Author: Denis Avetisyan
Generating realistic financial datasets without revealing sensitive customer information is a growing challenge, and new research highlights the difficult tradeoffs involved.
This review assesses the privacy risks and utility loss associated with differentially private synthetic data generation for tabular financial data, focusing on membership inference attacks and the evaluation of privacy-utility tradeoffs.
Balancing data utility with stringent privacy demands remains a core challenge in modern data science, particularly within highly regulated sectors. This is the focus of ‘Measuring Privacy Risks and Tradeoffs in Financial Synthetic Data Generation’, which investigates the privacy-utility tradeoff of generating synthetic tabular data for financial applications-a domain characterized by both high regulatory risk and severe class imbalance. The study demonstrates that while differentially private synthetic data generation offers privacy protections, achieving acceptable data quality and downstream utility requires careful consideration of generator choice and rigorous evaluation against membership inference attacks. Given the increasing reliance on synthetic data, how can we develop more robust and reliable methods for quantifying and mitigating privacy risks without sacrificing valuable analytical insights?
Data Shadows: The Erosion of Access and the Rise of the Synthetic
Machine learning algorithms thrive on data, yet access to this crucial resource is becoming increasingly difficult. Stricter privacy regulations, such as GDPR and CCPA, alongside growing concerns over data security, are significantly limiting the availability of real-world datasets. Organizations are hesitant to share sensitive information – be it personal health records, financial transactions, or user behavior – due to legal ramifications and the risk of breaches. This constriction isn’t merely a legal hurdle; it actively impedes innovation across numerous fields, from medical diagnostics and fraud detection to autonomous vehicle development and personalized marketing. Consequently, researchers and developers face substantial challenges in training robust and reliable machine learning models, highlighting the urgent need for alternative data sources and techniques that prioritize privacy without sacrificing analytical power.
The escalating ambition to train robust and generalized machine learning models necessitates increasingly large and diverse datasets, a demand frequently stymied by practical realities. While algorithms crave breadth and detail, access to real-world data is often severely restricted due to growing privacy concerns, stringent regulations like GDPR, and the inherent sensitivity surrounding personal or proprietary information. Organizations grapple with the challenge of balancing innovation with legal and ethical obligations, finding that the datasets required to build truly effective models are either unavailable, prohibitively expensive to acquire, or require extensive – and often impossible – anonymization procedures. This widening gap between data need and data access is a significant bottleneck in the advancement of artificial intelligence, pushing researchers and developers to explore alternative data sources and methodologies.
Synthetic data generation is rapidly emerging as a pivotal solution to the increasing challenges of data access for machine learning. This innovative approach creates entirely artificial datasets that statistically replicate the properties of real-world data, allowing algorithms to be trained and tested without compromising individual privacy or breaching data governance regulations. Unlike anonymized datasets, which still carry residual risks of re-identification, synthetic data contains no direct links to sensitive personal information. The technology leverages techniques like generative adversarial networks (GANs) and variational autoencoders to learn the underlying patterns and distributions of real data, then produces new, comparable data points. This not only unlocks possibilities for innovation in data-scarce domains, such as healthcare and finance, but also facilitates broader access to data for researchers and developers, accelerating the development of robust and reliable artificial intelligence systems.
Forging Data: Methods for Tabular Synthesis
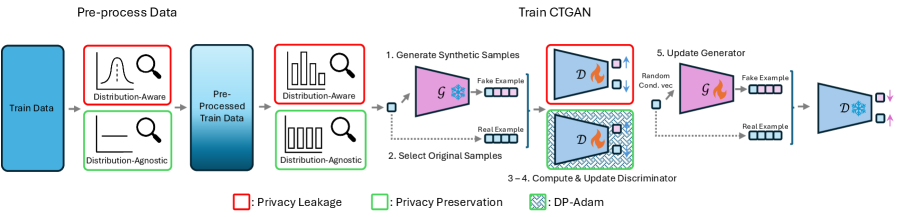
Multiple generative models are currently utilized for synthetic tabular data creation, each exhibiting distinct advantages and disadvantages. Gaussian Copula models represent a relatively simple approach, assuming a normal distribution for marginals and utilizing correlation to model dependencies, but may struggle with highly non-normal data. Tabular Variational Autoencoders (TVAE) employ variational autoencoders, effectively handling continuous variables and offering probabilistic outputs, though performance can be sensitive to hyperparameter tuning. Conversely, Conditional Tabular Generative Adversarial Networks (CTGAN) utilize Generative Adversarial Networks (GANs) to model complex, non-Gaussian categorical distributions, often achieving high fidelity but potentially suffering from training instability and mode collapse. The selection of an appropriate model depends on the characteristics of the specific dataset and the desired trade-offs between accuracy, stability, and computational cost.
