Author: Denis Avetisyan
Researchers have released a comprehensive benchmark to help detect increasingly realistic videos created by artificial intelligence.
AIGVDBench, a large-scale dataset and evaluation framework, provides a vital resource for advancing AI-generated video detection and video forensics research.
The increasing realism of AI-generated videos presents a growing challenge to distinguishing synthetic content from authentic footage, yet current detection methods are hampered by limited and outdated evaluation resources. This work introduces AIGVDBench, a comprehensive benchmark designed to address these limitations and serve as a unified platform for advancing research in AI-generated video detection. Comprising over 440,000 videos from 31 state-of-the-art generative models and rigorous evaluation of 33 existing detectors, AIGVDBench reveals key insights and novel findings regarding the strengths and weaknesses of current approaches. Will this resource pave the way for more robust and reliable detection of increasingly sophisticated synthetic media?
The Illusion of Authenticity: When Seeing Isn’t Believing
The advent of sophisticated video generation models, prominently exemplified by platforms like Veo and Sora, represents a pivotal moment in digital content creation, yet simultaneously challenges fundamental perceptions of authenticity. These models, capable of producing remarkably realistic and coherent video sequences from textual prompts, are no longer limited to simple animations or visual effects; they now synthesize scenes with nuanced detail, complex interactions, and stylistic versatility previously exclusive to human filmmakers. Consequently, discerning between genuine footage and AI-generated content is becoming increasingly difficult, not just for casual viewers, but also for automated systems, raising significant implications for media trust, information integrity, and the potential for deceptive practices. The sheer speed of advancement in these generative technologies necessitates a proactive approach to understanding and mitigating the blurring boundaries between reality and simulation.
Current techniques designed to identify AI-generated videos often falter when faced with increasingly sophisticated synthetic content. Initial detection methods relied on identifying obvious artifacts – glitches, inconsistencies in blinking, or unnatural facial features – but modern generative models now produce videos with remarkable realism, minimizing these telltale signs. The challenge lies in the diversity of generation techniques; each model – be it diffusion-based, GAN-based, or something novel – introduces unique characteristics that current detectors struggle to generalize across. Furthermore, nuanced content – videos with subtle expressions, complex scenes, or stylistic choices – presents a significant hurdle, as distinguishing between a skillfully crafted synthetic performance and a naturally occurring one requires a level of perceptual analysis that remains beyond the reach of many automated systems. This inability to reliably detect synthetic media, particularly in scenarios involving subtle manipulation or realistic portrayals, underscores the urgent need for more robust and adaptable detection strategies.
The proliferation of increasingly sophisticated generative models demands a standardized and comprehensive evaluation framework for synthetic media detection. Current detection methods often falter when confronted with subtle manipulations or diverse generation styles, highlighting the urgent need for a benchmark that moves beyond simplistic assessments. A robust benchmark would not only catalog the strengths and weaknesses of existing detectors but also serve as a catalyst for innovation, encouraging the development of algorithms capable of discerning genuine content from increasingly realistic forgeries. This representative evaluation, continually updated to reflect the evolving landscape of generative AI, is crucial for fostering trust in visual media and mitigating the potential for misinformation and malicious use.
