Author: Denis Avetisyan
A new framework combines image and language analysis, using reinforcement learning to pinpoint subtle forgery traces and provide human-understandable explanations for its decisions.
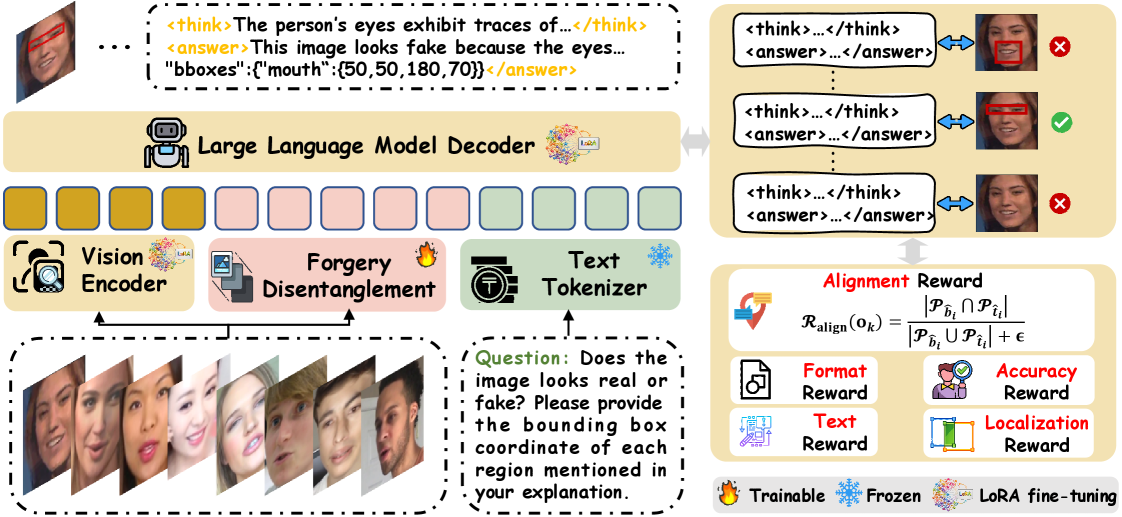
This research introduces MARE, a multimodal alignment and reinforcement learning approach for explainable deepfake detection via vision-language models focusing on forgery disentanglement.
Despite advances in deepfake detection, current methods often lack both the accuracy and interpretability needed to counter increasingly sophisticated forgeries. This paper introduces ‘MARE: Multimodal Alignment and Reinforcement for Explainable Deepfake Detection via Vision-Language Models’, a novel framework that enhances deepfake detection by aligning visual cues with language-based reasoning, guided by reinforcement learning from human feedback. Specifically, MARE improves authenticity assessment and generates spatially-aligned explanations by disentangling forgery traces from facial semantics. Could this approach pave the way for more robust and transparent AI systems capable of discerning reality from increasingly convincing synthetic media?
The Illusion of Truth: Why We’re Losing the War on Deepfakes
The rapid advancement of artificial intelligence has fueled a surge in deepfake technology, creating convincingly realistic but entirely fabricated videos and audio recordings. This proliferation presents a substantial threat to information ecosystems, eroding public trust in media and potentially destabilizing social and political landscapes. Unlike traditional forms of misinformation, deepfakes exploit the inherent human tendency to believe what one sees and hears, making them particularly insidious. The ease with which these manipulations can be created and disseminated-often through social media platforms-amplifies their potential for harm, ranging from reputational damage to the incitement of conflict. Consequently, maintaining the integrity of information and fostering media literacy are now more critical than ever in an age where discerning fact from fiction becomes increasingly challenging.
Conventional forgery detection techniques, historically reliant on identifying obvious alterations to image or video data, are proving increasingly ineffective against the rising tide of sophisticated deepfakes. These methods, designed to spot inconsistencies in pixel arrangements, lighting, or compression artifacts, falter when confronted with manipulations that seamlessly integrate fabricated content with genuine material. The advancements in generative adversarial networks (GANs) and other machine learning algorithms allow for the creation of synthetic media so realistic that they bypass traditional analytical tools, often appearing indistinguishable from authentic sources. This escalating arms race between forgers and detectors demands a shift in focus, moving beyond superficial pixel-level scrutiny to encompass a deeper understanding of the structural and behavioral anomalies inherent in these complex fabrications.
