Author: Denis Avetisyan
A new reinforcement learning approach is enabling unmanned aerial vehicles to navigate complex environments with improved efficiency and safety.
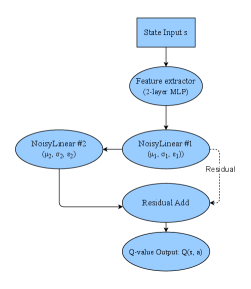
This review details an improved Noisy Deep Q-Network algorithm for UAV trajectory optimization, addressing communication constraints and obstacle avoidance with faster convergence and higher rewards.
Effective path planning for unmanned aerial vehicles (UAVs) in complex environments remains a challenge due to the need for robust exploration and stable learning. This is addressed in ‘UAV Trajectory Optimization via Improved Noisy Deep Q-Network’, which proposes enhancements to the Noisy Deep Q-Network (DQN) algorithm for improved UAV navigation. By integrating a residual NoisyLinear layer with adaptive noise scheduling and employing smooth loss and soft target network updates, the research demonstrates significantly faster convergence, up to a $+40$% increase in rewards, and reduced step counts compared to standard DQN approaches. Could these improvements pave the way for more reliable and efficient UAV operation in real-world scenarios with communication constraints and dynamic obstacles?
Navigating the Complexities of Autonomous Flight
Truly independent operation of Unmanned Aerial Vehicles (UAVs) necessitates a level of navigational autonomy capable of functioning effectively within unpredictable, real-world settings. Unlike controlled environments, external locations present a multitude of challenges, including fluctuating lighting conditions, variable terrain, and the presence of unforeseen obstacles. Current research focuses on developing algorithms that allow UAVs to perceive and interpret these complexities, moving beyond pre-programmed flight paths to embrace reactive, adaptive navigation. This demands not only sophisticated sensor integration – combining data from cameras, lidar, and inertial measurement units – but also advanced computational power onboard the UAV to process information and make critical decisions in real-time, ensuring safe and efficient flight even when faced with unexpected circumstances or the loss of external guidance.
The practical deployment of unmanned aerial vehicles (UAVs) is fundamentally challenged by the realities of wireless communication. Limited bandwidth restricts the volume of sensory data – such as camera feeds or lidar scans – that can be transmitted back to a ground station in real-time, hindering informed decision-making for autonomous flight. Furthermore, signal attenuation, caused by factors like distance, atmospheric conditions, and physical obstructions, reduces signal strength and reliability, potentially leading to dropped connections or delayed commands. Researchers are actively investigating strategies like edge computing – processing data onboard the UAV – and advanced compression algorithms to mitigate these limitations, enabling more resilient and effective autonomous operation even in communication-constrained environments. This focus on robust communication is crucial for applications ranging from precision agriculture to infrastructure inspection, where consistent connectivity is paramount for safe and reliable performance.
Truly autonomous navigation for unmanned aerial vehicles necessitates more than simply charting a course; it demands sophisticated obstacle avoidance capabilities in ever-changing environments. Current research focuses on algorithms that allow UAVs to perceive and react to unanticipated impediments – from moving pedestrians and vehicles to temporary construction or sudden weather events. These systems often integrate data from multiple sensors, including cameras, lidar, and radar, to build a comprehensive understanding of the surrounding space. The challenge lies in processing this information in real-time and generating safe, efficient trajectories that account for the unpredictable motion of dynamic obstacles, ensuring the UAV can reliably reach its destination without collision, even in complex and congested areas.
Reinforcement Learning: A Pathway to Intelligent UAV Control
Reinforcement Learning (RL) offers a methodology for unmanned aerial vehicle (UAV) autonomous navigation by enabling the UAV to learn an optimal policy through interaction with an environment. Unlike traditional control methods requiring pre-programmed behaviors or extensive manual tuning, RL algorithms allow the UAV to discover effective strategies via trial and error. This process involves the UAV performing actions in an environment, receiving rewards or penalties based on those actions, and iteratively adjusting its behavior to maximize cumulative reward. The UAV learns to associate specific states with optimal actions, enabling it to navigate complex environments and achieve defined objectives without explicit programming for every possible scenario. This is particularly useful in dynamic or unpredictable environments where pre-defined rules may be insufficient.
Deep Q-Networks (DQNs) address the scalability issues of traditional Q-learning by utilizing deep neural networks as function approximators to estimate the optimal action-value function, Q(s,a). Instead of maintaining a table of Q-values for each state-action pair, a DQN employs a neural network that takes a state as input and outputs the Q-values for all possible actions in that state. This allows DQNs to generalize to previously unseen states, which is crucial for complex, continuous state spaces encountered in UAV control. The network is trained using a variant of the Q-learning update rule, incorporating techniques like experience replay and target networks to stabilize the learning process and prevent oscillations. Experience replay stores past experiences – state, action, reward, and next state – in a replay buffer, which are then randomly sampled during training to break correlations between consecutive samples. Target networks, periodically updated copies of the main Q-network, are used to calculate the target Q-values, further enhancing stability.
