Author: Denis Avetisyan
Researchers have developed a novel architecture and large-scale dataset to more reliably detect increasingly sophisticated AI-generated video content.
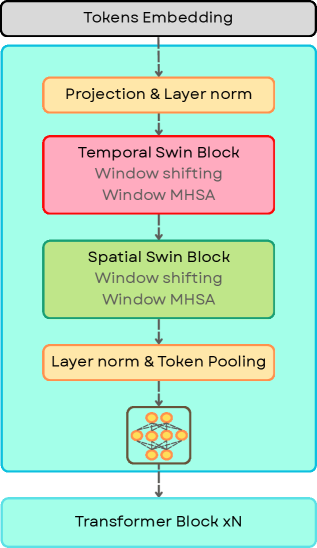
The EA-Swin model, a spatiotemporal transformer, combined with the EA-Video dataset, significantly improves the accuracy of AI-generated video detection.
The increasing realism of AI-generated videos presents a significant challenge to existing detection methods, which often rely on superficial cues or computationally expensive models. To address this, we introduce EA-Swin: An Embedding-Agnostic Swin Transformer, a novel architecture designed to model spatiotemporal dependencies directly on pretrained video embeddings. Our approach, coupled with the large-scale EA-Video dataset-comprising 130K videos and rigorous cross-distribution splits-achieves state-of-the-art accuracy (0.97-0.99) across major generators, surpassing prior methods by 5-20%. As synthetic video generation continues to advance, can these scalable and robust techniques effectively safeguard against increasingly sophisticated forgeries?
Decoding the Synthetic: Challenges to Visual Trust
The accelerating progress in generative artificial intelligence is fundamentally reshaping the landscape of visual media, producing videos of such fidelity that discerning authenticity from fabrication becomes increasingly difficult. These advanced models, leveraging techniques like generative adversarial networks and diffusion models, can now synthesize photorealistic scenes, mimic human expressions, and even convincingly replicate individual speaking styles. Consequently, the distinction between captured reality and algorithmically-created content is eroding, presenting substantial challenges to established norms of visual trust and creating opportunities for the undetectable manipulation of information. This technological leap necessitates a reevaluation of how authenticity is verified and a proactive approach to mitigate the potential for misuse, as increasingly convincing synthetic media threatens to undermine confidence in all forms of video evidence.
The escalating creation of AI-generated content, prominently featuring deepfakes, presents a significant challenge to information integrity and societal trust. As these synthetic media become increasingly convincing and readily available, the potential for misinformation, reputational damage, and even political manipulation grows exponentially. Consequently, the development of robust detection methods is no longer merely a technical pursuit, but a crucial safeguard against malicious use. These methods must move beyond simple artifact detection and incorporate techniques capable of analyzing subtle inconsistencies in physiological signals, semantic coherence, and contextual plausibility to effectively distinguish authentic content from increasingly sophisticated forgeries. Failure to do so risks eroding public confidence in visual media and creating an environment where discerning truth from fabrication becomes virtually impossible.
Traditional video forensics, reliant on detecting inconsistencies in compression artifacts, lighting, or biological signals, are increasingly challenged by the fidelity of contemporary generative models. These advanced algorithms can now synthesize content that convincingly mimics real-world recordings, effectively masking the telltale signs previously used for detection. Consequently, current techniques – including those focused on facial action unit analysis or subtle physiological cues – demonstrate diminished effectiveness against increasingly realistic deepfakes and AI-generated videos. This necessitates a shift towards innovative approaches, such as examining the underlying ‘fingerprints’ of generative networks, analyzing inconsistencies in the physics of simulated scenes, or leveraging advanced machine learning models trained to identify subtle, imperceptible anomalies indicative of synthetic origin, all in an effort to preserve trust in visual media as a reliable source of information.