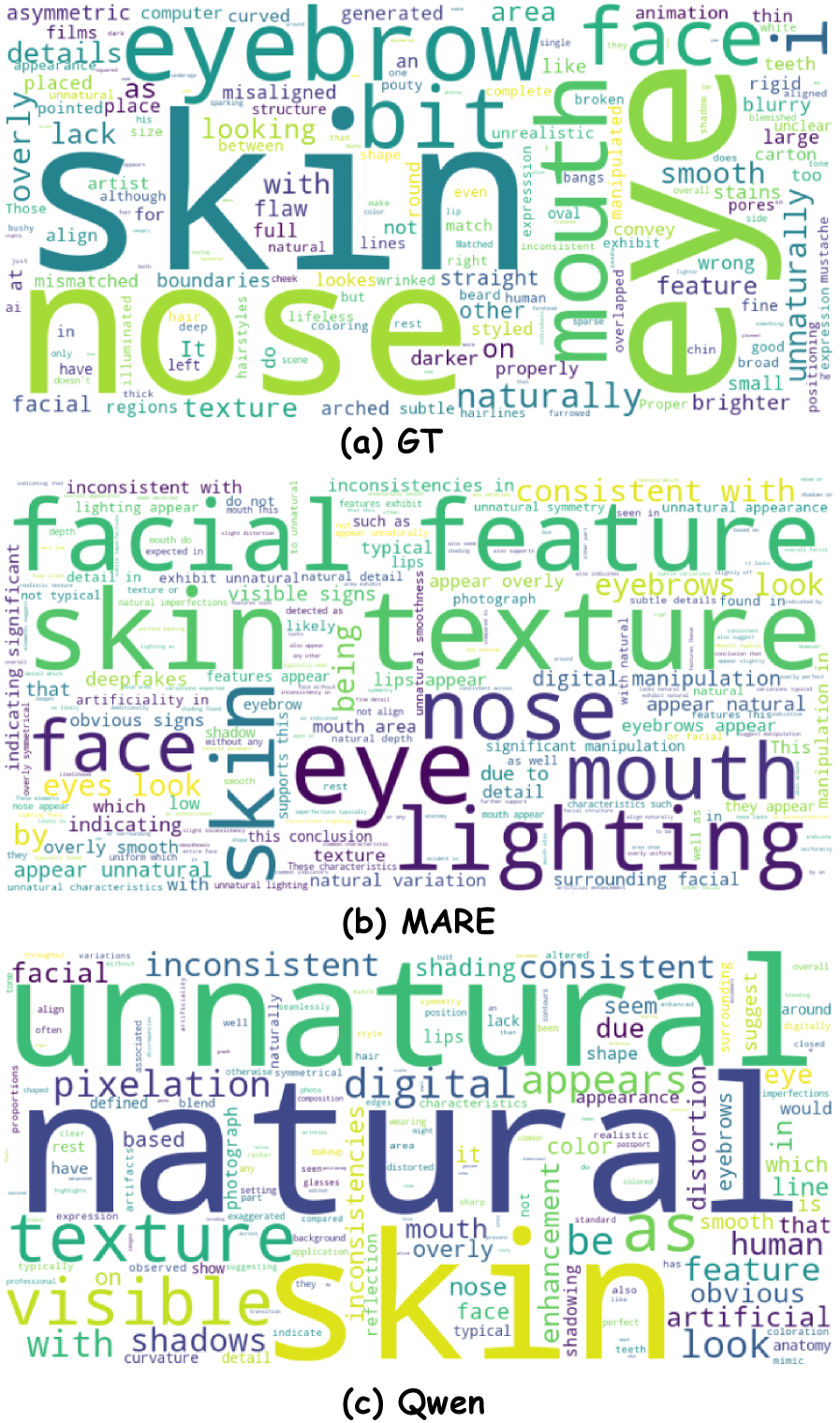
The detection of deepfakes increasingly relies on identifying what are termed ‘forgery traces’ – subtle anomalies introduced during the manipulation process. These aren’t necessarily obvious visual distortions, but rather inconsistencies in physiological signals, blinking patterns, or even the subtle physics of light and shadow that a generative model might not perfectly replicate. Analyzing these traces demands a nuanced approach, moving beyond simple pixel comparisons to encompass a broader understanding of human behavior and realistic rendering. Sophisticated algorithms now attempt to parse these minute details, examining not just what is visible, but how it is presented, looking for deviations from established norms that betray the artificial origin of the content. This necessitates advanced analytical techniques and, crucially, large datasets of authentic examples to establish a reliable baseline for comparison.
