Author: Denis Avetisyan
New research shows that influencing the learning of investment agents can overcome common hurdles in climate-focused financial modeling and lead to more effective sustainability outcomes.
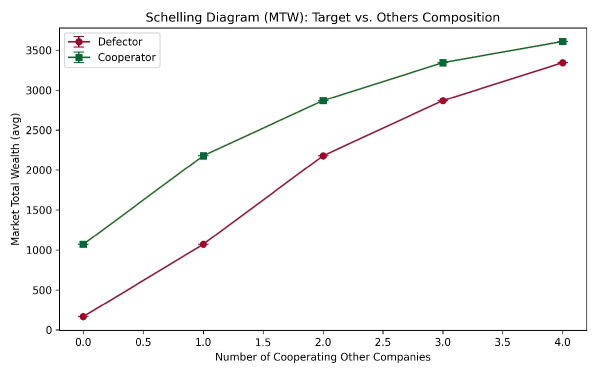
Advantage Alignment, a multi-agent reinforcement learning technique, effectively addresses social dilemmas in climate-finance simulations, improving investment strategies for ESG goals.
Addressing climate change necessitates global cooperation, yet individual economic actors frequently prioritize short-term gains over collective well-being, creating persistent social dilemmas. This challenge is explored in ‘Towards Sustainable Investment Policies Informed by Opponent Shaping’, which investigates a multi-agent simulation-InvestESG-modeling the interplay between investors and companies under climate risk. We demonstrate that strategically shaping agent learning via an algorithm called Advantage Alignment can systematically favor cooperative equilibria and improve outcomes compared to standard reinforcement learning approaches. Could this technique offer a pathway towards policy mechanisms that better align market incentives with long-term sustainability goals and mitigate climate-related financial risks?
The Escalating Climate Challenge and the Logic of Collective Action
The escalating climate crisis constitutes a challenge of unprecedented scale, impacting every corner of the globe and demanding a swift, unified response. Scientific evidence overwhelmingly demonstrates a rapidly changing climate, driven by human activities, and manifesting in rising temperatures, extreme weather events, and disruptions to ecosystems. Addressing this necessitates not merely incremental adjustments, but transformative shifts in energy production, consumption patterns, and land management practices. A truly effective solution requires international cooperation, encompassing policy changes, technological innovation, and substantial investment in sustainable infrastructure. The urgency stems from the potential for irreversible damage to the planet, threatening both environmental stability and human well-being, and highlighting the critical need for immediate, coordinated action to mitigate the worst effects and secure a sustainable future.
The pursuit of climate change mitigation is fundamentally complicated by social dilemmas, situations where individually rational choices lead to collectively suboptimal outcomes. Consider, for example, energy consumption: it is often personally advantageous to utilize resources freely, yet widespread adoption of this behavior jeopardizes the stability of the climate for everyone. This disconnect between individual incentives and collective well-being isn’t a failure of understanding, but a consequence of how decisions are structured; each actor, pursuing logical self-interest, inadvertently contributes to a shared problem. Resolving these dilemmas requires shifting the calculus of individual choices, either by highlighting the long-term benefits of cooperation, internalizing the costs of unsustainable actions, or fostering mechanisms that align personal gain with collective prosperity. Without addressing this inherent tension, even well-intentioned efforts to combat climate change risk being undermined by the predictable consequences of rational, self-interested behavior.
The core of the climate crisis lies in a fundamental conflict between immediate gains and future stability. Individuals and even nations often prioritize short-term economic benefits – such as inexpensive energy from fossil fuels or maximizing profits – without fully accounting for the long-term environmental costs. This isn’t necessarily malicious intent, but rather a rational response to incentives that fail to adequately value sustainability. The consequence is a tragic irony: actions undertaken to improve present conditions can inadvertently erode the very foundations upon which future prosperity depends. This pattern, observed across numerous environmental challenges, highlights the urgent need for systems that align individual incentives with collective well-being, fostering a future where short-term self-interest doesn’t compromise long-term sustainability.