Spatiotemporal Dynamics: A Holistic Approach to Verification
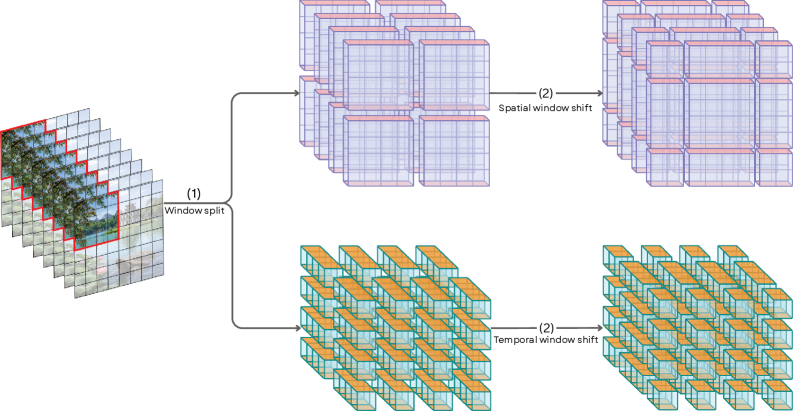
Accurate detection of AI-generated videos necessitates models that process video content by considering both spatial information – the details within each individual frame – and temporal dynamics – how these details change over time. Traditional image-based analysis is insufficient, as it disregards the crucial motion and sequential relationships inherent in video. Models must therefore be capable of identifying subtle inconsistencies or artifacts that manifest across frames, such as unnatural movements, flickering, or discontinuities, in addition to analyzing the content of each frame independently. This requires architectures designed to explicitly capture and reason about the temporal dependencies within video sequences, allowing for a more holistic and robust understanding of the content and its potential origin.
The EA-Swin architecture employs spatiotemporal modeling through a hierarchical vision transformer that integrates both spatial and temporal attention mechanisms. Specifically, it utilizes windowed multi-head self-attention (W-MSA) to divide each frame into non-overlapping windows, reducing computational complexity while capturing intra-frame relationships. Furthermore, shifted window partitioning is implemented to enable cross-window connections. Factorized attention decomposes the attention computation into spatial and temporal streams, allowing for parallel processing and improved efficiency in handling video sequences. This factorization effectively reduces the quadratic computational cost associated with traditional self-attention, scaling more favorably with video length and resolution.
The EA-Swin architecture incorporates the V-JEPA2 encoder, which undergoes pre-training via self-supervised learning to enhance its feature extraction capabilities. This pre-training process allows the encoder to learn robust representations from unlabeled video data, improving generalization performance on downstream tasks. Specifically, the V-JEPA2 encoder learns to predict future video frames given past frames, forcing it to capture essential spatiotemporal information. By leveraging these pre-trained features, EA-Swin achieves state-of-the-art results in AI-generated video detection, demonstrating improved accuracy and efficiency compared to models trained from scratch or utilizing different encoder architectures.
Scaling Trust: Large Datasets and Self-Supervision
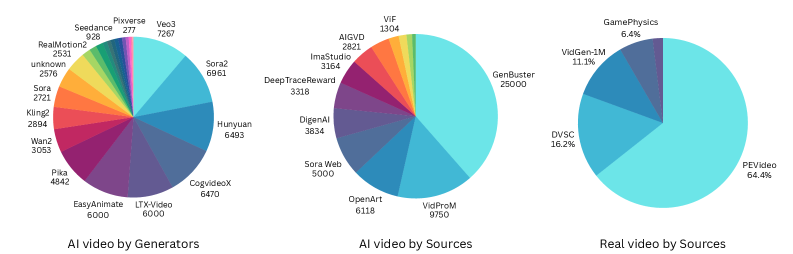
The efficacy of AI-generated video detection is directly correlated with the scale and diversity of the training datasets utilized; insufficient or homogenous data leads to reduced generalization and accuracy. The EA-Video Dataset addresses this need by providing a large-scale resource specifically designed for this purpose, comprising a substantial number of AI-generated and real videos sourced from diverse generators and capture conditions. This extensive collection facilitates the training of more robust and reliable detection models, enabling them to better distinguish between authentic and synthetic content across a wider range of scenarios and generative techniques, as evidenced by models trained on this dataset achieving high performance metrics on both seen and unseen generators.
Self-supervised learning (SSL) addresses the limitations of labeled datasets by enabling models to learn representations directly from unlabeled video data. Techniques such as DINOv2 and DINOv3 utilize pretext tasks – artificially created learning problems – to train models to understand visual features without human annotation. These methods typically involve predicting transformations applied to input video frames or contrasting different views of the same scene. The resulting pre-trained models develop robust visual features that can then be fine-tuned with significantly less labeled data for downstream tasks like AI-generated video detection, improving performance and reducing the reliance on expensive and time-consuming manual labeling processes.
The EA-Swin model establishes a new state-of-the-art performance level in AI-generated video detection, achieving 98.66% accuracy on videos from generators included in the training data and 97.4% accuracy on videos from previously unseen generators. This indicates strong generalization capability beyond the training set. Further performance metrics include an Area Under the Curve (AUC) of 0.9991 for seen generators and 0.997 for unseen generators, alongside a consistent F1-score, precision, and recall of 98.66% when evaluated on videos generated by known sources.