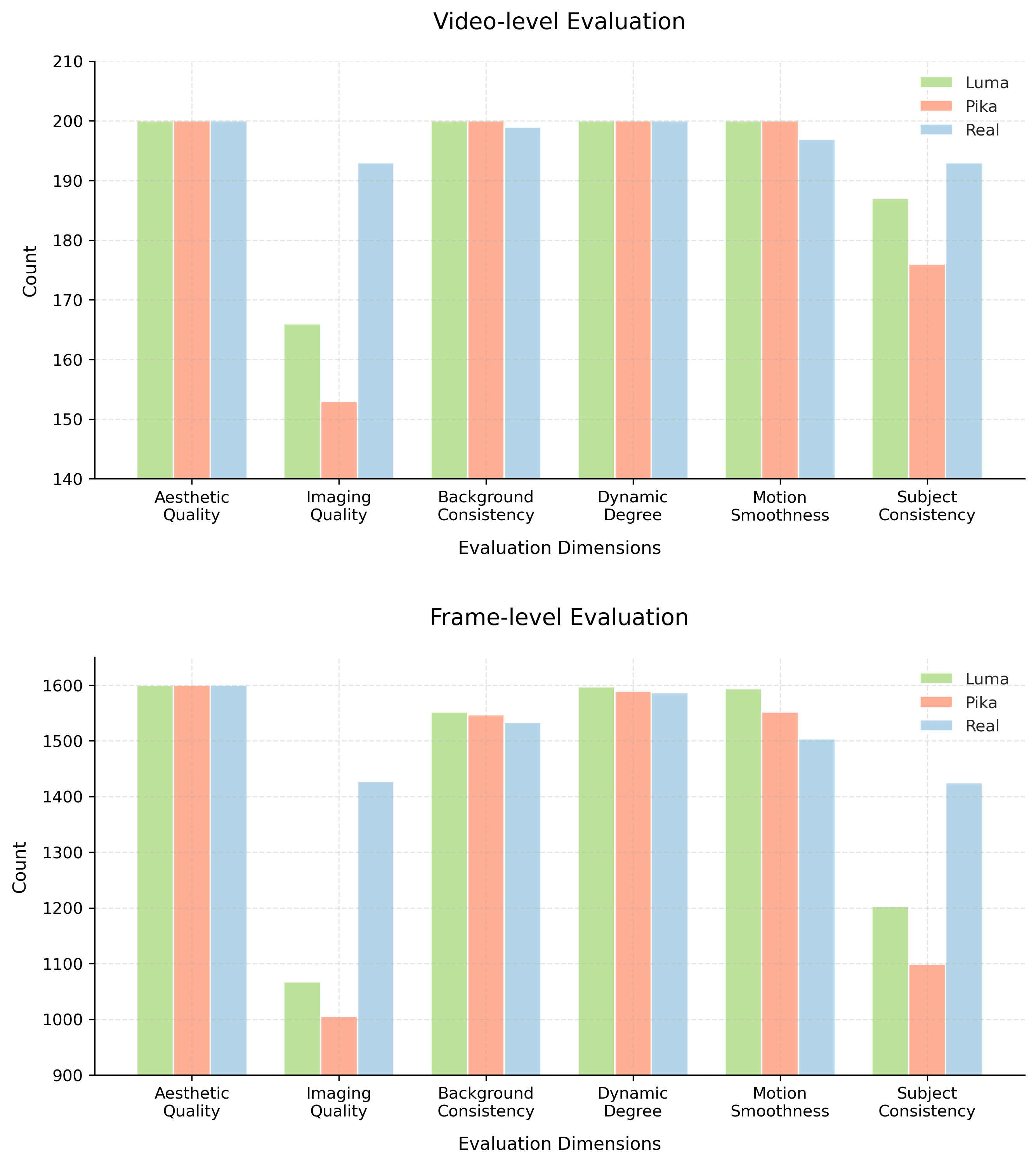
![Evaluation using Vbench[30] demonstrates that our video generation model excels across key metrics-aesthetic quality, background consistency, dynamic range, imaging quality, motion smoothness, and subject consistency-resulting in a superior final score.](https://arxiv.org/html/2601.11035v1/x12.png)
AIGVDBench: Throwing More Data at the Problem (Because What Else Are You Gonna Do?)
AIGVDBench is a newly developed benchmark dataset created to overcome the shortcomings of current methods used to detect AI-generated videos. Existing benchmarks lack the scale and diversity required to effectively evaluate detection algorithms against increasingly sophisticated generative models. AIGVDBench directly addresses this limitation by providing a large-scale, high-quality resource specifically designed for robust evaluation; it aims to improve the reliability and accuracy of AI-generated video detection systems by exposing them to a wider range of synthetic content and challenging scenarios. The dataset’s construction focuses on identifying and mitigating biases present in existing benchmarks, resulting in a more comprehensive and representative evaluation tool.
