Author: Denis Avetisyan
A new training approach allows language models to generate text faster by learning to predict multiple tokens at once, without sacrificing quality.
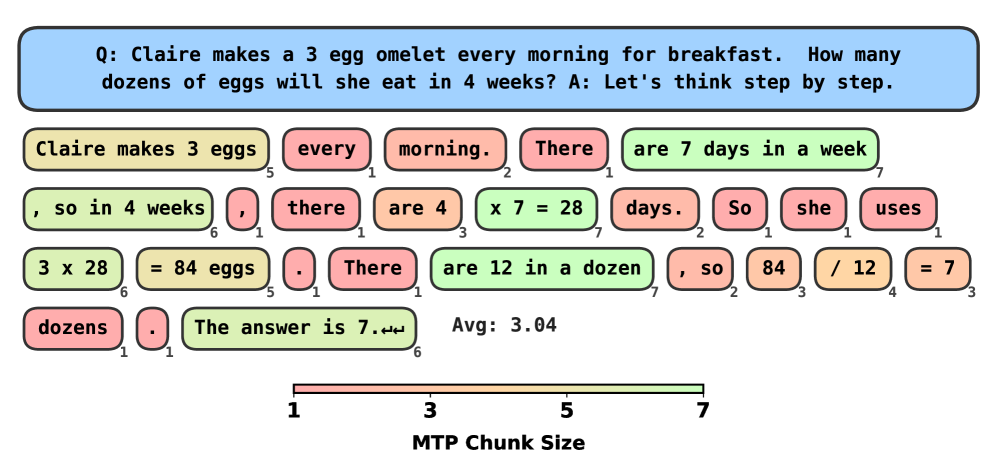
This work introduces a self-distillation method for multi-token prediction, leveraging reinforcement learning principles to accelerate decoding and improve online training.
Efficiently accelerating language model inference remains a key challenge, often requiring complex pipelines and auxiliary models. This paper, ‘Multi-Token Prediction via Self-Distillation’, introduces a novel approach that transforms a standard autoregressive language model into a fast, standalone multi-token predictor using a simple online distillation objective. By enabling simultaneous prediction of multiple tokens, our method achieves over 3\times speedup on the GSM8K benchmark with less than 5% accuracy loss compared to single-token decoding. Could this self-distillation technique unlock a new paradigm for deploying faster and more efficient language models without sacrificing performance?
The Illusion of Sequential Thought
Current language models predominantly rely on sequential prediction – a process known as `NextTokenPrediction` – where each word is generated one after another. While effective for many applications, this approach presents significant challenges for complex reasoning. Tasks demanding sustained information processing, such as solving multi-step mathematical problems or interpreting lengthy narratives, require models to maintain and integrate information over extended sequences. The inherently serial nature of `NextTokenPrediction` creates a bottleneck, as the model must process each token before moving forward, hindering its ability to effectively capture long-range dependencies and perform holistic reasoning. This limitation contrasts sharply with human cognition, where parallel processing allows for simultaneous consideration of multiple factors and rapid integration of information, ultimately impacting the speed and accuracy of complex problem-solving.
The sequential nature of many large language models presents a fundamental limitation when tackling complex reasoning challenges. Because these models generate output one token at a time, a significant latency is introduced, effectively creating a processing bottleneck. This is particularly evident in mathematical problem-solving, where multiple steps and sustained calculations are required; each step is dependent on the previous token’s generation, preventing true parallel processing. Consequently, scalability suffers, as the time required to solve a problem increases linearly with its complexity. While model size can partially mitigate this issue, it doesn’t address the core problem of sequential computation, hindering the development of genuinely efficient and powerful reasoning systems. The limitations imposed by this token-by-token approach necessitate exploration into architectures that better mimic the parallel processing capabilities of human cognition, offering a pathway towards faster and more robust artificial intelligence.