Navigating a Synthetic Future: Implications for Visual Truth
The landscape of visual media is undergoing a profound shift, driven by the emergence of text-to-video models such as Sora2 and Veo3. These systems represent a significant leap forward in artificial intelligence, possessing the capability to generate remarkably realistic and coherent videos from textual descriptions. Unlike earlier iterations that often produced short, fragmented clips, these new models create extended narratives with consistent characters, plausible physics, and intricate details. This newfound fidelity extends beyond simple scene creation; the models can now convincingly simulate diverse camera angles, lighting conditions, and artistic styles. Consequently, distinguishing between authentic footage and AI-generated content is becoming increasingly difficult, presenting unprecedented challenges for verification and authentication systems, and potentially eroding trust in visual information altogether.
The escalating realism of AI-generated videos demands a parallel evolution in detection methodologies, specifically through advancements in spatiotemporal modeling and self-supervised learning. Traditional forgery detection often focuses on individual frames, but convincingly fake videos manipulate the flow of time and motion; therefore, algorithms must analyze how visual elements change across sequences, identifying inconsistencies in physics, object interactions, and subtle temporal anomalies. Self-supervised learning offers a promising pathway, enabling models to learn robust feature representations from vast quantities of unlabeled video data – essentially, teaching the system to recognize ‘natural’ video characteristics by observing them repeatedly, and then flagging deviations as potentially synthetic. This approach sidesteps the limitations of relying solely on labeled datasets of known fakes, allowing detectors to generalize to novel and increasingly sophisticated manipulations as generative models continue to improve.
The proliferation of convincingly realistic, AI-generated videos poses a significant threat to the integrity of visual information, necessitating robust detection methods. Without reliable tools to distinguish between authentic and synthetic content, public trust in videos – historically considered strong evidence – erodes rapidly. This vulnerability extends beyond simple deception; manipulated videos can be weaponized to spread disinformation, incite social unrest, damage reputations, and even influence political outcomes. Consequently, advancements in AI-generated video detection aren’t merely a technological pursuit, but a critical safeguard for maintaining informed public discourse and protecting against the escalating risks of manipulation in the digital age. The ability to verify the provenance of video content is becoming increasingly vital for responsible media consumption and a functioning democracy.
The pursuit of reliable AI-generated video detection, as demonstrated by EA-Swin, necessitates a careful examination of spatiotemporal patterns within video data. This approach echoes Yann LeCun’s sentiment: “Everything we do in AI is about pattern recognition.” EA-Swin’s architecture specifically aims to identify the subtle anomalies introduced during the generation process, effectively discerning synthetic content from authentic footage. The paper’s emphasis on a large-scale dataset, EA-Video, underscores the importance of providing robust training data to avoid spurious patterns and enhance the model’s generalization capability. Thorough data validation and boundary checks are crucial for building trustworthy detection systems, allowing the model to focus on genuine indicators of manipulation.
Where Do We Go From Here?
The introduction of EA-Swin and the EA-Video dataset represent a focused advance, yet the very nature of generative adversarial networks suggests this is a perpetually receding horizon. Improved detection, ironically, fuels more sophisticated forgery – a predictable escalation. The architecture’s reliance on spatiotemporal features, while demonstrably effective, begs the question of whether these represent intrinsic signatures of AI generation or simply current artifacts of the algorithms used. Future work must disentangle these properties; a detector fooled by a new generative method is, ultimately, a detector that never existed.
Furthermore, the dataset, while large, remains a snapshot in time. Generative AI evolves at a rate that renders static datasets obsolete with alarming speed. A truly robust system requires continual learning and adaptation, ideally with mechanisms to identify and incorporate new forgery techniques automatically. The current emphasis on feature extraction may also be a limitation; perhaps the key lies not in what is generated, but in the subtle statistical anomalies in the process of generation.
Ultimately, the pursuit of perfect detection is a Sisyphean task. The value lies in understanding the underlying patterns – the telltale signs, however fleeting. If a pattern cannot be reproduced or explained, it doesn’t exist.
Original article: https://arxiv.org/pdf/2602.17260.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Top 20 Dinosaur Movies, Ranked
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Gold Rate Forecast
- The Best Directors of 2025
2026-02-20 20:17