Modeling Complex Interactions: The Power of Multi-Agent Reinforcement Learning
Multi-Agent Reinforcement Learning (MARL) extends the principles of single-agent reinforcement learning to scenarios involving multiple interacting agents. Unlike traditional RL where an agent learns in a static environment, MARL addresses environments where the actions of one agent directly influence the states and rewards of others. This necessitates algorithms capable of handling non-stationarity – the changing environment caused by concurrent learning – and the complexities of strategic interaction. MARL algorithms often employ techniques such as centralized training with decentralized execution, or consider each agent’s policy as a function of the policies of other agents, leading to solutions for cooperative, competitive, and mixed-motive scenarios. The framework is applicable to a wide range of problems, including robotics, game playing, resource allocation, and economic modeling.
The InvestESG environment utilizes Multi-Agent Reinforcement Learning (MARL) to simulate the dynamic relationships between corporations and investors facing climate-related financial risks. Specifically, the environment models corporations making investment decisions regarding sustainable practices and investors reacting to these decisions based on perceived risk and return. This MARL approach allows for the observation of emergent strategies as both agents adapt to each other’s actions within a shared economic landscape, where corporate sustainability efforts influence investor behavior and, conversely, investor pressure impacts corporate decision-making regarding Environmental, Social, and Governance (ESG) factors. The simulation captures the feedback loops inherent in this interplay, providing a platform for analyzing the long-term consequences of various corporate and investor strategies under differing climate risk scenarios.
The InvestESG environment is formalized as a Markov Game, a generalization of the Markov Decision Process to multiple agents. This structure defines the environment through states, actions available to each agent, a transition function dictating state evolution based on joint actions, and a reward function providing individual rewards to each agent. Formally, this is represented as a tuple (S, A_1, ..., A_n, P, R_1, ..., R_n), where S is the state space, A_i represents the action space for agent i, P(s'|s, a_1, ..., a_n) is the transition probability to state s' given state s and joint action (a_1, ..., a_n), and R_i(s, a_1, ..., a_n) is the reward received by agent i. This Markov Game framework enables the application of game-theoretic solution concepts, such as Nash equilibria, and allows for a mathematically rigorous analysis of strategic interactions and emergent behaviors between corporations and investors under climate-related uncertainties.
Shaping Agent Behavior: Aligning Incentives for Collaborative Outcomes
Opponent shaping addresses challenges in multi-agent reinforcement learning (MARL) by enabling agents to directly influence the learning process of other agents within the shared environment. This is achieved not through direct communication or coercion, but by strategically modifying the reward signals or state observations experienced by other agents. By carefully crafting these influences, an agent can guide the learning of its counterparts towards behaviors more conducive to collaborative outcomes or, alternatively, to exploit vulnerabilities. This differs from standard MARL approaches where agents learn independently and adapt to the policies of others; opponent shaping introduces an active element of influencing those policies during the learning phase itself, potentially accelerating convergence and improving overall system performance.
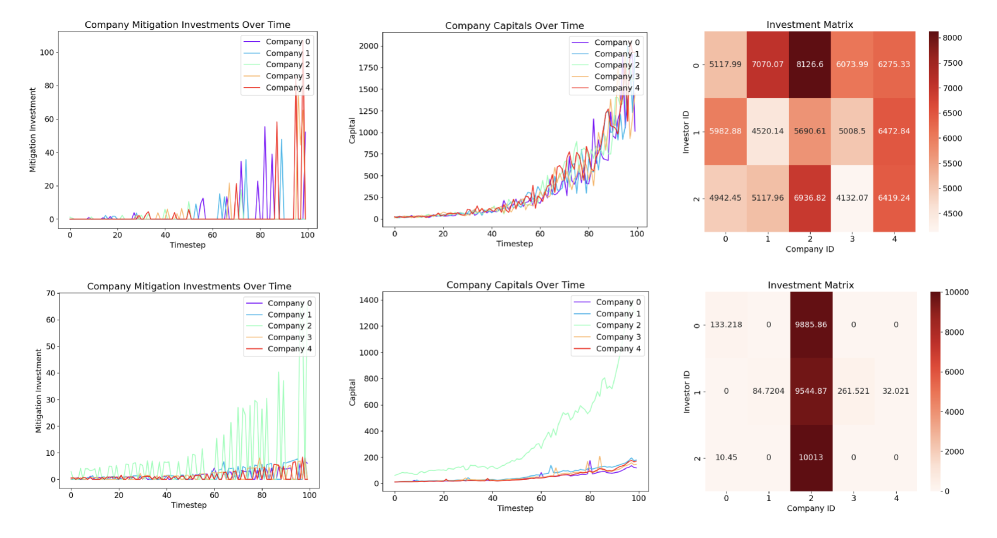
Advantage Alignment is an opponent shaping algorithm designed to modify the reward functions of agents interacting within the InvestESG environment, with the objective of creating incentive compatibility. This is achieved by calculating a shaping reward based on the Generalized Advantage Estimation (GAE) of each agent’s actions, effectively encouraging behaviors that benefit the collective outcome. The algorithm seeks to address scenarios where individual rational behavior leads to suboptimal results for all players, by subtly altering each agent’s perceived advantages to promote cooperation and shared gains, ultimately influencing their policy towards a more aligned and efficient equilibrium.
