Author: Denis Avetisyan
As natural language processing models become more powerful, reliably identifying inputs that fall outside their training data is crucial for safe and dependable performance.

This review details AP-OOD, an attention-based pooling method for out-of-distribution detection in transformer models, addressing challenges like hallucination and improving sequence representation analysis.
Reliable deployment of machine learning models hinges on accurately identifying inputs that deviate from training data, a challenge exacerbated by the complexity of natural language. This paper introduces ‘AP-OOD: Attention Pooling for Out-of-Distribution Detection’, a novel semi-supervised approach that enhances out-of-distribution (OOD) detection by leveraging token-level information and attention mechanisms within transformer models. Empirically, AP-OOD achieves state-of-the-art results, significantly reducing false positive rates on text summarization and machine translation tasks. Can this refined approach to OOD detection pave the way for more robust and trustworthy generative language models?
The Fragility of “Intelligence”: When Models Stumble
Despite remarkable advances in natural language processing, current models often exhibit a surprising fragility when confronted with text that deviates substantially from the data used during their training. This phenomenon, termed Out-of-Distribution (OOD) detection, highlights a critical limitation: a model proficient at understanding familiar patterns can falter dramatically when presented with novel phrasing, unexpected topics, or stylistic shifts. Essentially, these models excel at interpolation – making predictions within the boundaries of their training data – but struggle with extrapolation to unseen distributions. This vulnerability poses significant challenges for real-world applications, where input data is rarely static and often contains unforeseen variations, demanding robust systems capable of recognizing and appropriately handling unfamiliar inputs to prevent erroneous or unreliable outputs.
The reliance on labeled data presents a significant hurdle for many natural language processing applications attempting to identify out-of-distribution inputs. Conventional supervised learning demands extensive datasets where not only typical inputs are categorized, but also examples of data that fall outside the model’s expected range – effectively requiring the identification and annotation of what the model doesn’t know. Obtaining such labeled OOD examples is often impractical; novel or unexpected data, by definition, hasn’t been seen before, making pre-emptive labeling a costly and often impossible task. Furthermore, the definition of ‘out-of-distribution’ can be subjective and context-dependent, adding to the complexity of creating a reliable labeled dataset. This dependence on labeled OOD data severely restricts the real-world applicability of many otherwise powerful NLP models, motivating the search for alternative, unsupervised approaches.
The limitations of relying on labeled out-of-distribution (OOD) data have driven significant research into unsupervised detection methods. These approaches aim to establish a baseline of ‘normal’ input characteristics during training, allowing the model to flag previously unseen data that deviates significantly from this established norm. Techniques range from utilizing generative models to reconstruct inputs – with poor reconstruction indicating an OOD sample – to employing statistical methods that measure the distance of an input from the training data distribution. The core principle involves identifying anomalies without explicit OOD examples, offering a practical pathway to enhance the robustness and reliability of natural language processing systems in real-world deployments where encountering unforeseen data is inevitable. Such methods promise to improve model safety and prevent potentially harmful or inaccurate outputs when faced with novel or adversarial inputs.
AP-OOD: A Token-Level Approach – Or, How to Look Beyond the Words
AP-OOD employs a Transformer Encoder to process input sequences and generate Token Embeddings, which are vector representations of individual tokens within the sequence. This process leverages the self-attention mechanism inherent in Transformer architectures to capture contextual relationships between tokens, resulting in embeddings that encode nuanced semantic information beyond simple word representations. The Transformer Encoder analyzes each token in relation to all other tokens in the sequence, allowing the model to understand the role of each token within the broader context and produce embeddings that reflect this understanding. These rich Token Embeddings serve as the foundation for subsequent Out-of-Distribution (OOD) detection analysis by providing a detailed and context-aware representation of the input data.
Attention Pooling is employed to create a fixed-size Sequence Representation from the Transformer Encoder’s Token Embeddings. This process involves weighting each token embedding based on its learned importance, determined through an attention mechanism. Specifically, a context vector is generated as a weighted sum of the token embeddings, where the weights are calculated using a trainable query vector and the token embeddings themselves. This aggregation reduces the variable-length input sequence to a single, representative vector, enabling efficient computation of distances and comparisons between inputs, regardless of their original length. The resulting Sequence Representation encapsulates the most salient information from the input sequence in a condensed format.
