Author: Denis Avetisyan
Researchers have developed a novel framework that combines generative modeling and ensemble learning to accurately identify unusual patterns in complex financial data.

This paper introduces ReGEN-TAD, an interpretable framework for robust anomaly detection and economic insight in high-dimensional financial time series.
Detecting subtle yet impactful anomalies in high-dimensional financial time series remains a persistent challenge due to inherent temporal dependencies and evolving market structures. This paper introduces ‘An Interpretable Generative Framework for Anomaly Detection in High-Dimensional Financial Time Series’, proposing ReGEN-TAD, a novel approach that integrates generative modeling with econometric diagnostics to overcome these limitations. By combining forecasting, reconstruction, and robust calibration within a refined convolutional-transformer architecture, ReGEN-TAD delivers both accurate anomaly detection and economically coherent factor-level attribution. Can this interpretable framework ultimately provide a more nuanced understanding of systemic risk and enable proactive financial management?
Decoding the Noise: The Challenge of Financial Signals
Financial econometrics, historically reliant on techniques like regression and time series analysis, now faces significant hurdles due to the sheer scale and interconnectedness of modern financial data. The proliferation of assets, trading venues, and data sources has created extraordinarily high-dimensional datasets where identifying meaningful signals becomes increasingly difficult. Furthermore, financial time series rarely adhere to the simplifying assumptions – such as linearity or independence – underpinning many traditional statistical models. Relationships between assets are often complex, nonlinear, and time-varying, driven by factors like market sentiment, geopolitical events, and intricate feedback loops. Consequently, methods designed for simpler datasets frequently exhibit reduced accuracy and predictive power when applied to these intricate financial systems, necessitating the development of more robust and adaptable analytical tools.
Initial approaches to identifying unusual events in financial markets frequently depended on the premise of normally distributed data – a bell curve representing predictable fluctuations. However, financial time series rarely adhere to this ideal, particularly during periods of heightened volatility or market stress. These early techniques, such as those based on simple moving averages or linear regressions, struggle when faced with non-Gaussian characteristics like skewness or kurtosis – meaning extreme events occur far more frequently than predicted by a normal distribution. Consequently, anomalies are often misidentified as routine fluctuations, or, conversely, normal price movements are flagged as suspicious, leading to inaccurate risk assessments and potentially flawed trading strategies. The inherent limitations of these distribution-based methods spurred the development of more robust, non-parametric techniques capable of handling the complexities of real-world financial data.
The proliferation of high-frequency trading and the digitization of global markets have resulted in financial time series data growing not only in volume, but also in velocity – the speed at which data points arrive. This exponential increase presents a significant challenge to traditional anomaly detection methods, which often struggle to process and analyze such vast streams of information in real-time. Consequently, research is shifting towards sophisticated, scalable frameworks leveraging techniques like distributed computing and machine learning algorithms capable of handling the computational burden. These advanced systems aim to identify unusual patterns and potential risks within the data flow before they manifest as significant market events, requiring architectures designed for parallel processing and continuous model adaptation to maintain accuracy and responsiveness in dynamic conditions. The demand for these frameworks isn’t merely about processing speed; it’s about building resilient systems capable of proactively mitigating financial instability in an increasingly interconnected and fast-paced world.

Modeling the Unseen: Generative Approaches to Financial Data
Generative modeling techniques provide a means of representing the probabilistic relationships present in multivariate financial time series data, which often exhibit complex, non-linear dependencies. Traditional statistical methods frequently rely on linear approximations or simplifying assumptions about data distributions; however, generative models-such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs)-can directly learn these intricate relationships without requiring explicit feature engineering or distributional assumptions. These models accomplish this by learning a latent representation of the data, effectively capturing the underlying factors that drive the observed financial variables and their interdependencies over time. The ability to model these non-linear dependencies is crucial for accurately representing the dynamic behavior of financial markets and improving the performance of downstream tasks like forecasting and anomaly detection.
Generative models achieve accurate reconstruction of normal financial behavior by learning the probabilistic relationships present within multivariate time series data. This involves capturing both temporal dependencies – how a variable evolves over time – and cross-sectional structure – the statistical relationships between multiple variables at a given point in time. Techniques like Variational Autoencoders (VAEs) or Generative Adversarial Networks (GANs) are employed to model the joint probability distribution of the data, p(x_1, x_2, ..., x_n, t), where x_i represents a financial variable and t denotes time. Successful modeling allows the generative model to produce synthetic data that statistically mimics the observed ‘normal’ patterns, and deviations from this reconstructed behavior can then be flagged as potential anomalies.
