Author: Denis Avetisyan
A new approach to text generation dramatically boosts performance by cleverly repurposing information from previously discarded possibilities.

Lyanna, a hidden state-based speculative decoding system, achieves up to 3.3x speedup in large language model inference through token-info embedding and optimized draft model reuse.
While speculative decoding accelerates large language model (LLM) inference through parallel draft and verification, a significant portion of generated draft tokens are often discarded, representing wasted computation. The work ‘Make Every Draft Count: Hidden State based Speculative Decoding’ addresses this inefficiency by introducing Lyanna, a novel system that reclaims value from these rejected drafts through hidden state reuse. By performing auto-regressive prediction at the hidden state level and employing a specialized draft model, Lyanna enables the repurposing of previously discarded computations, achieving up to a 3.3x speedup over standard methods. Could this approach unlock even greater gains in LLM inference efficiency and pave the way for more sustainable AI applications?
The Inevitable Bottleneck: A System’s Constraint
Large Language Models (LLMs) have achieved impressive feats in natural language processing, exhibiting abilities ranging from text generation to complex reasoning. However, this power comes at a significant computational cost, largely due to their reliance on autoregressive decoding. This process generates text sequentially, predicting each subsequent token based on all previously generated tokens. While conceptually simple and effective, it inherently limits parallelization; each new token must await its predecessors, creating a performance bottleneck that scales with both model size and the length of the generated sequence. Consequently, even with substantial computational resources, generating lengthy or intricate responses can become prohibitively slow, hindering the practical deployment of these otherwise powerful models and driving research into more efficient decoding strategies.
The core of many large language models’ computational demands lies in their sequential processing of tokens during decoding. Each new token generated is contingent upon all preceding tokens, forcing a step-by-step calculation that scales poorly with both model size and the length of the generated sequence. This inherently serial process creates a significant performance bottleneck; as models grow to encompass billions of parameters and tackle increasingly complex prompts requiring lengthy outputs, the time needed for each token’s generation accumulates dramatically. Consequently, even with substantial hardware acceleration, the sequential nature of traditional decoding methods limits the overall throughput and responsiveness of these powerful models, hindering their practical application in real-time scenarios and demanding further innovation in parallelizable decoding strategies.
The fundamentally sequential nature of autoregressive decoding presents a significant obstacle to scaling language model performance on complex tasks. Because each token’s generation is contingent on all preceding tokens, the process resists parallelization – a critical limitation as models grow in size and the desired sequence lengths increase. This dependency forces computations to unfold one after another, effectively serializing what could otherwise be a massively parallel operation. Consequently, reasoning abilities-particularly those requiring exploration of multiple possibilities or nuanced understanding of long-range dependencies-are constrained by this computational bottleneck, hindering the model’s capacity to efficiently process and synthesize information from extended contexts and ultimately limiting its overall cognitive potential.

Embracing Parallelism: A Shift in Decoding Strategy
Speculative decoding utilizes a smaller, faster ‘draft model’ to generate potential future tokens in parallel with the primary, high-accuracy model. The draft model predicts a sequence of tokens ahead of the primary model’s current position, effectively creating a speculative lookahead. These draft tokens are then proposed to the primary model for verification; if accepted, the computationally expensive forward pass for those tokens is skipped, as the primary model directly incorporates the predicted output. This parallel prediction and verification process aims to accelerate token generation by reducing the total number of full forward passes required, particularly for extended sequences where the benefits of skipping computations accumulate.
Speculative decoding reduces computational cost by minimizing full forward passes through the primary language model. Instead of processing each token sequentially, a smaller “draft” model generates potential future tokens in parallel. These predictions are then verified against the main model; only incorrect predictions require a full forward pass for correction. This verification process means that, on average, fewer than one full forward pass is needed per generated token, particularly with accurate draft models, leading to substantial performance gains as the number of tokens increases.
Parallel decoding strategies, such as speculative decoding, demonstrably improve large language model performance by increasing throughput and reducing latency, with benefits scaling proportionally to sequence length. Traditional autoregressive decoding necessitates sequential token generation, creating a performance bottleneck for extended outputs. By generating multiple draft tokens concurrently, and verifying them with a slower, more accurate model, speculative decoding amortizes the cost of full forward passes. This parallelization allows a greater number of tokens to be processed per unit time, directly increasing throughput. Furthermore, the reduction in sequential dependencies minimizes wait times, leading to lower latency, particularly noticeable when generating long-form content like articles or code.