AP-OOD employs the Mahalanobis distance as a metric to quantify the dissimilarity between a given input sequence representation and the expected distribution of in-distribution data. The Mahalanobis distance, unlike Euclidean distance, accounts for the covariance structure of the data, effectively normalizing for feature correlations and scaling. This is achieved by calculating d^2(x) = (x - \mu)^T \Sigma^{-1} (x - \mu) , where x is the sequence representation, μ is the mean of the in-distribution sequence representations, and Σ is the covariance matrix. Higher Mahalanobis distances indicate greater deviation from the expected distribution, allowing AP-OOD to identify out-of-distribution samples with improved accuracy compared to methods relying on simpler distance metrics.
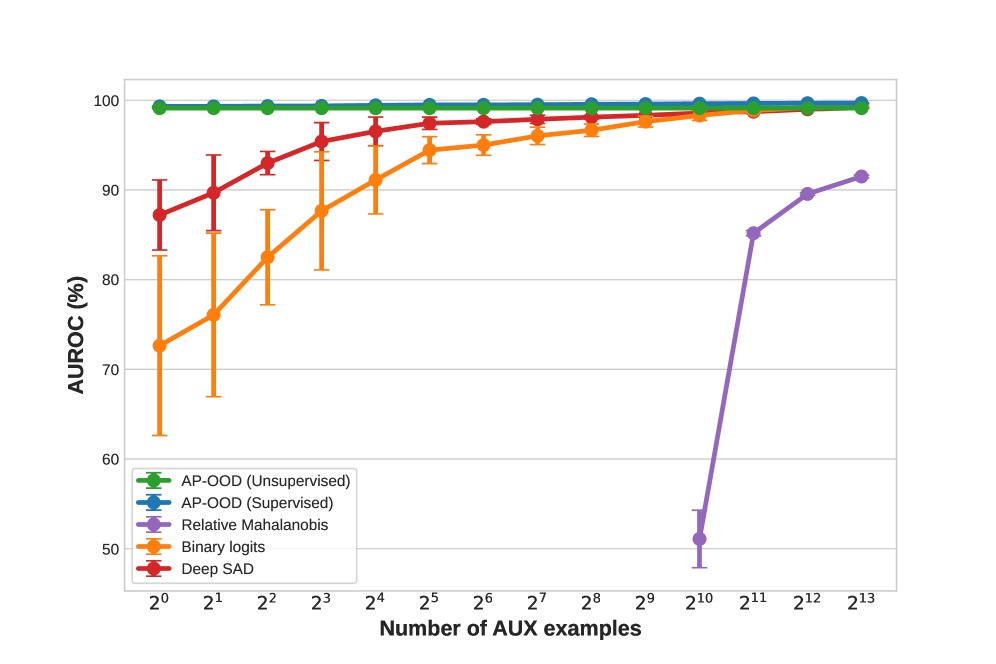
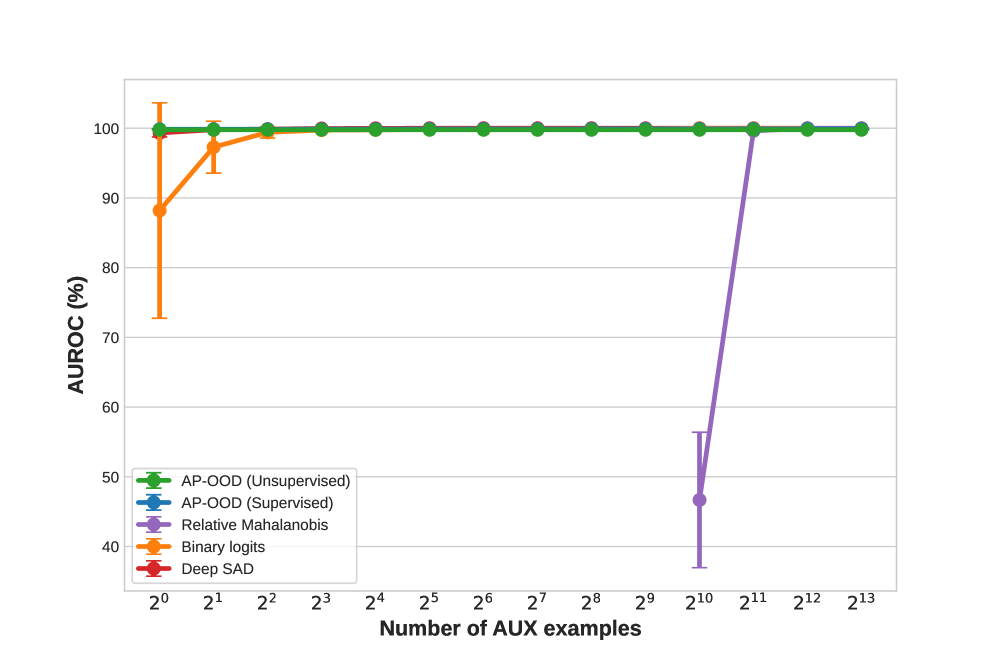
Validating the System: Numbers Don’t Lie (Much)
Evaluation of the AP-OOD model utilized established Out-of-Distribution (OOD) detection metrics, specifically the Area Under the Receiver Operating Characteristic curve (AUROC) and the False Positive Rate at 95% recall (FPR95). AUROC provides a comprehensive measure of the model’s ability to