Author: Denis Avetisyan
A new framework optimizes the performance of AI agents by allowing them to dynamically switch between complex and streamlined models, significantly reducing computational costs.
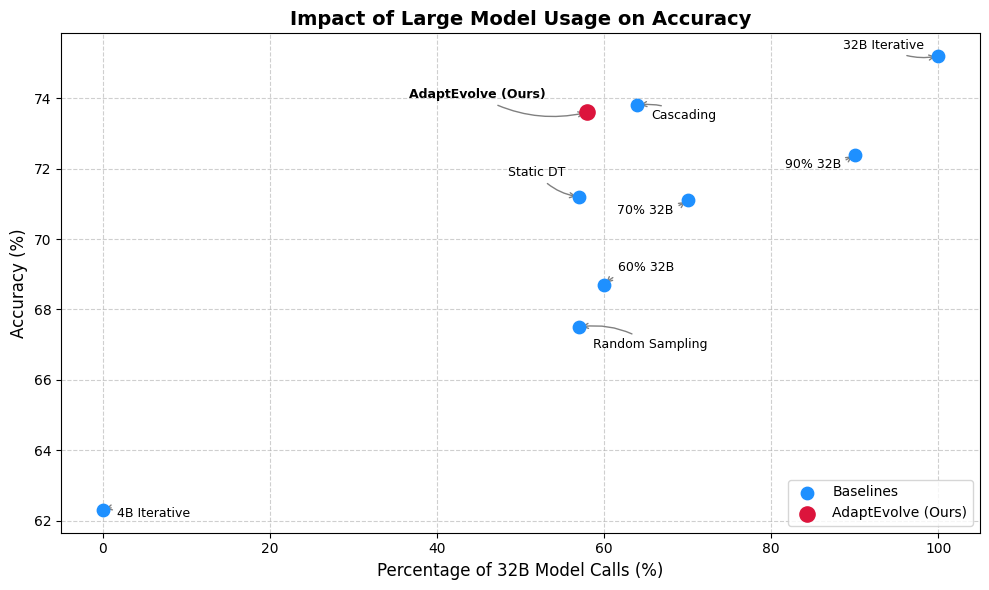
AdaptEvolve leverages uncertainty quantification to enable adaptive model selection in evolutionary AI, improving efficiency without sacrificing performance.
Balancing computational efficiency with reasoning capability remains a central challenge in increasingly complex agentic systems. The work presented in ‘AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection’ addresses this by introducing a novel framework for dynamically selecting between large language models during evolutionary refinement. AdaptEvolve leverages intrinsic confidence metrics to estimate real-time solvability, achieving a 37.9% reduction in inference cost while maintaining 97.5% of the accuracy of static, larger models. Could this adaptive approach unlock more scalable and resource-efficient AI agents capable of tackling even more demanding tasks?
The Inevitable Cost of Scale
Despite the remarkable abilities of large language models in generating human-quality text and performing various language-based tasks, a significant challenge lies in achieving true reasoning depth alongside cost-effectiveness. Current models, often characterized by sheer scale, exhibit a tendency towards computational inefficiency; static, fully-deployed large models can consume up to 30% more compute than necessary for sustained operation. This stems from the fact that every parameter within these enormous networks is constantly active, regardless of its relevance to a specific input or task. Consequently, even relatively simple queries can demand substantial processing power, hindering widespread accessibility and practical deployment, and prompting researchers to explore more nuanced architectural designs and adaptive computation strategies.
The relentless pursuit of larger language models is encountering a fundamental limit: diminishing returns. While increasing the size of transformer networks initially improves performance, subsequent scaling delivers progressively smaller gains, accompanied by exponentially rising computational costs. This inefficiency is prompting a critical re-evaluation of model architecture, with researchers actively exploring designs that prioritize computational frugality. Emerging alternatives promise substantial reductions in inference compute – the resources required to use a trained model – with some approaches demonstrating the potential to decrease these costs by as much as 37.9%. This shift signifies a move beyond simply ‘bigger is better’ towards intelligently engineered models that achieve comparable – or even superior – performance with significantly less energy and processing power.
Current methodologies in large language model processing frequently apply uniform computational resources to every input, a practice that overlooks the inherent variability in task difficulty. This approach is demonstrably inefficient, as simpler prompts require significantly less processing power than those demanding complex reasoning or nuanced responses. Recent research indicates a substantial opportunity to optimize performance by dynamically allocating resources – dedicating more compute to challenging inputs while conserving it for easier ones. This selective allocation doesn’t merely reduce computational cost; it also has the potential to improve overall system responsiveness and throughput, paving the way for more sustainable and scalable artificial intelligence systems. The principle resembles a skilled workforce – assigning more experienced personnel to intricate problems and allowing less-trained individuals to handle routine tasks, thereby maximizing collective efficiency.