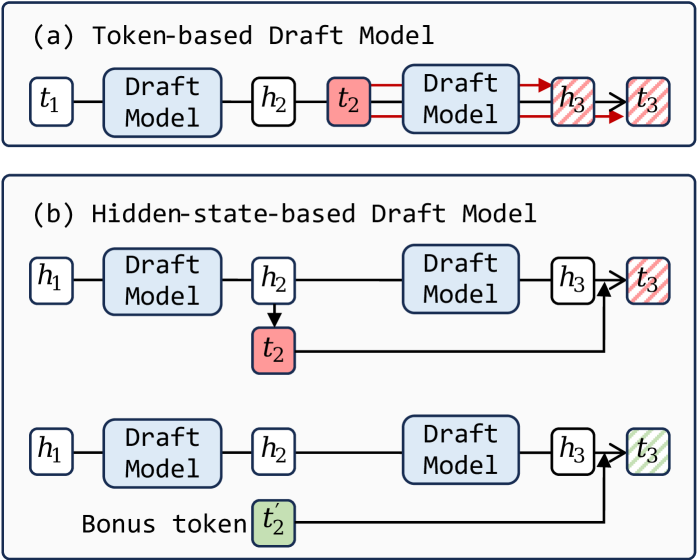
Lyanna: Refinement Through Hidden State Reuse
Lyanna improves upon existing speculative decoding methods by introducing a technique for reusing hidden states generated during the draft model’s forward pass. Traditionally, these intermediate states are discarded after the draft, requiring recalculation during verification. Lyanna stores and reuses these drafted hidden states, significantly reducing redundant computation. This reuse applies to both the key and value projections, minimizing computational waste and enabling a more efficient overall decoding process. The approach avoids recomputation by leveraging previously generated representations, directly contributing to the reported 60.9% reduction in draft model forward latency and overall performance gains.
Token Information Embedding and Hot-Token Sparsity are key components in Lyanna’s optimization of memory usage and sampling efficiency. Token Information Embedding reduces the dimensionality of token representations, minimizing the memory footprint required to store and process hidden states. Hot-Token Sparsity identifies and prioritizes the most probable tokens during the draft stage, focusing computational resources on a reduced set of candidates. This selective approach diminishes the need to process all possible tokens, resulting in substantial reductions in both memory access and computational load during the sampling process and ultimately accelerating decoding speeds.
Lyanna demonstrates significant performance gains in text generation, achieving a 3.3x improvement in throughput compared to standard auto-regressive decoding methods. Evaluations indicate that Lyanna surpasses the performance of existing speculative decoding techniques, such as EAGLE, by up to 1.4x. These improvements are coupled with a substantial reduction in draft model forward latency, decreasing it by 60.9%. These results collectively demonstrate Lyanna’s efficiency in accelerating the decoding process without compromising output quality.
The Lyanna model demonstrates high performance in its multi-step verification process. Acceptance rates are reported at 91% during the initial verification Step 1, indicating a strong correlation between draft and complete model outputs. Subsequent steps exhibit progressively lower, but still substantial, acceptance rates: 80% in Step 2 and 70% in Step 3. These rates reflect the increasing complexity of verification as the model progresses through each stage, while maintaining a high overall level of agreement between the draft and complete model predictions.

Synergistic Architectures: Amplifying Decoding Efficiency
Lyanna’s architecture achieves notable speed gains through strategic integration with established optimization techniques focused on attention mechanisms. Traditional transformer models require substantial memory to store attention keys and values, becoming a bottleneck during processing. By employing Paged Attention, Lyanna divides these key-value pairs into smaller, more manageable pages, reducing memory overhead and enabling efficient access. Complementing this, FlashInfer further accelerates calculations by restructuring how attention is computed, minimizing data movement and maximizing hardware utilization. The combined effect isn’t merely incremental; these optimizations fundamentally alter the processing speed, allowing Lyanna to handle complex sequences with greater efficiency and paving the way for real-time applications and larger model sizes.
The architecture incorporates advanced draft models, such as EAGLE, to significantly refine predictive capabilities while simultaneously lessening computational demands on the primary model. This approach functions by initially generating a preliminary prediction – the ‘draft’ – using a smaller, more efficient model. This draft then serves as a guiding input for the larger model, effectively narrowing the search space and accelerating the final prediction process. By offloading initial processing to EAGLE, the system achieves heightened accuracy, particularly in complex sequences, and distributes the workload for improved overall efficiency. This tiered prediction strategy allows Lyanna to maintain high performance with reduced resource consumption, proving especially valuable when dealing with extended contexts and demanding tasks.
The decoding process in large language models often presents a computational bottleneck, but recent advancements have demonstrated significant improvements through the synergistic combination of One-Pass Logits Computation and Mixture-of-Experts (MoE) architectures. Traditional decoding methods require repeated computations of logits – the raw, unnormalized prediction scores – for each token generated. One-Pass Logits Computation streamlines this by calculating logits only once per layer, dramatically reducing redundancy. When coupled with MoE, where different parts of the model specialize in different types of data, this approach achieves remarkable scalability. The MoE architecture distributes the computational load across multiple experts, and the efficient logits computation ensures each expert can process information quickly, leading to faster and more efficient decoding without sacrificing accuracy. This innovative combination allows Lyanna to handle increasingly complex tasks and larger datasets with greater ease and speed.