Temporal Difference (TD) learning is a model-free reinforcement learning method where the UAV estimates the value of a state by bootstrapping from the estimated value of subsequent states. Unlike Monte Carlo methods which require an entire episode to complete before updating values, TD learning updates its value estimates after each step, allowing for faster learning and adaptation to changing environments. This is achieved through the Bellman equation, which expresses the value of a state as the immediate reward plus the discounted value of the next state: V(s) = R(s,a) + \gamma V(s'), where γ is the discount factor. By repeatedly updating these value estimates based on observed transitions, the UAV refines its policy to maximize cumulative reward.
Enhancing Exploration and Stability with Advanced DQN Variants
Noisy DQN improves exploration in deep reinforcement learning by introducing parameter noise, which directly perturbs the weights of the neural network. This contrasts with methods that add noise to the actions themselves. By applying noise at the parameter level, the agent consistently explores a variety of actions without requiring explicit exploration strategies like ε-greedy approaches. Specifically, noise is added to each weight independently, sampled from a normal distribution with standard deviation σ. This encourages consistent, correlated exploration, as similar states will likely yield similar noisy action values. The magnitude of this noise can be adjusted to control the extent of exploration during training.
Soft Target Updates are implemented in Deep Q-Networks (DQNs) to improve training stability by mitigating oscillations caused by abrupt changes to the target Q-values. Rather than directly copying the weights from the primary Q-network to the target network at each step, a weighted average is used. Specifically, the target network’s weights are updated as θ_t = τθ_p + (1-τ)θ_t , where θ_p represents the weights of the primary Q-network, θ_t represents the weights of the target network, and τ is a parameter (typically a small value like 0.001) that controls the rate of update. This approach effectively creates a slowly changing target, reducing the variance in the learning process and promoting more consistent value estimations.
Adaptive Noise Scheduling optimizes exploration in Deep Q-Networks by modulating the standard deviation of the injected noise during training. Initially, a higher noise level encourages broader exploration of the action space. As the agent learns and exploits more effectively, the noise level is progressively reduced, allowing for finer-grained action selection and improved convergence. This dynamic adjustment prevents premature convergence on suboptimal policies while maintaining sufficient exploration early in training, leading to more robust and efficient learning. The noise level is typically decayed linearly or according to a predefined schedule, though more complex adaptive strategies are also employed.
Refining Learning Through Strategic Training Techniques
A learning rate warm-up strategy addresses initial training instability by gradually increasing the learning rate from a small value to the target learning rate over a defined number of training steps. This approach mitigates large gradient updates at the start of training, which can occur when the model’s parameters are randomly initialized and sensitive to initial data exposure. By starting with a lower learning rate, the model can establish a more stable foundation before exploring the full parameter space, leading to more consistent and reliable convergence, particularly in complex models or with large batch sizes. The warm-up period is typically a hyperparameter tuned based on the specific model architecture and dataset characteristics.
Cosine annealing is a learning rate schedule that reduces the learning rate following a cosine function, transitioning from an initial value to a minimal value over the training period. This approach facilitates policy fine-tuning by allowing larger updates early in training to escape local optima, and smaller, more precise updates later to converge on an optimal solution. The cyclical nature of the cosine function, with periods of decreasing and potentially increasing learning rates, helps to prevent oscillations commonly observed with step-wise decay schedules and encourages exploration of the parameter space. Mathematically, the learning rate \eta_t at training step t is calculated as \eta_t = \eta_{max} <i> 0.5 </i> (1 + cos(\frac{\pi * t}{T})) , where \eta_{max} is the maximum learning rate and T is the total number of training steps.
Factorized Gaussian Noise reduces computational overhead in training by decoupling the noise generation process into independent dimensions. Instead of generating correlated noise vectors, which requires more complex calculations, each element of the noise vector is sampled independently from a Gaussian distribution with a mean of zero and a specified standard deviation. This factorization simplifies the noise generation process, allowing for faster computation and reduced memory requirements, particularly when dealing with high-dimensional action spaces. The parameters defining the Gaussian distribution, specifically the standard deviation, are typically hyperparameters tuned to optimize training performance and exploration.
Towards Robust and Intelligent UAV Navigation Systems
Unmanned aerial vehicles (UAVs) are increasingly tasked with navigating intricate and unpredictable environments, demanding sophisticated navigational systems. Recent advancements focus on leveraging Deep Q-Networks (DQNs), a type of reinforcement learning, but traditional DQNs often struggle with the complexities of real-world scenarios. Integrating improved DQN variants and specialized training strategies addresses these limitations, enabling UAVs to learn optimal navigation policies more efficiently and reliably. This approach bolsters robustness against unforeseen obstacles and dynamic conditions, while simultaneously optimizing flight paths for increased efficiency. Consequently, UAVs equipped with these advanced systems demonstrate a heightened capacity for autonomous operation, paving the way for broader applications in fields like delivery services, environmental monitoring, and search and rescue operations.