Anomaly detection using generative models relies on the principle that a well-trained model will accurately reconstruct typical data patterns. The reconstruction error, quantified as the difference between the original data and the model’s output, serves as the anomaly score. High reconstruction errors indicate data points that deviate significantly from the patterns learned during training, flagging them as potential anomalies. This approach differs from statistical methods requiring predefined thresholds; instead, anomalies are identified relative to the model’s internal representation of normality, making it adaptable to complex, non-linear financial time series where explicit thresholding is impractical. The magnitude of the reconstruction error is thus directly proportional to the degree of anomalous behavior, enabling a ranked list of potential outliers.

Deconstructing Complexity: ReGEN-TAD’s Hybrid Architecture
ReGEN-TAD employs a hybrid neural network architecture integrating Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformer networks to capitalize on their respective strengths in financial time-series analysis. CNNs are utilized for initial feature extraction, identifying localized patterns within the data. These extracted features are then processed by RNNs, specifically designed to model sequential data and capture short-term temporal dependencies. Finally, a Transformer network, incorporating the Attention Mechanism, analyzes the RNN outputs to capture long-range dependencies and contextual relationships crucial for understanding complex financial patterns. This layered approach allows ReGEN-TAD to effectively combine local pattern recognition with both short and long-term temporal modeling capabilities.
The Transformer architecture addresses limitations in traditional recurrent neural networks by employing the Attention Mechanism, enabling the model to weigh the importance of different input features when processing sequential data. Unlike RNNs which process data sequentially, Transformers can process the entire input sequence in parallel, significantly reducing training time and allowing for the capture of long-range dependencies – relationships between data points separated by many time steps – that are critical for identifying complex patterns in financial time series. The Attention Mechanism calculates a weighted sum of all input features, where the weights represent the relevance of each feature to the current prediction, effectively allowing the model to “focus” on the most important information regardless of its position in the sequence. This capability is particularly valuable in financial analysis where events occurring far in the past can significantly impact current market behavior.
Reconstruction-based anomaly detection, implemented via an autoencoder within ReGEN-TAD, operates by training the network to compress and then reconstruct input data. The difference between the original input and the reconstructed output is quantified as Reconstruction Error. Higher Reconstruction Error values indicate that the input deviates significantly from patterns learned during training, signaling a potential anomaly. This error metric provides a numerical score representing the degree of unusualness, allowing for threshold-based identification of anomalous data points without requiring pre-labeled anomaly examples. The autoencoder effectively learns a compressed representation of normal behavior, making it sensitive to deviations indicative of irregular patterns.