Current language models, despite their impressive abilities, operate with a fundamental limitation: a sequential processing style that sharply contrasts with the parallel nature of human thought. The human brain doesn’t decipher information one piece at a time; instead, it integrates multiple data points simultaneously, enabling rapid comprehension and complex reasoning. This parallel processing allows for the immediate recognition of patterns and relationships, a capability largely absent in models reliant on predicting the next token in a sequence. Consequently, even relatively simple tasks demanding sustained thought, like solving multi-step mathematical problems or understanding nuanced narratives, become bottlenecks for these systems. The inability to leverage parallel computation not only restricts scalability but also hinders overall efficiency, creating a significant gap between artificial and biological intelligence when it comes to reasoning speed and capacity.
Beyond the Bottleneck: A Shift to Parallel Decoding
MultiTokenPrediction introduces a departure from traditional autoregressive decoding by generating multiple output tokens within a single forward pass through the neural network. This contrasts with sequential decoding, where each token’s prediction is contingent on the previously generated token, creating inherent latency. By processing the entire output sequence in parallel, MultiTokenPrediction significantly reduces the number of sequential operations required for text generation. This parallelization directly translates to lower latency – the time delay between input and output – and increased throughput, measured as the number of tokens generated per unit of time. The method achieves this by restructuring the model’s prediction layer to output a probability distribution over multiple tokens simultaneously, enabling concurrent evaluation and selection of the most likely sequence.
The MultiTokenPrediction method utilizes parallel processing to increase computational efficiency, drawing inspiration from the massively parallel architecture of biological neural networks. This is achieved by distributing the prediction of multiple tokens across multiple processing units, allowing for simultaneous computation rather than sequential processing. This parallelization directly reduces the time required for each forward pass, as each unit operates independently on a subset of the prediction task. Consequently, the model can achieve faster reasoning speeds and increased throughput by effectively utilizing available computational resources, similar to how biological systems process information.
Simultaneous multi-token prediction allows the model to retain a more complete contextual understanding during generation. Traditional autoregressive models process tokens sequentially, potentially losing information from earlier tokens as the sequence lengthens. By predicting multiple tokens in parallel within a single forward pass, the model can consider a broader range of preceding tokens when determining the next set of outputs. This improved contextual awareness directly translates to enhanced performance on complex tasks requiring long-range dependencies, and benchmark results demonstrate a generation speed increase of up to 5x compared to conventional single-token prediction methods.

The Teacher-Critic Framework: Distilling Intelligence
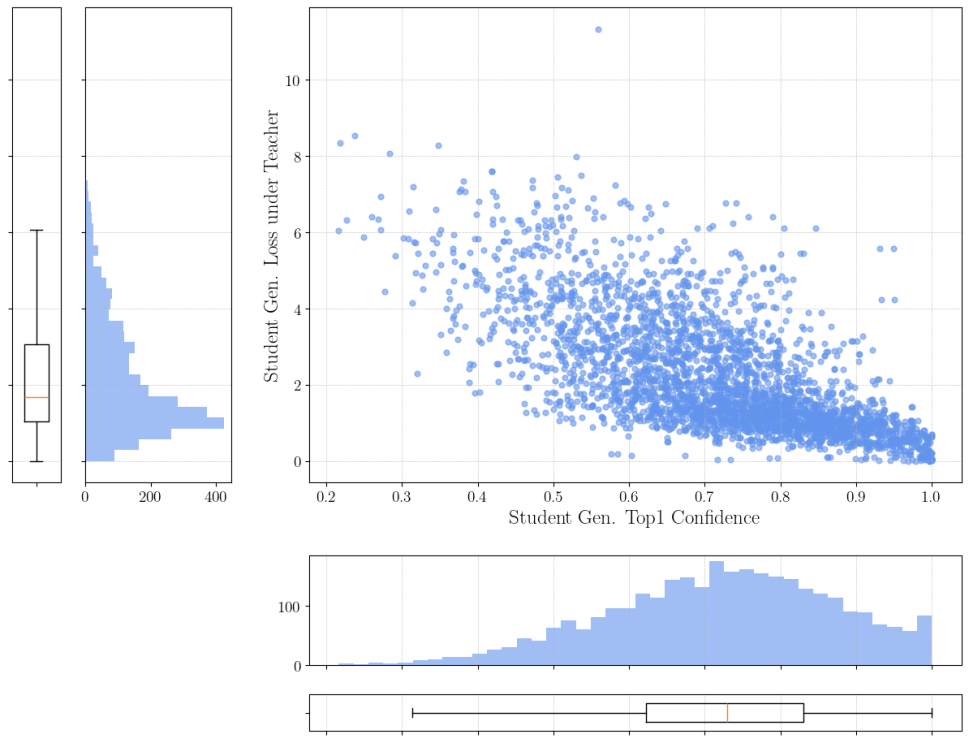