Current deepfake detection methods often fixate on pixel-level imperfections, seeking minute visual discrepancies that increasingly sophisticated algorithms can easily evade. However, truly robust identification demands a shift in focus – towards analyzing the structural integrity of the manipulated content. This involves examining inconsistencies in the way the deepfake system has reconstructed faces, bodies, or scenes, looking for anomalies in things like blinking patterns, head poses, or even the physics of how light interacts with surfaces. These underlying structural flaws, often invisible to the naked eye, represent the fundamental limitations of current generative models and offer a more reliable fingerprint for identifying fabricated media, as they are significantly harder to replicate convincingly than superficial visual details.
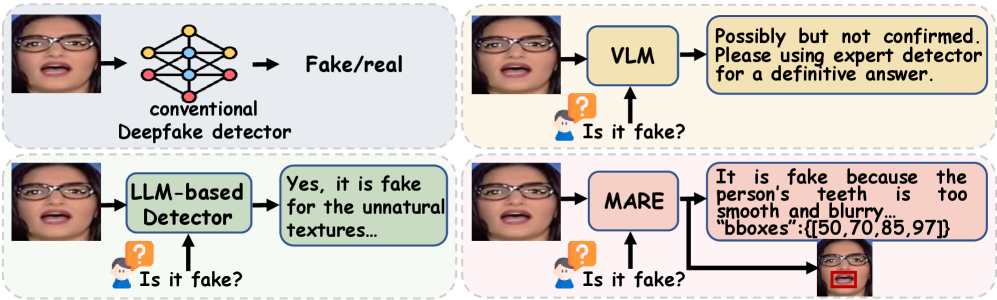
Pinpointing the Lie: Localizing Manipulation with Precision
Accurate spatial localization of forgery traces is fundamental to reliable image forensic analysis because it moves beyond simply identifying that manipulation occurred to pinpointing where it occurred within the image. This precise localization enables detailed examination of the manipulated regions, allowing for assessment of the forgery method and potential inconsistencies. Without accurate spatial information, it is difficult to differentiate between naturally occurring image features and those introduced by malicious alteration. Consequently, reliable detection necessitates algorithms capable of identifying and delineating the precise boundaries of any forged or altered content within the image data, providing crucial evidence for authentication or attribution.
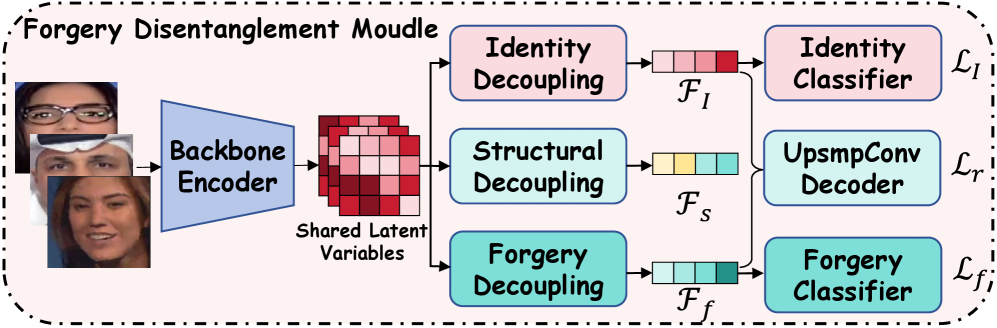
The Forgery Disentanglement Module (FDM) operates by decomposing an input image into three distinct feature sets: identity, structural, and forgery-related. Identity features represent characteristics intrinsic to the subject of the image, such as facial attributes. Structural features encapsulate the inherent composition of the scene, including lighting and background elements. Critically, the FDM isolates forgery-related features, which specifically denote traces of manipulation, such as inconsistencies in lighting, blending artifacts, or altered textures. This separation is achieved through a combination of convolutional neural networks and specifically designed loss functions that encourage the disentanglement of these feature sets, allowing for focused analysis of the manipulated regions and techniques.