Significant gains in performance are achieved through the implementation of resampling and Verification Fusion techniques. Testing demonstrates a marked improvement of 23.1% when integrated with the LLaMA-2-7B model, and an 18.7% increase with Vicuna-7B-v1.5. These methods refine the model’s predictive capabilities by strategically re-evaluating potential outputs and cross-validating them against existing data, ultimately leading to more accurate and reliable results. The fusion process effectively combines the strengths of multiple verification steps, minimizing errors and enhancing the overall robustness of the system – a crucial advancement for applications demanding high precision and consistency.

SLO-Customized Decoding: Adapting to the Needs of the System
SLO-Customized Speculative Decoding represents a shift towards intelligent, application-aware language model deployment. Rather than operating with fixed decoding parameters, the system dynamically adjusts its behavior to satisfy pre-defined Service Level Objectives – essentially, performance guarantees. This is achieved through techniques like altering the ‘Acceptance Length’, which governs how much of a speculative draft is considered valid before continuing. By prioritizing shorter acceptance lengths, the system minimizes latency – crucial for interactive applications – while longer lengths maximize throughput, ideal for batch processing tasks. This adaptive capability isn’t merely about speed; it’s about resource optimization, enabling large language models to function effectively across a wider spectrum of real-world demands and infrastructure constraints, moving beyond a one-size-fits-all approach to decoding.
The system’s adaptability hinges on fine-tuning parameters such as Acceptance Length, which governs how far ahead the decoding process speculates before verifying its predictions. A shorter Acceptance Length minimizes latency by reducing the lookahead, making the system respond more quickly – crucial for interactive applications like chatbots. Conversely, a longer Acceptance Length prioritizes throughput by allowing for more extensive speculative decoding, potentially generating more tokens per unit of time, ideal for batch processing or tasks where immediate response isn’t paramount. This dynamic adjustment allows the system to shift its operational focus, effectively trading off speed for efficiency, and ensuring optimal performance across a broad spectrum of application requirements.
The capacity of SLO-customized decoding to dynamically adjust to varying demands significantly broadens the scope of large language model deployment. Previously, a one-size-fits-all approach often necessitated compromises – prioritizing speed over accuracy, or vice versa. Now, applications with strict latency requirements, such as real-time dialogue systems, can be optimized for immediate responsiveness, while those focused on maximizing throughput, like batch document processing, can prioritize comprehensive output. This granular control extends the usability of these models to scenarios previously considered impractical, including resource-constrained environments and applications requiring highly specialized performance characteristics. Ultimately, this adaptability promises to integrate large language models seamlessly into a far wider range of real-world applications, driving innovation across numerous industries.
The pursuit of accelerated LLM inference, as demonstrated by Lyanna’s hidden state reuse, echoes a fundamental principle of resilient systems. Every rejected token, rather than being discarded, becomes a record in the annals of computation-a preserved state for potential future use. This mirrors the observation of David Hilbert: “We must be able to answer every well-defined question with a finite amount of time.” Lyanna’s approach doesn’t circumvent the inherent sequential nature of auto-regressive decoding, but it minimizes redundant computation by gracefully aging rejected states, effectively reducing the tax on ambition and increasing arithmetic intensity. It acknowledges that progress isn’t about avoiding failure, but about efficiently learning from every draft.
What Lies Ahead?
Lyanna presents a temporary reprieve from the relentless arithmetic demands of auto-regressive decoding. The system efficiently caches potential futures, but this very caching highlights a fundamental truth: stability is an illusion cached by time. The gains achieved are not a negation of latency-every request still pays the tax-but a clever redistribution of its burden. Future work will inevitably confront the limits of this redistribution. The hidden states, once repurposed, represent a divergence from the purely sequential path, and the cost of correcting erroneous speculation will increase with model scale.
The embedding of token-level information into the hidden state reuse mechanism is a promising direction, but a complete accounting of the information content lost or distorted during this process remains. The system’s performance will be sensitive to the characteristics of the input data, and the boundaries of its applicability will require careful mapping. Further gains may be found in dynamic strategies for managing the cache – anticipating which drafts are more likely to succeed, and discarding those that are statistically improbable.
Ultimately, the pursuit of faster inference is a temporary stay of execution. The underlying problem – the computational intensity of these models – will not vanish. The field will likely shift toward increasingly specialized hardware, or toward models that inherently require less sequential processing. Each optimization is merely a slowing of the inevitable decay, a brief extension of uptime before the system succumbs to the demands of its own complexity.
Original article: https://arxiv.org/pdf/2602.21224.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Biogen’s Jolly Good Showing
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
2026-02-26 19:17