Conditional Tabular Generative Adversarial Networks (CTGAN) utilize Generative Adversarial Networks (GANs) to synthesize tabular data, with a particular emphasis on accurately modeling complex, non-normal categorical variable distributions through the use of a stratified sampling approach and customized loss functions. In contrast, Tabular Variational Autoencoders (TVAE) employ variational autoencoders (VAEs) – probabilistic generative models – to learn a latent representation of the data, proving effective at handling continuous variables; the VAE framework allows for reconstruction of synthetic samples by decoding from the learned latent space, and incorporates a regularization term to encourage a well-behaved latent distribution.
TabDiff applies diffusion models – a class of generative models initially developed for image synthesis – to the generation of tabular data. This adaptation involves modeling the tabular data distribution as a diffusion process, progressively adding noise and then learning to reverse this process to generate synthetic samples. Evaluations of TabDiff demonstrate an average Column Shapes score of approximately 0.96, indicating high fidelity in replicating the original data’s column-wise statistical properties. However, implementations incorporating differential privacy – designed to protect individual data records – typically exhibit reduced Column Shapes scores due to the added noise required for privacy guarantees.
The Shield of Noise: Differential Privacy and Beyond
Differential Privacy (DP) is a mathematically defined system for measuring and limiting the disclosure of individual-level information within a dataset during data generation or analysis. It achieves this by adding calibrated noise to queries or algorithms, ensuring that the outcome remains largely unaffected by the presence or absence of any single data point. This is formally expressed using the concept of ε-differential privacy, where ε represents the privacy loss parameter; a smaller ε indicates a stronger privacy guarantee. DP doesn’t prevent all information leakage, but it provides a quantifiable bound on the risk of identifying specific individuals from the released data, enabling a trade-off between data utility and privacy protection.
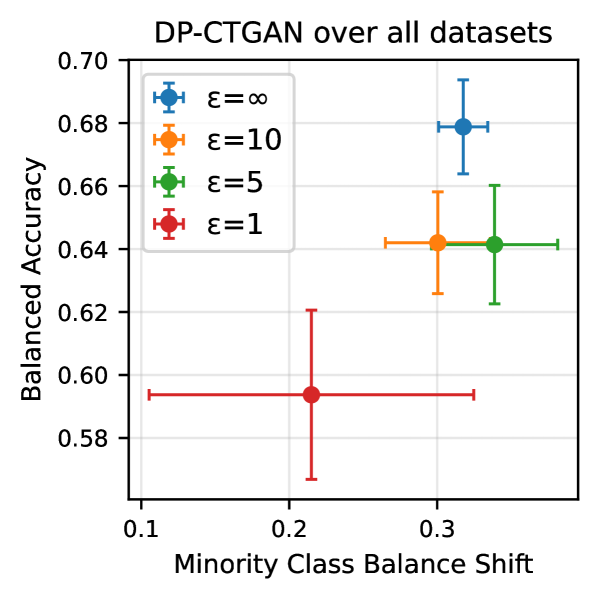
Both DP-CTGAN and DP-TVAE utilize differential privacy (DP) mechanisms to protect individual data records during the synthetic data generation process. These mechanisms function by adding calibrated noise to the training process, specifically to the gradients used in the generative adversarial network (GAN) or variational autoencoder (VAE) models. The amount of noise added is controlled by a privacy parameter, ε, which quantifies the privacy loss; smaller values of ε indicate stronger privacy protection but potentially reduce data utility. This calibrated noise ensures that the model’s output is not overly sensitive to any single individual’s data, thereby preventing or significantly hindering attempts at re-identification through techniques like membership inference attacks.
Membership inference attacks assess the risk of revealing whether a specific data record was used in the training of a generative model. A success rate of approximately 0.5 in such attacks indicates a non-random ability to distinguish between data originating from the training set and synthetically generated data. However, our research demonstrates that state-of-the-art generative models, specifically Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), can be successfully adapted to incorporate Differential Privacy (DP) mechanisms. This adaptation, while not eliminating the risk entirely, significantly reduces the potential for membership inference and provides a practical path toward generating privacy-preserving synthetic datasets.