Shifting the Burden: Multi-Model Inference
Multi-Model Inference represents a departure from traditional single-model deployment strategies by utilizing a combination of models with varying computational costs and capabilities. This approach directly addresses the inherent trade-off between inference quality and resource expenditure. Instead of relying on a single, often large, model for all inputs, Multi-Model Inference dynamically selects or combines outputs from multiple models – ranging from smaller, faster models optimized for efficiency to larger, more complex models prioritizing accuracy – based on input characteristics or pre-defined criteria. This allows for optimized resource allocation, enabling higher throughput and reduced latency while maintaining acceptable levels of performance, and ultimately lowering the total cost of inference.
The AdaptEvolve framework implements dynamic request routing between two language models – Qwen3-4B, prioritized for computational efficiency, and Qwen3-32B, selected for superior performance on complex tasks. This routing strategy optimizes resource allocation by directing simpler inputs to the 4B parameter model and more challenging inputs to the 32B parameter model. Benchmarking demonstrates that this adaptive approach results in a 37.9% reduction in total inference compute requirements compared to utilizing a single model for all inputs, offering a substantial improvement in cost-effectiveness without sacrificing overall performance.
Input routing within AdaptEvolve is governed by a Decision Tree classifier, trained on a dataset of input examples to predict processing difficulty. This tree operates by evaluating input features and branching accordingly to assign each request to either the Qwen3-4B or Qwen3-32B model. The training process optimizes the tree to minimize computational cost while maintaining acceptable performance levels, effectively mirroring the selective processing observed in biological systems where resources are allocated dynamically based on task complexity. The Decision Tree’s structure allows for rapid evaluation and dispatch, reducing latency compared to more complex routing mechanisms.
Trusting the Signals: Confidence and Uncertainty
AdaptEvolve utilizes internal model signals, specifically Token Confidence scores, to assess the complexity of incoming inputs and dynamically select appropriate computational pathways. These confidence scores, generated as part of the model’s standard operation, reflect the model’s certainty regarding each token in the input sequence; lower scores indicate higher uncertainty and potentially greater difficulty. This intrinsic uncertainty information is then used to route inputs to different models or processing stages, allowing for a trade-off between computational cost and prediction accuracy. By evaluating input difficulty on a token-by-token basis, AdaptEvolve avoids relying on external labels or pre-defined difficulty metrics, enabling a more flexible and responsive routing strategy.
AdaptEvolve utilizes a multi-faceted approach to quantifying model uncertainty through four distinct confidence metrics. Mean Confidence provides an average confidence score across all input tokens. Tail Confidence focuses on the lowest confidence scores, identifying potentially problematic tokens. Lowest Group Confidence assesses the minimum confidence within defined groups of tokens, useful for identifying localized areas of uncertainty. Finally, Bottom-K% Confidence calculates the confidence threshold below which the lowest K percent of tokens fall, offering a configurable sensitivity to low-confidence predictions; these metrics collectively provide a comprehensive assessment of input difficulty beyond a single aggregate score.
The AdaptEvolve Decision Tree is trained using a Pareto Efficiency optimization strategy, which simultaneously considers both inference cost and prediction accuracy during model selection. This approach enables the system to dynamically choose between models, prioritizing performance where necessary but reducing computational expense when possible. Empirical results demonstrate that this strategy achieves a balance between cost and accuracy, retaining 97.5% of the performance achievable with a static, high-capacity large language model acting as the upper-bound baseline. This near-equivalence is accomplished while potentially reducing computational demands through intelligent model routing.
The Algorithm Evolves
AdaptEvolve leverages the established OpenEvolve framework to facilitate the online adaptation of a Decision Tree-based router. OpenEvolve provides the core infrastructure for evolutionary computation, including mechanisms for population management, mutation, and selection. AdaptEvolve integrates this with a Decision Tree structure, allowing the router’s decision-making logic to be dynamically modified during operation. This contrasts with static routing configurations and enables the system to respond to changes in network conditions or application requirements without requiring manual intervention or system restarts. The framework supports continuous learning by evaluating router performance and iteratively refining the Decision Tree based on observed data.
A Hoeffding Adaptive Tree (HAT) represents an extension of the standard Decision Tree algorithm designed for continuous learning in dynamic environments. Unlike static Decision Trees built on a fixed dataset, the HAT incrementally updates its structure based on incoming data streams. This is achieved through the Hoeffding tree algorithm, which utilizes the Hoeffding bound to statistically determine when to split nodes, minimizing the need for complete retraining with each new data point. Specifically, the algorithm monitors the error rate of each potential split and only performs the split if the observed difference in error rates exceeds a predefined threshold, ensuring adaptation to non-stationary data distributions without requiring storage of the entire historical dataset.