The Teacher-Critic Framework is a learning paradigm consisting of two primary models: a teacher and a student. The teacher model, pre-trained and possessing established predictive capabilities, generates feedback signals used to refine the student model’s parameters. This feedback mechanism allows the student to learn from the teacher’s expertise without direct access to ground truth labels. The student model attempts to mimic the teacher’s behavior, and the discrepancy between their outputs forms the basis for the learning signal. This approach facilitates improved predictive accuracy in the student model, particularly in scenarios where labeled data is limited or unavailable, and allows for knowledge distillation from a complex teacher to a potentially smaller, more efficient student.
The Kullback-Leibler (KL) Divergence, a measure of how one probability distribution diverges from a second, reference probability distribution, is central to the Teacher-Critic Framework. Specifically, it quantifies the difference between the probability distributions output by the teacher and student models for a given input. A lower KL Divergence indicates that the student model’s predictions are closer to those of the teacher, signifying improved alignment with the teacher’s established knowledge. During training, the student model is penalized based on the KL Divergence, effectively minimizing the difference and encouraging the student to mimic the teacher’s behavior. The formula for KL Divergence, D_{KL}(P||Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)}, calculates the information lost when Q is used to approximate P, where P represents the teacher’s distribution and Q represents the student’s distribution.
The training process utilizes the Softmax function to convert raw prediction scores into a probability distribution over the vocabulary, allowing the model to assess the likelihood of each token being the next in the sequence. Following the Softmax calculation, the Argmax function is then employed to select the token with the highest probability as the predicted next token. This combination ensures that the model consistently chooses the most probable token based on its current understanding, driving the learning process towards generating coherent and contextually relevant sequences. The use of Softmax and Argmax facilitates efficient and deterministic token selection during both training and inference.
Efficiency and Scalability: A Dance of Cache and Adaptation
The computational demands of large language models are substantially lessened through the implementation of a key-value cache. This technique stores the results of prior computations – specifically, the key and value vectors generated during the attention mechanism – effectively preventing redundant calculations during decoding. Instead of recomputing these vectors for each step, the model retrieves them directly from the cache, drastically reducing processing time and memory access. This cached data represents the model’s ‘understanding’ of the preceding text, allowing it to focus computational resources on predicting the next token rather than re-evaluating established context. The efficiency gained is particularly pronounced in tasks involving lengthy sequences, where repeated calculations would otherwise dominate the processing time, ultimately leading to faster and more scalable decoding.
