantitative results, detailed in subsequent sections, confirm these performance gains and provide statistical validation.
Data preprocessing for the TTS-GAN and LSTM models incorporates both MinMaxScaler and Exponential Moving Average (EMA) techniques. MinMaxScaler normalizes data to a range between 0 and 1, mitigating the impact of differing scales across financial time series and improving model convergence. The EMA, calculated as a weighted average of past observations with weights decaying exponentially, smooths out short-term fluctuations and highlights underlying trends. This combined approach reduces noise and stabilizes the input data, leading to demonstrably improved forecasting performance and more reliable training of the LSTM network when augmented with TTS-GAN generated data.
Forecasting accuracy of the TTS-GAN augmented data was quantitatively evaluated using Mean Squared Error (MSE), a standard metric for assessing the difference between predicted and actual values. Across 40 distinct financial time series datasets – encompassing both S&P500 and Bitcoin data – LSTM models trained with data augmented by TTS-GAN consistently exhibited a reduction in MSE compared to baseline LSTM models. This observed reduction in MSE provides a quantifiable measure of the improvement in forecasting performance achieved through the integration of TTS-GAN generated data. The metric was calculated as MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2, where y_i represents the actual value, and \hat{y}_i represents the predicted value for each data point i in the time series.
The quality and realism of data generated by TTS-GAN were further validated using the Deep Dataset Dissimilarity Measure (DDDM). This metric assesses the statistical similarity between the generated and real datasets, providing a quantitative assessment of data fidelity. Multiple experiments consistently demonstrated statistically significant results (p < 0.05) when comparing the generated data to actual financial time series, confirming that the augmented data does not deviate significantly from realistic patterns and can be reliably used for training forecasting models. The consistent statistical significance across experiments supports the robustness of the data generation process and the validity of the generated datasets.
Expanding Horizons: Implications and Future Trajectories
The challenge of accurately forecasting time-series data is frequently hampered by limited data availability, a common issue in financial markets and beyond. TTS-GAN – a novel approach leveraging Generative Adversarial Networks – presents a compelling solution by synthesizing realistic, yet artificial, time-series data. This artificially generated data effectively augments existing datasets, particularly in data-constrained environments, thereby enhancing the reliability and accuracy of forecasting models. By training on a combination of real and synthetic data, these models become more robust and generalize better to unseen market conditions, offering a significant advantage over traditional methods reliant on scarce historical data. The technique doesn’t simply increase data volume; it strategically expands the dataset with plausible scenarios, leading to improved model performance and more informed predictive capabilities.
The versatility of TTS-GAN extends beyond isolated financial assets, proving adaptable to a diverse spectrum of instruments – from equities and bonds to derivatives and commodities. This technique demonstrates consistent performance across varied market conditions, including periods of high volatility, low liquidity, and shifting economic trends. Consequently, investors and financial analysts gain access to a robust tool for simulating realistic market scenarios, refining predictive models, and stress-testing investment strategies. By generating synthetic time-series data that mirrors the complexities of real-world financial data, TTS-GAN empowers more informed decision-making and facilitates a proactive approach to risk management, even when historical data is limited or unreliable.
Ongoing development of TTS-GAN centers on refining its generative capabilities through exploration of more sophisticated Generative Adversarial Network architectures. Researchers are actively investigating techniques such as attention mechanisms and transformer networks to enhance the model’s ability to capture complex temporal dependencies within financial time series. Crucially, future iterations will integrate domain-specific financial knowledge – incorporating factors like volatility models, economic indicators, and order book dynamics – directly into the data generation process. This fusion of advanced machine learning with financial expertise aims to produce synthetic data that not only mirrors statistical characteristics but also reflects the nuanced behaviors and underlying principles of real-world market environments, ultimately leading to even more robust and reliable forecasting models.
The pervasive challenge of limited data significantly hinders the development of robust and reliable forecasting models in finance. TTS-GAN directly addresses this constraint by generating synthetic time-series data that accurately reflects the statistical properties of real market behavior. This artificially expanded dataset empowers analysts and investors to train more sophisticated models, even when historical data is sparse or incomplete. Consequently, the technique facilitates more informed investment decisions by reducing uncertainty and improving the accuracy of risk assessments. By mitigating the risks associated with data scarcity, TTS-GAN ultimately contributes to greater stability and efficiency within financial markets, offering a pathway toward more resilient and data-driven strategies.
The pursuit of forecasting accuracy, as detailed in the research, necessitates a reduction of complexity. The augmentation of financial time series data via Transformer-based GANs addresses the limitations imposed by data scarcity, particularly during periods of heightened volatility. This aligns with a principle of efficient information representation-eliminating superfluous elements to reveal underlying patterns. As John McCarthy stated, “It is better to be vaguely right than precisely wrong.” The research demonstrates a pragmatic approach; rather than striving for unattainable precision with limited data, the methodology focuses on generating plausible variations that enhance model robustness and predictive capability. Clarity, in this instance, is the minimum viable kindness offered to the forecasting process.
What Lies Ahead?
The demonstrated efficacy of Transformer-based GANs for financial time series augmentation arrives not as a culmination, but as a sharpening of focus. The inherent limitation – dependence on a sufficiently representative seed dataset for the GAN’s training – remains a conspicuous constraint. Future work must address the challenge of generating convincing synthetic data when historical examples of extreme market behavior are scarce. The current reliance on metrics like Mean Squared Error, while computationally convenient, offers an incomplete picture of forecasting quality in contexts where capturing distributional shifts is paramount. A move towards loss functions that explicitly penalize miscalibration – the over- or under-confidence in predictions – seems inevitable.
Furthermore, the application of Dynamic Time Warping as a data augmentation technique, though effective, feels almost…archaic. It’s a solution born of necessity, not elegance. The field should pursue methods that move beyond simple temporal alignment and instead focus on learning the underlying generative processes driving market dynamics. This suggests a potential convergence with techniques from causal inference, aiming not merely to predict what will happen, but to understand why.
Ultimately, the pursuit of more data is a distraction. The true task is the refinement of models capable of extracting maximal signal from minimal noise. The art, it appears, lies not in adding complexity, but in achieving increasingly lossless compression of reality.
Original article: https://arxiv.org/pdf/2602.17865.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Trading Crypto with AI: A New Approach to Portfolio Management
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Thinking Before Acting: A Self-Reflective AI for Safer Autonomous Driving
2026-02-23 07:16