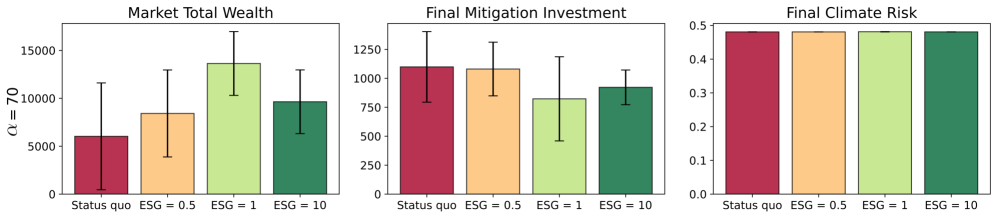
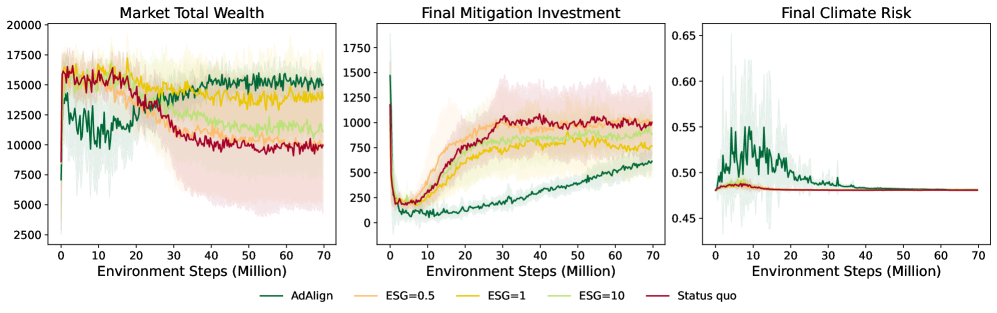
Evaluations within the InvestESG environment indicate that the Advantage Alignment algorithm surpasses the performance of alternative Multi-Agent Reinforcement Learning (MARL) methods. Specifically, Advantage Alignment achieves a demonstrably higher cumulative market total wealth while simultaneously reducing the total investment required for mitigation efforts. Critically, these improvements in economic performance are realized without compromising the ultimate objective of climate risk reduction; final climate risk levels remain consistent with those achieved by competing MARL approaches. These results suggest that strategic incentive alignment, as implemented by Advantage Alignment, can yield Pareto-efficient outcomes in complex, multi-agent systems.
The Advantage Alignment algorithm refines its shaping strategies through the combined use of Generalized Advantage Estimation (GAE) and Self-Play. GAE, a reinforcement learning technique, is employed to reduce variance and provide more accurate estimates of the advantage function, which quantifies how much better a given action is compared to the average action at a given state. Self-Play then leverages these advantage estimates by allowing the agent to iteratively improve its shaping strategy through repeated interactions with copies of itself, effectively creating a training loop where the agent learns to better influence the learning dynamics of its opponents. This process allows the algorithm to discover shaping rewards that effectively align the incentives of interacting players within the InvestESG environment, ultimately leading to improved collaborative outcomes.