discriminate between in-distribution and OOD samples across various thresholds, while FPR95 quantifies the proportion of in-distribution samples incorrectly flagged as OOD at a fixed 95% true positive rate. Performance was assessed across a range of datasets to ensure generalizability and robustness of the results, providing a comprehensive understanding of the model’s OOD detection capabilities.
Evaluation of the AP-OOD model using standard Out-of-Distribution (OOD) detection metrics yielded an Area Under the Receiver Operating Characteristic curve (AUROC) of 0.99 when tested on the XSUM dataset. Across all OOD datasets utilized in the evaluation, AP-OOD achieved an average AUROC of 0.97, demonstrating consistent performance across varied data distributions. This metric indicates the model’s ability to effectively discriminate between in-distribution and out-of-distribution samples, with higher AUROC values representing improved detection capabilities.
In fully supervised out-of-distribution (OOD) detection, AP-OOD demonstrates a false positive rate (FPR) of 0.11%. This represents a significant performance increase compared to a baseline method utilizing binary logits, which achieved an FPR of 0.97% under the same conditions. The observed reduction in false positives indicates AP-OOD’s improved ability to accurately identify in-distribution samples, minimizing incorrect classifications when evaluating novel or unseen data.
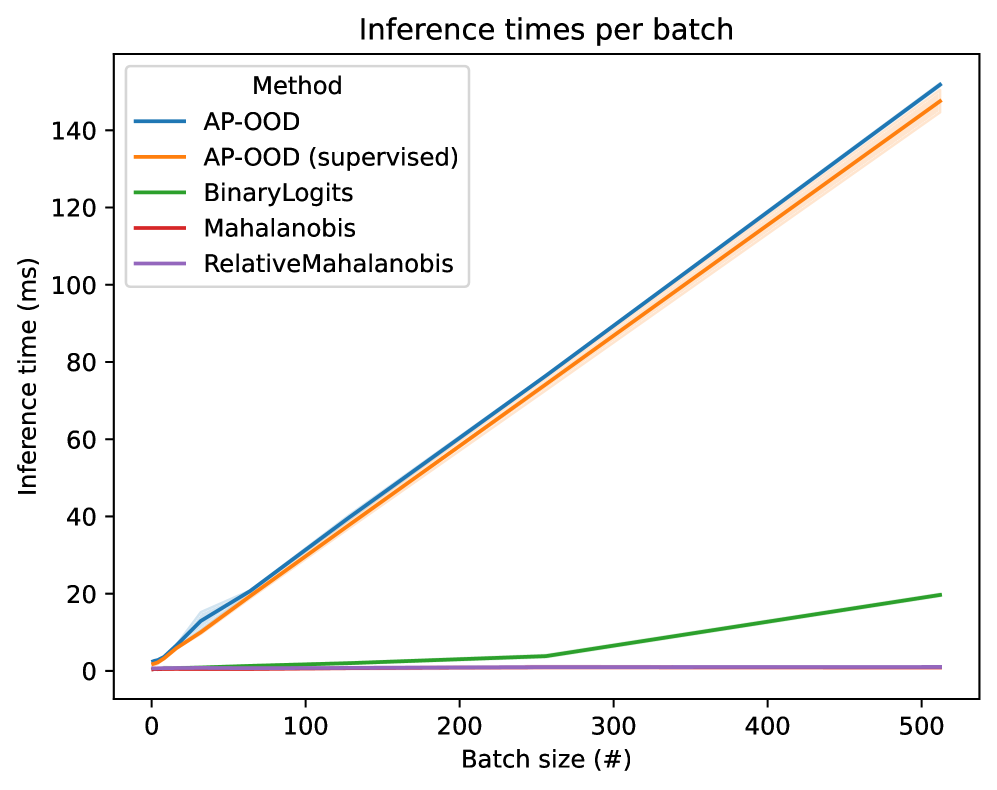
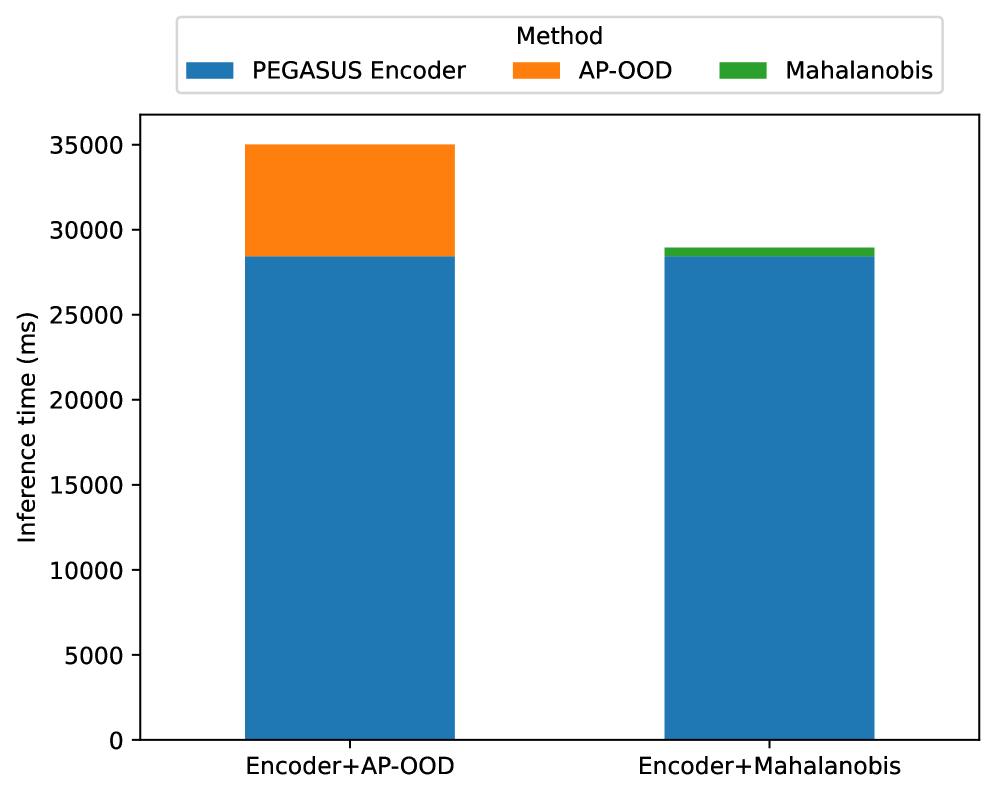
Beyond the Algorithm: Towards Truly Robust Systems
The Adaptive Patch-based Out-of-distribution (AP-OOD) methodology achieves heightened performance through the incorporation of Continuous Modern Hopfield Networks. These networks, unlike their traditional counterparts, operate in a continuous state space, enabling a more nuanced representation of data and facilitating robust pattern recognition even with noisy or incomplete inputs. This integration allows the AP-OOD system to effectively distinguish between familiar, in-distribution data and previously unseen, out-of-distribution examples by leveraging the Hopfield network’s capacity for associative memory and pattern completion. The result is a significantly improved ability to identify anomalies and safeguard against adversarial attacks, bolstering the system’s reliability in real-world applications where data integrity is paramount.