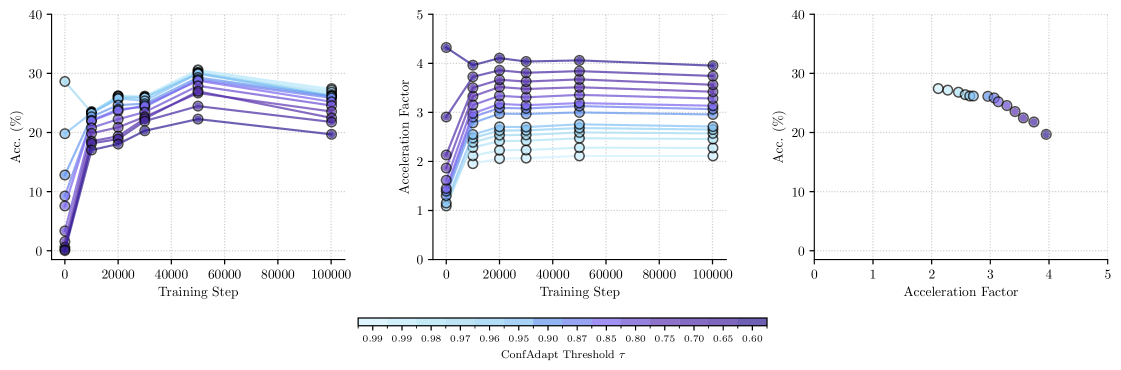
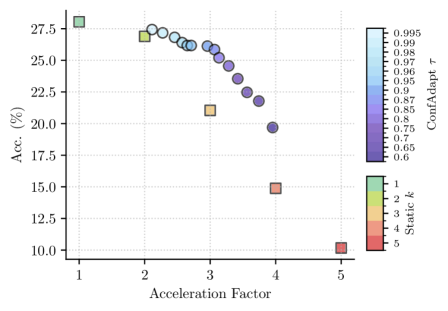
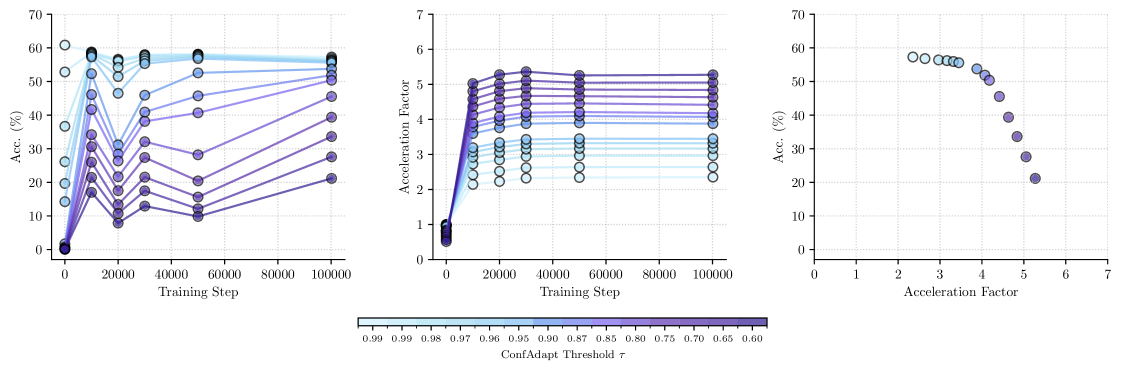
Adaptive decoding represents a significant advancement in optimizing large language model performance by dynamically tailoring the decoding process to the model’s own confidence. Rather than employing a static decoding strategy, this technique monitors the probability distributions generated during inference and adjusts parameters – such as the number of tokens considered at each step – in real-time. When the model exhibits high confidence in its predictions, decoding accelerates by exploring fewer possibilities; conversely, when uncertainty increases, the process becomes more exhaustive, prioritizing accuracy. This intelligent balancing act not only enhances speed, achieving up to a fivefold increase in throughput, but also maintains, and in some cases improves, overall performance on complex reasoning tasks, effectively bridging the gap between computational efficiency and reliable results.
Rigorous evaluation on established benchmarks confirms the efficacy of this approach to mathematical reasoning. Performance metrics on the challenging GSM8K Benchmark and MetaMathQA Dataset demonstrate a substantial improvement over existing methodologies. These datasets, designed to assess a model’s capacity for multi-step problem solving and complex mathematical deduction, reveal a consistent and significant increase in both accuracy and efficiency. The results highlight not only the model’s ability to arrive at correct solutions, but also its capacity to do so with greater computational economy, suggesting a robust and scalable solution for advanced mathematical tasks. This superior performance underscores the potential for wider application in fields demanding precise and reliable mathematical computation.
