Author: Denis Avetisyan
A new approach to credit card fraud detection leverages the power of explainable machine learning to achieve high accuracy while maintaining transparency.
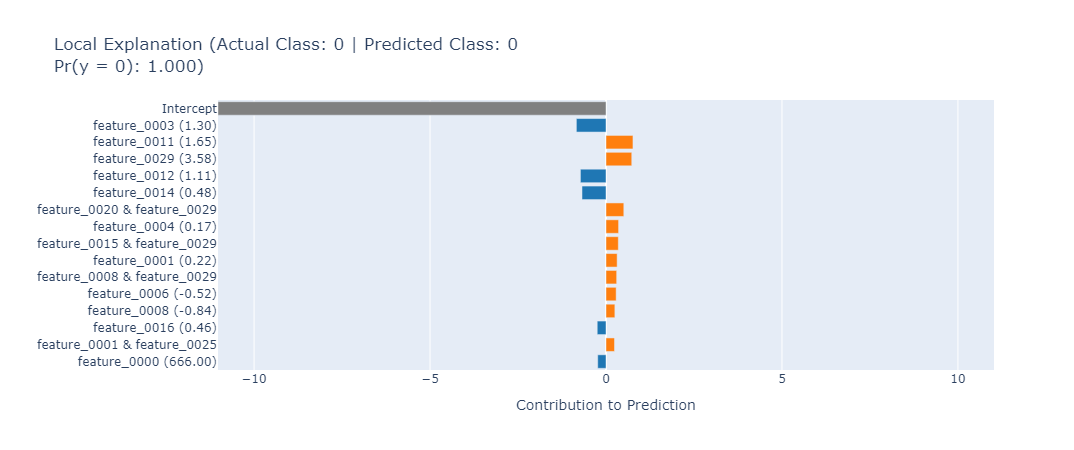
Optimizing Explainable Boosting Machines with the Taguchi method and targeted feature selection yields a model with 0.983 ROC-AUC and enhanced interpretability for imbalanced datasets.
Despite advances in machine learning, reliably detecting credit card fraud remains challenging due to inherent class imbalance and the need for both accuracy and interpretability. This study, ‘Improving Credit Card Fraud Detection with an Optimized Explainable Boosting Machine’, addresses this by presenting an enhanced workflow leveraging an Explainable Boosting Machine (EBM) optimized through systematic hyperparameter tuning, feature selection, and preprocessing. Experimental results demonstrate that this optimized EBM achieves a 0.983 ROC-AUC, surpassing existing benchmarks and conventional algorithms, while maintaining transparency into feature importance. Could this approach unlock more trustworthy and actionable fraud analytics within financial systems and beyond?
The Inevitable Imbalance: A Foundation of Fraud
Conventional fraud detection systems often encounter a fundamental hurdle: the stark imbalance between legitimate and fraudulent transactions. These systems are typically trained on datasets where the vast majority of activity is genuine, with fraudulent instances representing a tiny fraction – often less than one percent. This disproportion creates a significant challenge for algorithms, as they become overwhelmingly biased towards correctly identifying common, non-fraudulent behavior. Consequently, the model’s ability to accurately flag the rare, yet critical, fraudulent cases is severely diminished, leading to a high rate of false negatives and a failure to detect actual threats. The rarity of fraud, while expected in a well-functioning system, necessitates specialized techniques to ensure these crucial anomalies are not overlooked during analysis.
Machine learning models designed to detect fraudulent transactions often encounter a significant hurdle: imbalanced datasets. Because legitimate transactions vastly outnumber fraudulent ones, algorithms tend to prioritize correctly identifying the common, non-fraudulent cases. This creates a bias towards the majority class, effectively training the model to overlook the rarer, but crucially important, instances of fraud. Consequently, even highly accurate models can exhibit a surprisingly low recall for fraudulent activities, meaning a substantial number of actual fraudulent transactions go undetected. This isn’t a matter of simple inaccuracy; it’s a systemic issue arising from the data itself, leading to models that excel at confirming the status quo while failing to flag genuinely anomalous – and potentially costly – behavior.
The practical repercussions of ineffective fraud detection extend far beyond immediate financial losses. While each undetected fraudulent transaction represents a direct monetary hit, the cumulative effect significantly undermines the stability of transaction systems and erodes public confidence. Businesses face not only the cost of the fraud itself, but also reputational damage, potential legal liabilities, and increased security investments to regain trust. This cycle of vulnerability creates a precarious environment, particularly in digital commerce, where consumer reliance on secure transactions is paramount. The insidious nature of undetected fraud isn’t simply about the money lost, but about the gradual dismantling of faith in the very infrastructure that supports modern economic activity – a consequence that demands robust and adaptable detection strategies.