The Value of Shadows: Assessing Utility and Risk
Evaluating the practical value of synthetic data hinges on its ‘downstream utility’ – a critical measure of how well machine learning models, trained exclusively on the generated data, perform when applied to real-world tasks. This isn’t simply about replicating statistical properties; it’s about ensuring the synthetic data effectively supports the intended application, whether that’s fraud detection, medical diagnosis, or customer behavior prediction. A high degree of downstream utility indicates the synthetic dataset captures the essential patterns and relationships present in the original data, allowing models to generalize effectively. Consequently, researchers and practitioners prioritize this metric when determining if synthetic data can reliably substitute for sensitive or scarce real-world information, fostering innovation while safeguarding privacy and overcoming data limitations.
The creation of truly useful synthetic data hinges on overcoming inherent challenges in the generation process, specifically class imbalance and mode collapse. Class imbalance, where certain categories are underrepresented, can lead to models trained on synthetic data exhibiting significant biases when applied to real-world scenarios. Similarly, mode collapse-a phenomenon where the generator produces a limited diversity of samples-results in synthetic datasets that fail to capture the full complexity of the original data distribution. Consequently, synthetic data may lack the variability needed to train robust and generalizable models. Mitigating these issues requires careful consideration of generation techniques and evaluation metrics, ensuring the synthetic data accurately reflects the characteristics of the real data and supports reliable downstream applications.
Evaluations of synthetic data utility, measured by Balanced Accuracy, reveal performance ranging from approximately 50% to 67% across different generative models and datasets. This variance highlights the sensitivity of synthetic data quality to both the chosen generation technique and the characteristics of the original data. Notably, the Differentially Private Conditional Tabular Generative Adversarial Network (DP-CTGAN) demonstrated comparable accuracy to its non-private counterpart, CTGAN, particularly when trained on datasets exhibiting balanced class distributions. This suggests that effective privacy-preserving techniques can be implemented without substantial compromise to the utility of the generated data, opening avenues for responsible data sharing and analysis.
The pursuit of synthetic financial data, as detailed in the study, inherently involves a delicate balancing act. Protecting individual financial records-a core concern when employing techniques like differential privacy-often diminishes the data’s practical value. This tension echoes Paul Erdős’ sentiment: “A mathematician knows a lot of things, but he doesn’t know everything.” The research demonstrates that achieving absolute privacy is often an impractical goal; rather, a carefully considered tradeoff between privacy and utility is necessary. Like a complex mathematical proof, the generation of synthetic data requires acknowledging limitations and accepting that perfect solutions rarely exist, even when striving for robust privacy guarantees.
What’s Next?
The pursuit of synthetic financial data, ostensibly to unlock innovation while safeguarding privacy, reveals a curious tension. Current methodologies, anchored in differential privacy, operate under the assumption that obscuring individual contributions equates to security. But what if the very noise introduced, intended as a shield, inadvertently highlights systemic vulnerabilities? The observed privacy-utility tradeoff isn’t simply a matter of fine-tuning parameters; it suggests a fundamental limit to how much information can be ‘sanitized’ without fundamentally altering the signal. Perhaps the focus shouldn’t be on perfect obfuscation, but on actively modeling – and even expecting – potential inference attacks.
Rigorous evaluation of privacy remains stubbornly elusive. Membership inference attacks, while potent tools, are themselves evolving, becoming increasingly sophisticated in their ability to bypass existing defenses. The field needs to move beyond treating these attacks as anomalies – as ‘bugs’ in the system – and begin to view them as integral components of a complex feedback loop. One wonders if the true metric isn’t how well privacy is preserved, but how quickly breaches are detected and mitigated.
Future work should explore the potential of adversarial training, not merely to defend against specific attacks, but to proactively identify and address inherent weaknesses in data generation processes. It might even be fruitful to consider deliberately introducing ‘decoys’ – plausible but false data points – to confuse attackers and raise the cost of successful inference. After all, sometimes the best way to protect a system is to let it be broken-intellectually, of course-and learn from the wreckage.
Original article: https://arxiv.org/pdf/2602.09288.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-02-11 15:42