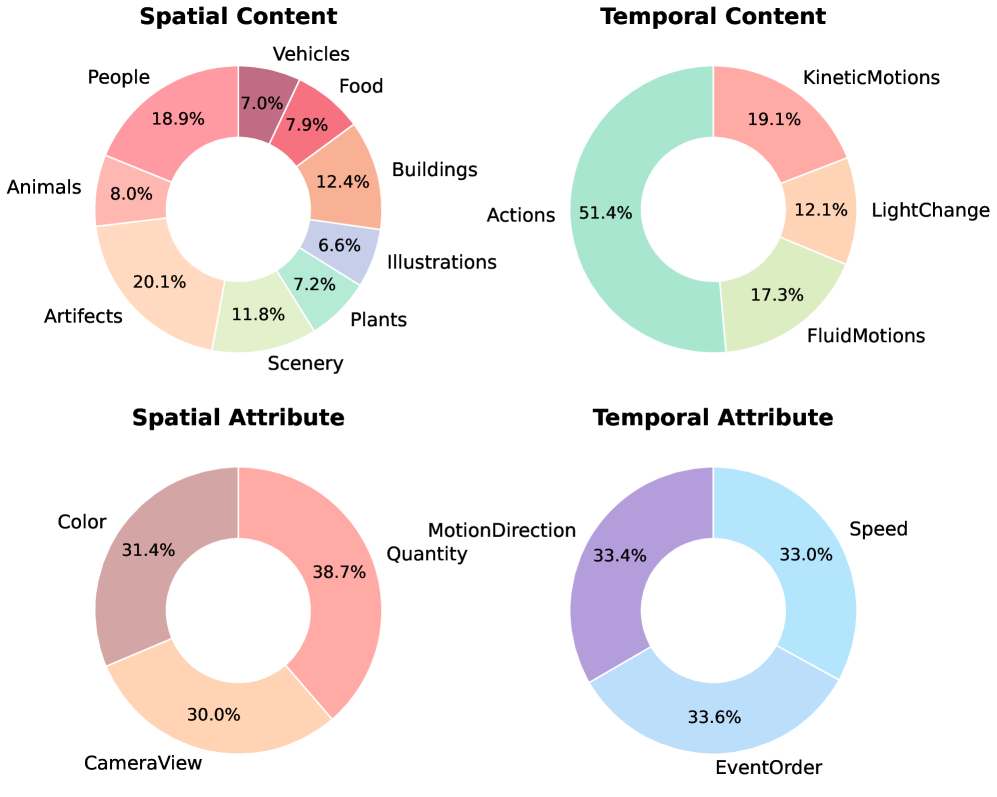
AIGVDBench consists of over 440,000 videos compiled from the outputs of 31 distinct generative models. This scale represents a significant increase compared to existing datasets used for AI-generated video detection. The dataset’s diversity is ensured by inclusion of videos from a wide range of models, encompassing both open-source and closed-source technologies. Specifically, the dataset includes approximately 20,000 videos generated per open-source model and 2,000 videos per closed-source model, contributing to a comprehensive representation of current generative capabilities.
AIGVDBench’s construction utilized the OpenVidHD dataset to provide realistic, naturally-captured video content alongside synthetically generated videos. To ensure broad representativeness, the dataset incorporates 20,000 videos generated by each open-source generative model and 2,000 videos from each closed-source model. This tiered sampling strategy accounts for the greater accessibility and volume of outputs typically available from open-source models, while still providing a substantial contribution from commercially available, closed-source systems. The resulting distribution aims to reflect the current landscape of AI-generated video technologies and facilitate the development of detection methods applicable to a wide range of generative approaches.
The Attribute Balancing Algorithm employed during AIGVDBench dataset construction mitigates inherent biases in generative models and ensures a more equitable distribution of visual features. This algorithm operates by identifying and quantifying key visual attributes – such as lighting conditions, object poses, and background complexity – within the generated video content. It then systematically adjusts the sampling rate from each generative model to counteract imbalances; models producing videos deficient in specific attributes are sampled at a higher rate until the overall distribution across the dataset meets pre-defined balance criteria. This process reduces the potential for detection models to exhibit performance disparities based on these attributes, leading to a more robust and generalizable evaluation of AI-generated video detection techniques.
The Nitty-Gritty Details: How We Tried to Make Sure It Was All Accurate
AIGVDBench incorporates video content encoded using both H.264 and MPEG-4 Part 2 codecs to facilitate comprehensive performance evaluation. The inclusion of these two distinct, yet widely adopted, video compression standards allows researchers to assess the robustness and compatibility of algorithms across a broader spectrum of real-world video formats and encoding techniques. H.264, a more recent standard, offers improved compression efficiency, while MPEG-4 Part 2 maintains relevance due to its continued use in many legacy systems and applications. This dual-codec approach ensures that evaluations are not biased towards a single compression method and provides a more representative assessment of overall video processing capabilities.
The AIGVDBench dataset’s balance and diversity are rigorously evaluated using the Penalized Global Balance Score (PGBS), a metric designed to quantify the distribution of video content across various action classes and environmental conditions. In comparative analysis against established video benchmarks, AIGVDBench consistently achieves the highest PGBS, indicating a more uniform representation of video samples. This superior balance minimizes bias in evaluation pipelines and ensures that models are assessed on a broader, more representative range of scenarios, improving the reliability and generalizability of research findings. The PGBS considers both class distribution and the co-occurrence of actions and scenes, offering a comprehensive assessment beyond simple class balance metrics.