Face Landmark Detection contributes to spatial localization by identifying and mapping key facial features – such as the corners of the eyes, the tip of the nose, and the edges of the mouth – within an image. The output of this detection is a set of coordinate pairs defining bounding boxes around these landmarks. These bounding boxes provide precise spatial information, enabling the system to pinpoint the location of potential forgery traces relative to known facial features. This localized data is then used to assess the consistency of the image and identify anomalies indicative of manipulation, improving the accuracy of forgery detection beyond global image analysis.
Traditional image forgery detection often limits analysis to a binary classification – determining whether manipulation has occurred, but not how. Isolating and analyzing specific forgery traces, however, enables a more granular understanding of the manipulation process. This detailed analysis moves beyond a simple “forged” or “authentic” determination to identify the specific techniques employed, such as copy-move, splicing, or retouching. By discerning these techniques, systems can provide evidence supporting the nature of the forgery, aiding in forensic investigations and establishing the credibility of digital evidence. This capability is crucial for applications requiring a detailed audit trail of image alterations.
MARE: Aligning Perception with Reality to Combat Deepfakes
The MARE framework improves the accuracy of Visual Language Models (VLMs) for deepfake detection by combining visual feature analysis with textual reasoning. This integration allows the model to not only identify anomalies in visual data but also to justify its conclusions based on learned relationships between image characteristics and textual descriptions of manipulation artifacts. Evaluations demonstrate that MARE achieves state-of-the-art performance on established deepfake detection benchmarks, exceeding the accuracy of existing single-modality and less integrated multimodal approaches. The framework’s performance is attributed to its ability to leverage complementary information from both visual and textual inputs, resulting in more robust and reliable detection capabilities.
Multimodal Alignment within the MARE framework establishes a correspondence between visual features extracted from a video or image and textual explanations generated to justify a deepfake determination. This process involves projecting both modalities into a shared embedding space, enabling the model to assess the consistency between what is seen and what is explained. By explicitly linking visual evidence to textual reasoning, the framework reduces reliance on spurious correlations and enhances the robustness of deepfake detection, particularly in scenarios involving adversarial examples or subtle manipulations. The alignment process is implemented through contrastive learning, maximizing the similarity between aligned visual and textual features while minimizing the similarity between misaligned pairs.
The Deepfake Multimodal Alignment (DMA) dataset serves as the primary resource for training and validating the MARE framework’s reasoning abilities. This dataset, specifically constructed to evaluate multimodal alignment in deepfake detection, comprises images and corresponding textual explanations designed to challenge the framework’s capacity to correlate visual cues with linguistic justifications. Quantitative results demonstrate that the MARE framework achieves state-of-the-art accuracy on the DMA dataset, exceeding the performance of previously published methods and establishing a new benchmark for deepfake detection systems reliant on multimodal reasoning.
The MARE framework incorporates textual reasoning to provide explanations for deepfake detection decisions, increasing both trust and transparency in the process. This is achieved by generating textual justifications alongside the detection result, detailing the specific visual features that contributed to the determination. Empirical results demonstrate that this approach outperforms existing methods on both the WildDeepfake (WDF) and DeepFake Detection Challenge (DFDC) datasets, indicating a quantifiable improvement in detection accuracy alongside enhanced explainability. The generated textual reasoning allows for verification of the model’s logic and facilitates a more nuanced understanding of the deepfake characteristics identified.

The Human Factor: Reinforcing Reasoning with Feedback and Reward
Human feedback annotation serves as a crucial component in bolstering a VLM’s ability to reason effectively. This process involves humans evaluating the model’s responses – not simply for correctness, but for the quality of its reasoning process – and providing nuanced feedback on where improvements are needed. This data, gathered through careful human assessment, is then used to refine the model’s internal algorithms, allowing it to better discern subtle cues, avoid logical fallacies, and ultimately, generate more reliable and coherent explanations. The iterative cycle of model response, human evaluation, and algorithmic adjustment enables a VLM to move beyond pattern recognition towards genuine understanding, significantly enhancing its capacity to tackle complex challenges and provide insightful analyses.