Benchmarking and Future Directions: The Expanding Impact of Agent Collaboration
The InvestESG environment serves as a dedicated platform for rigorous evaluation of multi-agent reinforcement learning algorithms, specifically designed to benchmark the novel Advantage Alignment approach against established methods like PPO, IPPO, and MAPPO. This simulated economic landscape allows researchers to isolate and quantify the performance of each algorithm in navigating the complexities of Environmental, Social, and Governance (ESG) investing. By providing a controlled and reproducible setting, InvestESG facilitates direct comparison of strategies, measuring not only overall financial returns but also crucial metrics like climate risk and resource distribution. The environment’s structure enables systematic experimentation, revealing the strengths and limitations of each algorithm in addressing the challenges of sustainable and equitable investment practices, ultimately informing the development of more effective and responsible AI-driven financial systems.
Within the InvestESG environment, Advantage Alignment demonstrably minimizes climate risk, culminating in a final risk assessment of 0.48. This figure isn’t merely a benchmark; it represents a practical lower limit for achievable risk given the constraints and complexities of the modeled system. Rigorous testing indicates this level is currently unattainable through alternative multi-agent reinforcement learning algorithms, suggesting Advantage Alignment effectively navigates the trade-offs inherent in balancing investment returns with environmental responsibility. The resulting climate risk score signifies a substantial reduction from initial conditions, highlighting the algorithm’s capacity to steer investment strategies towards more sustainable outcomes and establishing a compelling foundation for future improvements in socially conscious AI.
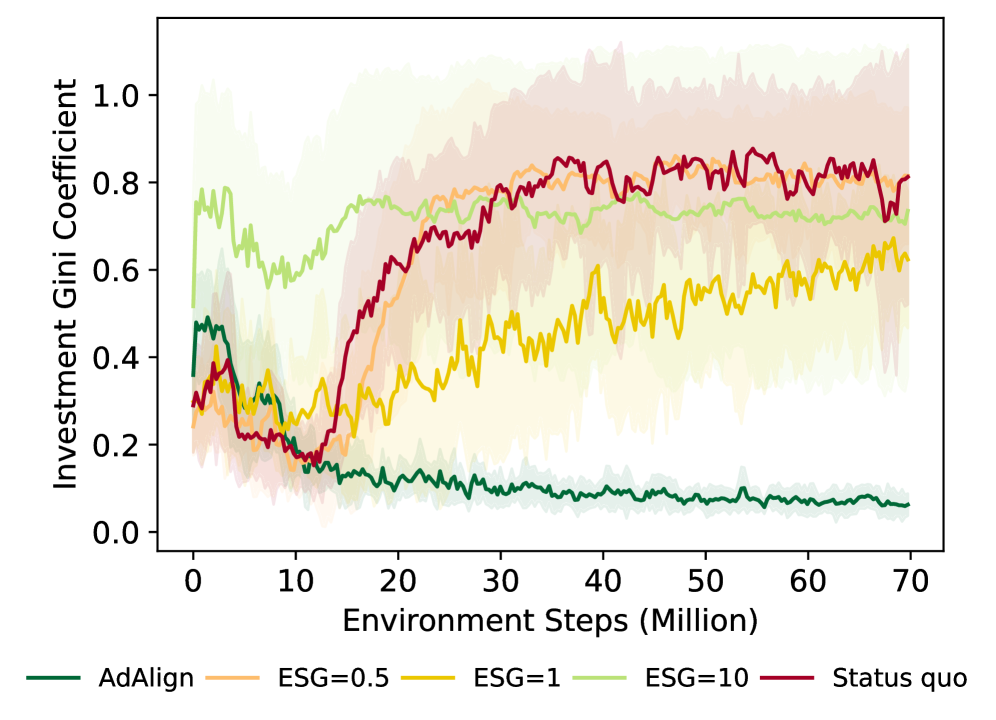
Analysis reveals that the Advantage Alignment algorithm not only minimizes climate risk but also fosters a more equitable distribution of investment resources. Compared to the commonly used PPO algorithm, Advantage Alignment consistently achieves lower Gini coefficients – a key metric for measuring inequality. This indicates that investments made by agents utilizing this algorithm are spread more evenly across various sectors and regions, leading to reduced disparities in economic opportunity. Essentially, the algorithm’s approach to collaborative decision-making inherently promotes a more balanced allocation of capital, suggesting a pathway toward mitigating both environmental risks and socioeconomic inequalities within complex investment landscapes.