The dynamic routing strategy implemented within AdaptEvolve facilitates Agentic Reasoning by optimizing the iterative process of solution refinement. Candidate solutions are generated, subjected to mutation – introducing variations to explore the solution space – and then selected based on performance metrics. This process is accelerated through the online adaptation of the Decision Tree router, which efficiently directs traffic to the most promising candidate solutions based on real-time evaluation. By minimizing the latency associated with evaluating and iterating through potential solutions, the system can more rapidly converge on optimal or near-optimal results, thereby enhancing the overall efficiency of the Agentic Reasoning process.
Practical Gains and Future Directions
Rigorous evaluation of AdaptEvolve on the LiveCodeBench and MBPP datasets reveals substantial gains in computational efficiency without compromising performance. The framework achieved a remarkable 41.5% reduction in inference compute requirements on MBPP, signifying a considerable decrease in resource utilization. Importantly, this optimization did not come at the expense of accuracy; AdaptEvolve maintained 97.1% of the peak accuracy achieved by larger, more computationally expensive models. These results demonstrate AdaptEvolve’s capacity to deliver both cost savings and reliable performance, positioning it as a promising solution for resource-constrained environments and complex reasoning tasks.
AdaptEvolve introduces an adaptive routing strategy that dynamically navigates the inherent trade-off between computational cost and inference speed, resulting in a substantial efficiency gain. When tested on the MBPP benchmark, the framework achieved an efficiency score of 132.3, a figure that nearly doubles the 79.7 recorded by a standard, non-adaptive large language model. This improvement stems from the system’s ability to intelligently select the appropriate level of model complexity for each input, avoiding unnecessary computation without compromising performance; the framework prioritizes faster processing for simpler tasks and leverages the full capacity of the model only when needed, creating a more streamlined and resource-conscious approach to complex reasoning.
Refinements to AdaptEvolve’s decision tree component yielded a notable 2.4% increase in accuracy when tested on the LiveCodeBench dataset, demonstrating the framework’s capacity for iterative improvement. Current research endeavors are directed towards implementing more nuanced confidence metrics, aiming to enhance the reliability of AdaptEvolve’s adaptive routing strategy. Beyond LiveCodeBench and MBPP, future development will prioritize extending the framework’s capabilities to tackle a broader spectrum of complex reasoning tasks, potentially unlocking significant gains in efficiency and performance across diverse applications that demand both speed and accuracy in problem-solving.
The pursuit of efficient AI, as demonstrated by AdaptEvolve’s dynamic model selection, feels predictably cyclical. This framework, intelligently switching between small and large language models based on uncertainty, is merely a sophisticated iteration of resource management techniques engineers have employed for decades. It’s a clever application of uncertainty quantification, certainly, but one destined to be superseded. As Bertrand Russell observed, “The difficulty lies not so much in developing new ideas as in escaping from old ones.” AdaptEvolve elegantly addresses computational cost-a perennial concern-but one anticipates a future where even ‘efficient’ models become tomorrow’s bottlenecks, replaced by yet another ‘revolutionary’ architecture with, inevitably, worse documentation.
What’s Next?
AdaptEvolve, predictably, solves one problem by introducing several more. The framework shifts computational burden from raw inference to the maintenance of uncertainty metrics and model selection policies. This feels less like progress and more like a tax on optimization. The question isn’t merely whether dynamic model selection improves efficiency, but whether the overhead of knowing when to simplify outweighs the savings. Future work will undoubtedly focus on automating that very meta-optimization, leading to layers of abstraction designed to hide ever-increasing complexity. Anything that promises to simplify life adds another layer of abstraction.
The reliance on intrinsic uncertainty as a proxy for task difficulty feels… optimistic. Production environments rarely align with the neatly defined distributions of research benchmarks. The real challenge lies in gracefully handling unforeseen inputs, edge cases, and the inevitable adversarial examples designed to exploit any heuristic. The system’s robustness will be tested not by achieving peak efficiency on ideal data, but by its failure modes when faced with the messy realities of deployment. CI is the temple – one prays nothing breaks.
Ultimately, AdaptEvolve exemplifies a familiar pattern: a clever solution to a narrowly defined problem, poised to become tomorrow’s tech debt. The pursuit of “efficient” agents risks prioritizing algorithmic elegance over practical considerations. Documentation is a myth invented by managers. The long-term trajectory likely involves increasingly sophisticated methods for managing the complexity of these systems, perpetually chasing diminishing returns in a quest for unattainable “general” intelligence.
Original article: https://arxiv.org/pdf/2602.11931.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-02-14 02:41