Reward functions serve as the core mechanism for guiding a Visual and Language Model (VLM) toward proficient deepfake detection. These functions don’t simply acknowledge correct answers; they assign numerical values based on the quality of the reasoning process. A VLM might receive a high reward not only for accurately identifying a manipulated image, but also for providing a clear, concise explanation detailing why it reached that conclusion. This incentivizes the development of coherent and justifiable outputs, moving beyond superficial pattern recognition. By precisely defining desired behaviors – such as flagging subtle inconsistencies or prioritizing explanations over simple binary classifications – researchers can shape the VLM’s learning trajectory, fostering a system that’s both accurate and transparent in its assessments.
The convergence of human discernment and reinforcement learning offers a pathway to perpetually enhance a system’s performance. Rather than relying on static datasets, this approach allows the model to learn from ongoing feedback, effectively refining its reasoning abilities with each interaction. Human insight guides the reward functions, shaping the model’s behavior to prioritize not only accuracy but also the clarity and coherence of its explanations. This iterative cycle – where the model acts, receives human evaluation, and adjusts its strategy – fosters a dynamic learning process. Consequently, the system doesn’t simply reach a performance plateau; instead, it continually adapts and improves, becoming increasingly robust and capable of addressing complex challenges as they emerge.
The ongoing battle against deepfakes demands a dynamic defense, and iterative refinement through human feedback and reinforcement learning offers a path toward greater resilience. Each cycle of annotation and reward function adjustment doesn’t simply address existing vulnerabilities; it proactively prepares the system to recognize novel manipulation techniques. This continuous improvement is crucial because deepfake technology itself is constantly evolving, becoming increasingly sophisticated and difficult to detect. By repeatedly exposing the system to new examples and reinforcing accurate assessments, researchers are building a defense that doesn’t rely on static signatures, but rather on a robust understanding of what constitutes authentic content – a crucial distinction for maintaining trust in a visually saturated world. This adaptive approach promises a more trustworthy system capable of withstanding the ever-changing landscape of synthetic media.
The pursuit of ever-more-sophisticated deepfake detection, as exemplified by MARE and its multimodal alignment, feels… predictably ambitious. It’s a beautifully complex system built to identify forgery traces, yet one suspects production environments will inevitably find new, equally subtle ways to defeat it. It’s the cycle of life, really. As Fei-Fei Li once said, ‘AI is not about making machines smarter, it’s about making us smarter.’ This framework attempts to make machines smarter at spotting deception, but it’s the human ingenuity in creating that deception that will always present the true challenge. One imagines future archaeologists will sift through the ruins of defeated detection algorithms, much like the forgery traces MARE attempts to isolate. If it crashes consistently, at least it’s predictable.
What’s Next?
The pursuit of robust deepfake detection, as exemplified by frameworks like MARE, inevitably leads to a familiar optimization cycle. Current approaches meticulously dissect forgery traces, aligning visual and linguistic reasoning. Yet, this alignment itself becomes a target for adversarial attacks – the subtle distortions that will inevitably render even spatially-precise explanations unreliable. Architecture isn’t a diagram; it’s a compromise that survived deployment, and survival is rarely permanent.
The emphasis on explainability, while laudable, introduces another layer of complexity. Reasoning content, no matter how spatially aligned, is still an interpretation. The field will likely shift from seeking ‘true’ explanations to quantifying confidence in those explanations, acknowledging that even the most coherent narrative can be constructed atop fabricated foundations. Everything optimized will one day be optimized back, a constant recalibration against increasingly sophisticated forgeries.
Ultimately, the true challenge isn’t just detecting the fake, but understanding why someone created it. The technical problem will yield, as all technical problems eventually do, but the underlying motivations remain a far more intractable – and perhaps more important – area of inquiry. It isn’t about building better detectors; it’s about resuscitating hope that truth still matters.
Original article: https://arxiv.org/pdf/2601.20433.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Top 20 Dinosaur Movies, Ranked
- Silver Rate Forecast
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Games That Faced Bans in Countries Over Political Themes
2026-01-30 00:47