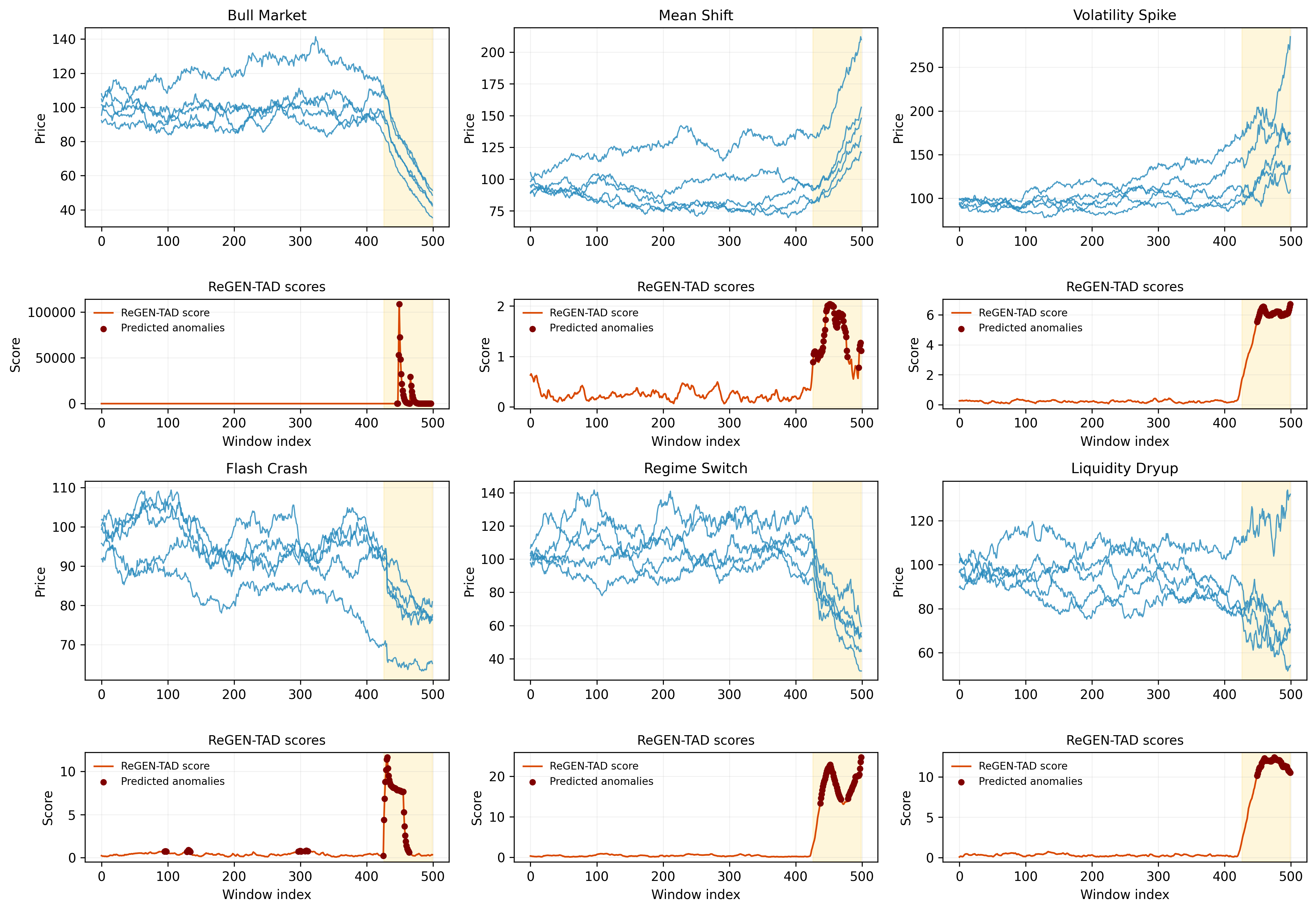
ReGEN-TAD’s performance was evaluated using the F1-Score, a metric representing the harmonic mean of precision and recall, across a diverse dataset comprising both synthetically generated and real-world financial time series. The model achieved an average F1-Score of 0.7717, indicating a balanced ability to correctly identify both anomalous and normal behaviors within the data. This score was calculated by averaging the F1-Scores obtained from multiple experiments utilizing different datasets and anomaly types, demonstrating consistent and reliable performance across varying financial scenarios. The achieved F1-Score signifies a strong capability in distinguishing between expected and unexpected financial patterns.
During experiments simulating volatility spikes specifically within the Information Technology sector, the ReGEN-TAD model achieved an Average Match Ratio of 0.693. This metric quantifies the model’s ability to correctly identify the primary drivers contributing to observed anomalies. The Match Ratio is calculated by comparing the model’s attribution of anomaly drivers against a ground truth derived from expert analysis of the simulated volatility events. A ratio of 0.693 indicates that, approximately 69.3% of the time, ReGEN-TAD accurately pinpointed the causal factors behind the observed volatility, demonstrating its effectiveness in attributing the root causes of unusual market behavior within the specified sector.
Beyond the Signal: Dissecting the Drivers of Anomaly
ReGEN-TAD moves beyond simply flagging anomalies to actively dissecting why they occur. Utilizing Factor Attribution techniques, the framework doesn’t just identify unusual behavior, but isolates the precise variables and the specific time periods that most significantly contributed to the detected deviation. This granular analysis allows for a detailed understanding of the anomaly’s drivers-for instance, pinpointing whether a sudden spike in a financial time series was caused by a shift in interest rates, a change in market volatility, or a combination of factors at a particular moment. By decomposing the anomaly’s impact across multiple dimensions, ReGEN-TAD transforms anomaly detection from a signal into actionable intelligence, enabling users to understand the root causes and formulate effective responses.
ReGEN-TAD establishes a uniquely powerful anomaly detection system by fusing the strengths of generative modeling and established econometric diagnostics. This integration allows the framework to not only identify unusual data points but also to understand why those anomalies occurred. Generative models create a learned representation of normal system behavior, while econometric techniques, traditionally used to analyze economic data, rigorously test for statistically significant deviations from that norm. The result is a system that is both sensitive to subtle anomalies and capable of providing a clear, interpretable explanation of the underlying drivers, moving beyond simple detection to offer genuine insight into systemic changes and potential risks. This dual approach enhances robustness, mitigating the risk of false alarms and ensuring that flagged anomalies are grounded in statistically sound reasoning.