Toward a Future of Expanded Reasoning
Investigations are slated to focus on incorporating CausalAttention, a mechanism designed to refine how AI models interpret context and establish connections between distant pieces of information within a sequence. This approach moves beyond standard attention by explicitly modeling causal relationships, allowing the system to better discern which parts of the input are truly relevant to the current processing step. By strengthening the ability to capture long-range dependencies – the connections between elements separated by many intervening steps – researchers anticipate improvements in tasks requiring a nuanced understanding of complex narratives or intricate data. The anticipated outcome is a system capable of more accurate and coherent reasoning, particularly when faced with ambiguous or incomplete information, ultimately leading to more robust and reliable artificial intelligence.
A critical next step involves rigorously testing the adaptability of this accelerated reasoning method across a diverse range of established language models. Investigations will center on integrating the architecture with models like Llama-3.1-8B-Magpie and Qwen3-4B-Instruct-{2507}, chosen for their varying sizes and training paradigms. This compatibility assessment isn’t merely about technical implementation; it’s about unlocking broader applicability and ensuring the method isn’t confined to a single model type. Successful integration with these – and potentially other – pretrained models will dramatically increase the versatility of the approach, paving the way for deployment in a wider spectrum of natural language processing tasks and applications.
The architecture holds considerable promise for tackling notoriously difficult challenges in artificial intelligence, specifically within the realms of common-sense reasoning and scientific discovery. Current AI systems often struggle with tasks requiring intuitive understanding of the physical world or the ability to draw inferences based on incomplete information – areas where humans excel. By enhancing an AI’s capacity for contextual understanding and long-range dependency modeling, this work aims to bridge that gap, enabling systems to not only process data but to reason with it. This advancement could unlock new possibilities in fields like automated hypothesis generation, literature review, and complex problem-solving, ultimately contributing to the development of more intelligent and efficient AI capable of assisting – and potentially accelerating – progress across numerous scientific disciplines.
The pursuit of accelerated decoding, as detailed in this work on multi-token prediction, echoes a fundamental tension within all complex systems. It isn’t merely about achieving speed, but about navigating the inherent trade-offs between efficiency and robustness. The system’s ability to predict multiple tokens simultaneously, guided by a reinforcement learning objective, suggests a move towards anticipating future states, a dance with entropy itself. As David Hilbert observed, “We must be able to answer the question: What are the ultimate principles of mathematical thought?” This resonates deeply; the principles governing language model architecture aren’t static rules, but emergent behaviors discovered through iterative refinement, a continual postponement of chaos through increasingly sophisticated prediction. The work highlights that order is, indeed, just cache between two outages, as the model strives for ever-greater predictive power in a constantly shifting landscape of linguistic possibilities.
The Unfolding Scroll
The pursuit of accelerated decoding, as demonstrated by this work, reveals a familiar pattern. Each optimization promises liberation from latency, yet invariably introduces new dependencies-a more intricate reward function, a sensitive hyperparameter space, or a reliance on carefully curated training data. It is not speed that is achieved, but a shifting of the bottleneck. The system doesn’t become faster; it becomes more brittle, demanding ever-increasing levels of maintenance to sustain the illusion of efficiency.
The notion of distilling knowledge into a multi-token predictor is compelling, but begs the question of what is lost in the compression. Language is not merely a sequence of tokens to be anticipated; it is a tapestry of nuance, context, and ambiguity. To train a model to ‘see’ multiple steps ahead is to invite a narrowing of perspective, a preference for the predictable over the genuinely novel. The system will optimize for a correct continuation, not all possible correct continuations.
Future work will likely focus on adaptive distillation strategies, attempting to balance predictive power with expressive range. However, it is worth remembering that order is just a temporary cache between failures. The true challenge lies not in building systems that anticipate the future, but in designing those that gracefully accommodate its inevitable surprises.
Original article: https://arxiv.org/pdf/2602.06019.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Vecna’s Ultimate Goal on STRANGER THINGS 5 and How The Party Can Defeat Him
2026-02-08 11:54