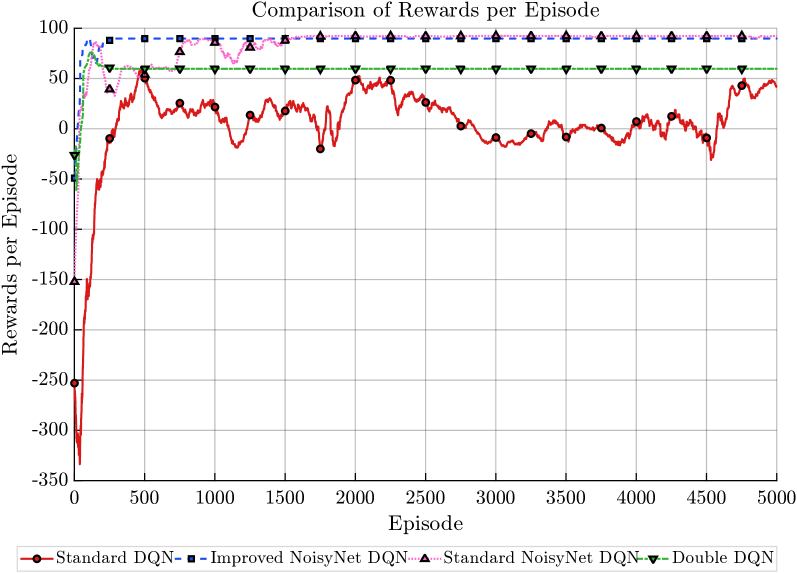
Recent advancements in unmanned aerial vehicle (UAV) navigation demonstrate a significant leap in efficiency through the implementation of an Improved Noisy Deep Q-Network (DQN) algorithm. This novel approach drastically reduces the computational burden associated with UAV pathfinding, achieving convergence-the point at which the algorithm learns an optimal policy-in a markedly shorter timeframe. Notably, testing revealed the algorithm consistently reached the theoretical lower bound for necessary steps to complete a navigational task, a benchmark that competing algorithms failed to meet, requiring approximately 40 steps for equivalent performance. This reduction in required steps translates directly to lower energy consumption, faster response times, and improved operational capacity, suggesting a pathway toward highly efficient and readily deployable autonomous UAV systems.
The developed navigational framework demonstrates a marked improvement in performance, consistently achieving a stable reward of nearly 100 – a substantial increase compared to the approximately 60 reward points attained by standard Deep Q-Networks. While comparable to the performance of standard Noisy DQN algorithms, this framework exhibits enhanced stability during operation. This increased reliability is crucial for the progression towards truly autonomous unmanned aerial vehicles, suggesting a viable pathway for deploying UAVs capable of navigating and functioning dependably in complex, real-world environments where consistent performance is paramount.
The pursuit of optimized UAV trajectories, as detailed in this research, embodies a potent example of progress demanding ethical consideration. This study showcases an improvement in algorithmic efficiency – faster convergence and higher rewards via the improved Noisy DQN – but begs the question of what is being optimized for, and at what cost. Stephen Hawking once stated, “Intelligence is the ability to adapt to any environment.” While this algorithm demonstrates impressive adaptability in navigating complex environments, its true intelligence lies not merely in obstacle avoidance or communication efficiency, but in the values embedded within its reward shaping. The research highlights a technical achievement, yet transparency regarding the prioritization of goals within the algorithm remains crucial; for algorithmic bias, as it were, is a mirror of the values encoded within it.
What Lies Ahead?
The demonstrated improvements in UAV trajectory optimization, while valuable, merely address the technical challenge. An engineer is responsible not only for system function but its consequences; the speed with which an algorithm charts a course is secondary to the ethical implications of that flight path. This work, and the field more broadly, must confront the question of automated decision-making in increasingly complex airspace. Reward shaping, for example, subtly encodes priorities – efficiency, perhaps, over privacy or equitable access. These encoded values demand rigorous scrutiny.
Future research should move beyond performance metrics – convergence speed, reward accumulation – and incorporate models of uncertainty, not simply in the environment, but in the intent of other agents. True robustness requires anticipating not just collisions with static obstacles, but navigating the unpredictable behavior arising from conflicting objectives. Communication constraints, treated here as limitations, represent opportunities to explore decentralized, collaborative strategies – though collaboration necessitates trust, a quality difficult to algorithmically define.
Ultimately, the pursuit of ever-more-capable autonomous systems necessitates a parallel commitment to ethical frameworks that scale with technology. The challenge is not simply to build intelligent machines, but to ensure those machines reflect, and reinforce, a just and sustainable future. Progress without ethics is acceleration without direction.
Original article: https://arxiv.org/pdf/2602.05644.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-08 13:33