The ReGEN-TAD framework overcomes a significant hurdle in financial anomaly detection – the ability to process truly large datasets – through a carefully implemented ensemble learning approach. Rather than relying on a single, computationally intensive model, the framework leverages the collective intelligence of multiple, smaller models, each trained on a different subset of the data or employing a slightly varied methodology. This parallel processing not only drastically reduces computation time, facilitating real-time analysis of extensive financial records, but also enhances robustness by mitigating the risk of a single model being unduly influenced by idiosyncratic data patterns. The resulting scalability permits the application of sophisticated anomaly detection techniques to datasets previously considered intractable, unlocking valuable insights from high-frequency trading data, complex portfolios, and broad macroeconomic indicators.
A critical feature of the ReGEN-TAD framework is its demonstrated stability and precision in identifying anomalies, evidenced by a remarkably low false positive rate of 5.39% during periods of market normalcy. This consistent performance across varied data-generating processes signifies the framework’s robustness and reliability, minimizing spurious signals and ensuring that flagged anomalies genuinely represent deviations from expected behavior. Such a low error rate is not merely a statistical achievement; it translates directly into actionable insights for financial institutions, reducing the burden of investigating false alarms and allowing resources to be focused on genuine risks. The framework’s ability to maintain this level of accuracy ‘in-control’ is foundational to its broader success in detecting and interpreting anomalies even during periods of significant market stress.
ReGEN-TAD’s capacity to dissect complex systemic events is demonstrated through its application to the 2008 financial crisis and the COVID-19 market collapse; the framework doesn’t simply flag these periods as anomalous, but actively identifies the interconnected factors driving the observed disruptions. During both crises, ReGEN-TAD consistently pinpointed economically sensible, cross-sectional variables-such as shifts in credit spreads, volatility indices, and sector-specific performance-as primary contributors to the anomalies. This ability to move beyond mere detection and reveal the underlying economic drivers distinguishes ReGEN-TAD, offering insights into the mechanics of financial stress and providing a valuable tool for risk management and regulatory oversight by illuminating the key vulnerabilities exposed during periods of systemic shock.

The pursuit of ReGEN-TAD, as detailed in the framework, mirrors a fundamental principle: to dismantle established structures to understand their inner workings. This research doesn’t simply accept the surface of financial time series; it actively decomposes them, seeking the hidden architecture beneath. As Mary Wollstonecraft observed, “The mind will not be chained,” and this framework embodies that very spirit – liberating financial data from opaque complexity through generative modeling and rigorous calibration. By dissecting high-dimensional time series and identifying structural breaks, ReGEN-TAD reveals the ‘why’ behind anomalies, not just the ‘what,’ validating the assertion that true understanding necessitates a willingness to challenge and reconstruct existing systems.
What’s Next?
ReGEN-TAD, by formalizing interpretability within a generative anomaly detection framework, doesn’t so much solve the problem of financial irregularity as relocate its core. The challenge now shifts from simply flagging outliers to dissecting the generative process itself – understanding why the model deems a particular sequence anomalous. This necessitates a deeper engagement with the economic assumptions baked into the generative components; a rigorous sensitivity analysis, probing which assumptions, when violated, reliably trigger false positives or missed detections.
The emphasis on calibration is particularly noteworthy. To acknowledge the inherent uncertainty in anomaly scoring is a rare, and frankly refreshing, admission within a field often seduced by precision. However, calibration is static. Future work must explore dynamic calibration-adjusting anomaly thresholds in real-time based on evolving market regimes or the discovery of structural breaks. A system that learns its own risk tolerance is, after all, a more honest reflection of the markets it attempts to model.
Ultimately, the best hack is understanding why it worked, and every patch is a philosophical confession of imperfection. The pursuit of anomaly detection, then, becomes a continuous exercise in reverse-engineering reality-a systematic dismantling of the presumed order to reveal the underlying, often chaotic, mechanisms at play. The true value of ReGEN-TAD lies not in its immediate performance, but in the questions it forces one to ask about the very nature of financial “normality”.
Original article: https://arxiv.org/pdf/2603.07864.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Transformers Under the Microscope: What Graph Neural Networks Reveal
2026-03-10 07:23