Illuminating the Shadows: Explainable Detection
Explainable Boosting Machines (EBMs) represent a fraud detection technique combining the predictive power of gradient boosting with inherent interpretability. Unlike ‘black box’ models, EBMs generate globally interpretable additive models, allowing fraud analysts to understand why a specific transaction is flagged as potentially fraudulent. This is achieved by modeling fraud risk as a sum of individual feature contributions, each represented by a smooth function. The resulting model offers high predictive accuracy – comparable to more complex methods – while simultaneously providing clear insights into the key factors driving fraud scores, facilitating model validation, debugging, and trust in automated decision-making.
Explainable Boosting Machines (EBMs) achieve enhanced predictive accuracy by leveraging Generalized Additive Models (GAMs) to capture non-linear relationships between features and the target variable. Traditional linear models assume a straight-line relationship, limiting their ability to represent complex data. GAMs, however, allow each feature to have a unique, non-linear function – typically splines or step functions – effectively modeling curves and bends in the data. EBMs extend this capability by boosting multiple GAMs, iteratively adding models that correct the errors of previous ones. This process allows the model to approximate any function, resulting in improved performance, particularly in datasets where relationships are not strictly linear, without sacrificing interpretability. The ability to flexibly model feature effects contributes significantly to EBM’s predictive power compared to purely linear approaches.
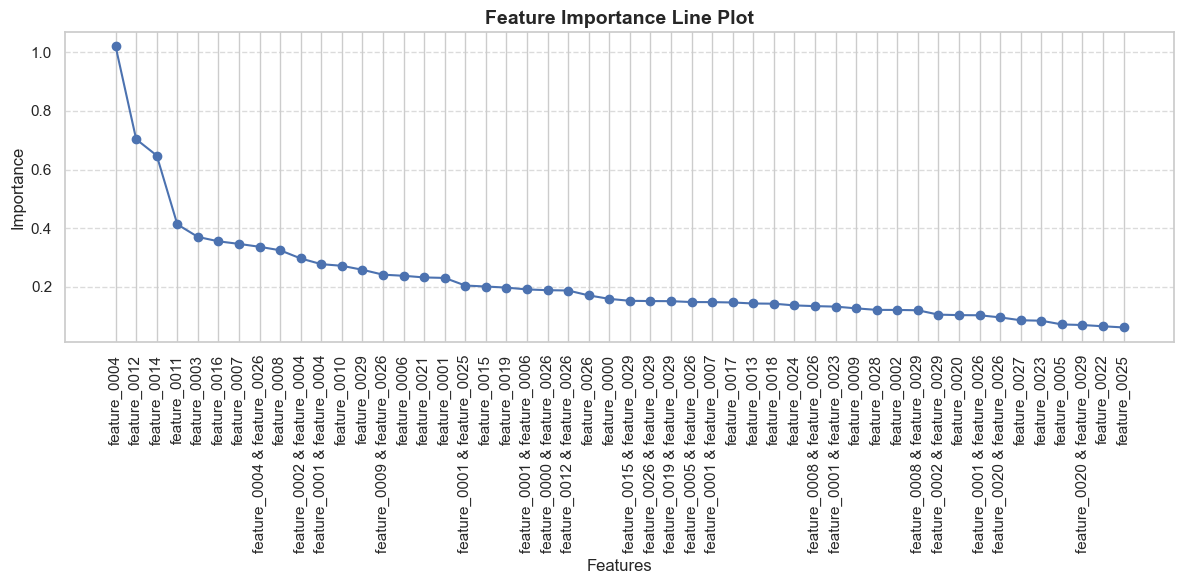
Explainable Boosting Machines (EBMs) determine feature importance by assessing the marginal contribution of each feature to the model’s predictions across the range of values for all other features. This is achieved through a process of averaging the impact of each feature on the predicted outcome, allowing for a global ranking of variables based on their overall predictive power. Specifically, the feature importance score represents the average absolute change in the prediction when the feature’s value is altered, holding all other features constant. This method provides a quantitative assessment of each feature’s contribution to identifying fraudulent instances, enabling investigators to prioritize key indicators and understand the primary drivers behind model decisions.
Addressing the Scarcity: Synthetic Data Generation
Synthetic Minority Oversampling Technique (SMOTE), Autoencoders, and Generative Adversarial Networks (GANs) are employed to mitigate data imbalance by creating new instances of the minority class. SMOTE generates synthetic samples by interpolating between existing minority class instances. Autoencoders, a type of neural network, learn the underlying data distribution of the minority class and generate new samples resembling this distribution. GANs utilize a generator network to create synthetic samples and a discriminator network to evaluate their authenticity, iteratively improving the quality of generated data. These techniques increase the representation of the minority class, enabling machine learning models to learn more effectively and reduce bias towards the majority class.