AIGVDBench leverages established deep learning frameworks, specifically MMAction2, to construct its evaluation pipelines. This design choice facilitates standardized benchmarking by providing a consistent environment for performance assessment. Utilizing MMAction2 ensures reproducibility of results, as researchers can readily replicate experiments using a well-documented and widely adopted toolkit. This framework supports common action recognition tasks and provides pre-built modules for data loading, model training, and performance evaluation, minimizing variations introduced by differing implementation details and allowing for direct comparison of algorithms.

The Inevitable Shift: Now We’re Asking AI to Detect AI
The escalating prevalence of AI-generated video necessitates a shift in detection methodologies, increasingly centering on Vision-Language Models (VLMs). Unlike traditional systems focused solely on visual anomalies, VLMs process both the visual content and accompanying textual cues – such as captions, transcripts, or even associated metadata. This dual-input approach is crucial because inconsistencies between the video and its descriptive text often reveal synthetic origins; a scene depicting snowfall, for instance, paired with a description of a desert landscape immediately raises suspicion. These models learn to correlate visual features with linguistic descriptions, enabling a more holistic and robust assessment of authenticity. Consequently, VLMs are not merely identifying manipulated pixels, but reasoning about the semantic coherence of the entire audiovisual presentation, representing a significant advancement in discerning genuine content from increasingly sophisticated forgeries.
The efficacy of contemporary vision-language models in detecting AI-generated video isn’t solely about recognizing fabricated visuals, but critically depends on their capacity for temporal reasoning. These models must analyze sequences of frames, establishing an internal understanding of how events naturally unfold over time. An inability to discern temporal inconsistencies – a sudden jump in lighting, illogical object movement, or actions that defy physics – renders the detection process unreliable. Successfully identifying manipulations, therefore, necessitates a deep comprehension of event duration, cause-and-effect relationships, and the expected flow of visual narratives, effectively allowing the model to ‘reason’ about what it observes happening over time rather than simply analyzing static images.
The performance of Vision-Language Models in detecting AI-generated video isn’t solely dependent on the model’s architecture, but significantly influenced by the art of prompt engineering. This involves crafting specific, detailed textual instructions that guide the model’s analysis, moving beyond simple queries like “is this real?” to nuanced requests focusing on temporal inconsistencies, lighting anomalies, or subtle distortions often present in synthetic media. By strategically phrasing prompts, researchers can effectively steer the model’s attention towards crucial details, improving its ability to discern genuine content from manipulated footage. A well-engineered prompt acts as a precise filter, enabling targeted analysis and maximizing detection accuracy, even when facing increasingly sophisticated AI-generated content designed to evade detection.
The pursuit of perfect detection benchmarks feels…familiar. This AIGVDBench, with its meticulously constructed dataset, aims to solve today’s deepfake problems, but one anticipates tomorrow’s generative models will render its distinctions blurry. It echoes a cycle as old as software itself. Yann LeCun once stated, “The real problem is not building the technology, it’s scaling it.” This sentiment resonates deeply; a beautiful benchmark is only as good as its resilience against the inevitable evolution of adversarial techniques. The dataset construction, while impressive, is merely a snapshot-a compromise that survived deployment, for now. Everything optimized will one day be optimized back, and the cycle continues.
The Inevitable Regression
The construction of AIGVDBench, and datasets like it, addresses a familiar cycle. A benchmark appears, generative models improve to defeat it, and the process repeats. This is not progress so much as increasingly elaborate feature engineering on both sides of a perpetually escalating arms race. The current focus on pixel-level anomalies and frequency domain artifacts is likely to yield diminishing returns. Production systems will invariably discover new, subtler methods of forgery, rendering today’s sophisticated detectors as tomorrow’s baseline.
The field appears to assume that ‘better detection’ equates to a solvable problem. It does not. The goalposts will shift. The incentive structure favors increasingly realistic fakes. AIGVDBench offers a snapshot of the current forgery landscape, but the real challenge isn’t building a more sensitive sensor; it’s acknowledging that perfect detection is an asymptotic limit.
The long-term value may not lie in refining detection algorithms, but in developing robust methods for provenance tracking and content authentication. Until then, the pursuit of ever-more-accurate detectors feels less like innovation, and more like constructing more elaborate crutches for a problem that will inevitably find a way to walk on its own.
Original article: https://arxiv.org/pdf/2601.11035.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-19 15:35