The AP-OOD methodology’s evolution benefited significantly from the application of Large Language Model (LLM) refinement techniques. Beyond simply optimizing existing parameters, these LLMs were strategically employed to explore the solution space, generating entirely new research directions and hypotheses for improving out-of-distribution (OOD) detection. This process moved beyond incremental adjustments, enabling the system to proactively address potential weaknesses and capitalize on emerging patterns in data. The LLMs acted as a dynamic engine for innovation, continuously suggesting modifications to the AP-OOD framework and accelerating its capacity to identify previously unseen anomalies with enhanced accuracy and robustness. This iterative cycle of LLM-driven suggestion and subsequent validation ensures the methodology remains at the forefront of OOD detection capabilities, adapting to increasingly complex data landscapes.
The synergy between advanced pattern recognition and large language model refinement yields a remarkably potent out-of-distribution (OOD) detection system, extending far beyond theoretical capabilities. This technology doesn’t simply identify unusual data; it actively safeguards critical systems by pinpointing anomalies indicative of security breaches, fraudulent activities, or critical failures in complex machinery. Applications span diverse fields, from ensuring the integrity of financial transactions and preventing cyberattacks, to enhancing the reliability of autonomous vehicles and improving medical diagnoses by flagging unusual patient data. The system’s adaptability allows it to learn and evolve with changing data landscapes, offering a proactive defense against unforeseen threats and solidifying its role as a cornerstone of modern data security and anomaly detection.
The pursuit of robust out-of-distribution (OOD) detection, as detailed in this work with AP-OOD, feels perpetually Sisyphean. The system attempts to anticipate every possible failure mode, every unexpected input-a fool’s errand. It’s a meticulous effort to quantify uncertainty in sequence representation, hoping to catch the ‘hallucinations’ of generative models before they wreak havoc. As Carl Friedrich Gauss observed, “Errors use enthusiasm as a disguise.” This rings true; each confidently generated, yet entirely fabricated, response is a testament to the illusion of certainty. The tests, naturally, will not catch them all.
What’s Next?
The pursuit of reliable out-of-distribution (OOD) detection in natural language processing will, predictably, encounter diminishing returns. AP-OOD’s attention-based pooling offers a nuanced approach to identifying anomalous inputs, yet the fundamental challenge remains: defining ‘distribution’ in a field built on generating novel text. The current focus on token-level analysis, while logical, feels reminiscent of earlier attempts at capturing semantic meaning through word embeddings – a problem eventually addressed (though not solved) by contextualized representations. One anticipates a shift toward detecting degrees of anomaly, rather than binary OOD/in-distribution classifications.
The real test will lie not in curated benchmarks, but in the inevitable collision with production systems. Generative models, after all, are remarkably adept at normalizing the unexpected. What appears as OOD today will likely be re-labeled as “creative variance” tomorrow. The next phase will almost certainly involve adversarial attacks specifically designed to bypass attention-based OOD detectors – a cat-and-mouse game with ever-decreasing marginal utility.
Ultimately, the field might benefit from abandoning the quest for a perfect OOD detector altogether. Perhaps a more pragmatic approach involves building models that are robust to OOD inputs, gracefully degrading performance rather than failing catastrophically. If all tests pass, it is because they measure nothing of real-world complexity.
Original article: https://arxiv.org/pdf/2602.06031.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-08 15:19