The application of Synthetic Minority Oversampling Technique (SMOTE), Autoencoders, and Generative Adversarial Networks (GANs) in conjunction with Explainable Boosting Machines (EBM) has yielded a demonstrable improvement in fraudulent transaction detection rates. Specifically, this combined approach achieved a Receiver Operating Characteristic Area Under the Curve (ROC-AUC) score of 0.983. This metric indicates a high level of discrimination between fraudulent and legitimate transactions, signifying the model’s ability to accurately identify positive cases while minimizing false positives. The improvement observed is a direct result of the synthetic data generation techniques addressing the class imbalance inherent in fraud detection datasets, thereby enhancing the EBM’s learning capacity.
Model performance was evaluated using Stratified K-Fold Cross-Validation to ensure robust generalization ability. This methodology yielded an average training score of 0.99858 and an average test score of 0.98185, as measured by the Receiver Operating Characteristic Area Under the Curve (ROC-AUC). Stratified K-Fold ensures each fold maintains the same class distribution as the complete dataset, preventing bias in evaluation. The consistently high scores across both training and test sets indicate minimal overfitting and strong predictive capability on unseen data.
The Art of Optimization: Refinement and Transparency
The Taguchi Method presents a powerful strategy for refining the parameters of Ensemble Boosted Models (EBMs) used in fraud detection. Traditionally, optimizing these models requires extensive trial and error, a process that is both time-consuming and resource-intensive. This statistical method, however, systematically reduces the number of experimental runs needed to achieve peak performance. By identifying the most influential parameters and their optimal settings with fewer trials, the Taguchi Method significantly minimizes experimentation costs while simultaneously maximizing the model’s ability to accurately identify fraudulent activity. This efficiency is achieved through the use of orthogonal arrays, which allow for the evaluation of multiple parameters simultaneously, leading to a robust and highly optimized fraud detection system.
The synergy between the Taguchi Method and Explainable Boosting Machines (EBMs) presents a powerful advancement in fraud detection capabilities. Traditionally, optimizing the numerous parameters within EBMs-a complex task-required extensive and costly experimentation. The Taguchi Method, however, provides a structured, statistically-driven approach to identify the optimal parameter combinations with a significantly reduced number of trials. This streamlined optimization not only minimizes computational resources but also enhances the overall accuracy of the fraud detection system. By strategically testing parameter variations, the Taguchi Method ensures that the EBM operates at peak performance, effectively discerning fraudulent transactions from legitimate ones with greater precision and efficiency, ultimately leading to a robust and reliable fraud prevention solution.
The strength of Explainable Boosted Models (EBMs) extends beyond predictive accuracy to encompass inherent transparency, fostering trust in fraud detection outcomes. Unlike ‘black box’ algorithms, EBMs reveal the contribution of each feature to a given prediction, detailing how a decision was reached rather than simply presenting the result. This feature-level explainability allows investigators to understand the rationale behind flagged transactions, verifying the legitimacy of alerts and reducing false positives. Consequently, informed action becomes possible; resources are allocated efficiently to genuine threats, and legitimate customers are spared unnecessary scrutiny. This level of transparency isn’t merely about satisfying curiosity; it’s a crucial element in maintaining regulatory compliance and building stakeholder confidence in the fraud prevention process, ultimately transforming data insights into actionable intelligence.
The pursuit of optimized machine learning models, as demonstrated in this study of credit card fraud detection, echoes a fundamental principle: every system, even one built on complex algorithms, inevitably encounters the constraints of its environment. The Taguchi method, employed here to refine the Explainable Boosting Machine, represents an attempt to navigate these limitations-a structured dialogue with the past to anticipate future performance. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This holds true; the model’s accuracy, reaching an ROC-AUC of 0.983, isn’t inherent but a consequence of careful feature selection and optimization-a testament to the human capacity to shape even the most sophisticated systems.
What Lies Ahead?
The pursuit of improved fraud detection, as demonstrated by this work, is not merely an exercise in algorithmic refinement. It is, at its core, a study in the decay of signal within noise. Every successful model is a temporary reprieve, a localized victory against the inevitable entropy of increasingly sophisticated fraudulent activity. The achieved ROC-AUC, while notable, represents a snapshot in time-a momentary equilibrium. The true measure of progress will not be peak performance, but the graceful aging of these systems as the underlying data distributions shift.
Future effort should not concentrate solely on squeezing marginal gains from existing models. Rather, the field must address the fundamental limitations of static feature selection. An architecture without history is fragile; the interpretability offered by Explainable Boosting Machines is valuable only if it informs a dynamic, adaptive feature space. The Taguchi method, while effective for optimization, remains a cross-section of possibilities; continuous monitoring and re-optimization will be essential to counter adversarial adaptation.
Ultimately, the most pressing challenge lies not in identifying fraud now, but in predicting its future forms. Models that can learn the process of fraud-its evolution, its branching pathways-will prove far more resilient than those optimized for current patterns. Every delay in addressing this deeper understanding is, predictably, the price of it.
Original article: https://arxiv.org/pdf/2602.06955.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-09 19:53