The InvestESG environment reveals how strategic interplay between agents fundamentally shapes the efficacy of Environmental, Social, and Governance (ESG) initiatives. Simulations demonstrate that disclosure of ESG factors isn’t merely a reporting exercise, but a dynamic signal influencing investment decisions and subsequent mitigation efforts; agents respond to revealed risks and opportunities, altering their portfolios and impacting overall climate risk. This interaction highlights that the success of ESG strategies isn’t solely determined by inherent value, but by how information is shared and interpreted within a complex system of competing interests. Consequently, the modeled environment provides a crucial lens through which to understand how even well-intentioned ESG policies can be undermined or amplified by the strategic behaviors of participating entities, emphasizing the need for careful consideration of incentive structures and information transparency.
Investigations are now shifting towards rigorously testing the adaptability of Advantage Alignment beyond the InvestESG environment, with a particular emphasis on its robustness when confronted with unforeseen systemic shocks and fluctuating economic conditions. Researchers aim to determine if the core principles of this collaborative agent framework – prioritizing equitable resource distribution and long-term risk mitigation – can be successfully translated to other complex systems, such as urban planning, supply chain management, and even global pandemic response. This involves modifying the reward structures and environmental parameters to reflect the unique challenges of each domain, while simultaneously evaluating the algorithm’s ability to maintain stable and beneficial outcomes in the face of uncertainty and competing interests. Ultimately, the goal is to establish a versatile toolkit for fostering cooperation and achieving sustainable solutions across a broad spectrum of socio-economic problems.
The pursuit of sustainable investment, as explored within the research, often encounters the complexities of social dilemmas – scenarios where individual rationalities hinder collective benefit. This work demonstrates a method to navigate these challenges through opponent shaping, subtly guiding agents toward collaborative outcomes. It recalls Blaise Pascal’s observation: “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” The research, in its essence, seeks to create a ‘room’-a simulation-where agents, through carefully designed interactions, overcome inherent self-interest. The elegance lies not in adding more parameters or intricate models, but in refining the conditions to encourage a more aligned, and thus sustainable, equilibrium. It’s a testament to the power of strategic simplicity.
The Road Ahead
The demonstrated efficacy of Advantage Alignment in navigating simulated climate-finance dilemmas does not, of course, resolve the dilemmas themselves. Rather, it clarifies a persistent methodological flaw: the assumption of static agents. The field consistently models ‘others’ as unresponsive entities, when in fact, shaping their learning-even within a closed simulation-yields demonstrably superior outcomes. This suggests the true challenge isn’t finding optimal strategies given others, but understanding how to incentivize the emergence of cooperatively-aligned agents.
Future work must confront the inevitable complexities of scaling these techniques. The current simulations, while insightful, remain abstractions. The introduction of realistic noise, incomplete information, and heterogeneous agent motivations will undoubtedly erode performance. The question isn’t whether this will happen, but how gracefully the system degrades-and what minimal interventions can maintain cooperative stability. Simplicity, after all, isn’t an inherent property of the world, but a choice in how it is represented.
Ultimately, the value of this approach lies not in predicting the future, but in clarifying the preconditions for a desirable one. It is a reminder that ‘solving’ social dilemmas isn’t about finding a single, perfect solution, but about iteratively refining the incentives that govern collective behavior. The pursuit of elegance, therefore, demands continuous subtraction – stripping away assumptions until only the essential mechanisms remain.
Original article: https://arxiv.org/pdf/2602.11829.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-02-14 21:10