Author: Denis Avetisyan
A new framework leverages intelligent search and collaborative agents to dramatically improve the efficiency of gathering training data for automating tasks on mobile devices.
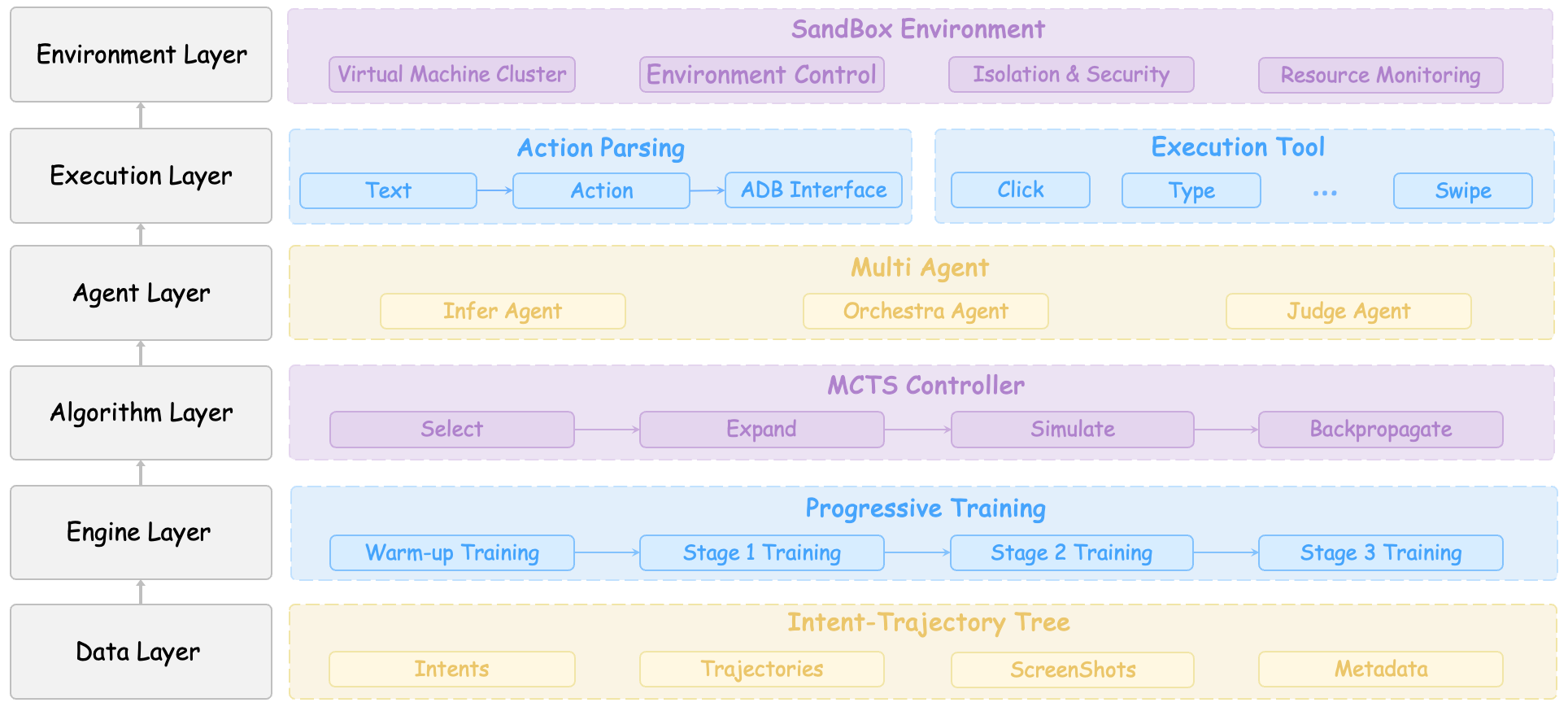
M2-Miner combines Monte Carlo Tree Search and multi-agent systems to optimize data mining for GUI automation, achieving state-of-the-art performance and reduced costs.
Constructing robust graphical user interface (GUI) agents requires extensive, high-quality training data, yet current annotation methods are costly and often yield limited results. To address this challenge, we present ‘M$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining’, an automated framework leveraging Monte Carlo Tree Search and a collaborative multi-agent system to efficiently mine diverse and valuable user interaction trajectories. This approach not only reduces data collection costs but also demonstrably improves the performance of GUI agents on standard mobile benchmarks. Will this framework unlock new levels of automation and personalization in human-computer interaction?
The Fragility of Simulated Touch
Historically, automating interactions with mobile graphical user interfaces (GUIs) has demanded the painstaking creation of specific interaction sequences – essentially, meticulously planned paths for virtual ‘fingers’ to follow. This manual approach, while functional, presents significant hurdles; each new app or even a minor app update often necessitates a complete overhaul of these interaction trajectories. The process is not only exceptionally time-consuming for developers, requiring hours of precise scripting, but fundamentally lacks scalability. As mobile applications proliferate and become increasingly complex, the effort required to maintain and expand these manually crafted interactions quickly becomes unsustainable, hindering the widespread adoption of automated GUI testing and control.
While datasets such as AITZ and AndroidControl represent important initial steps in facilitating research on mobile GUI automation, they exhibit limitations in mirroring the nuances of genuine user behavior. These existing resources often focus on simplified interaction patterns or a restricted range of applications, failing to adequately capture the complexity introduced by varied user intents, diverse app designs, and the dynamic nature of mobile interfaces. The actions within these datasets may also lack the subtle variations – differing swipe speeds, slight positional inaccuracies, or exploratory gestures – that characterize human-computer interaction. Consequently, agents trained solely on these datasets often demonstrate limited generalization capabilities when confronted with the unpredictable and multifaceted interactions encountered in real-world mobile app usage, hindering the development of truly robust and adaptable automation solutions.
The limited availability of comprehensive mobile interaction data presents a significant obstacle to creating truly intelligent and adaptable GUI automation agents. Current approaches often falter when confronted with novel app layouts or user intents, highlighting a crucial need for more extensive training datasets. Without sufficient examples of diverse user behaviors and app functionalities, these agents struggle to generalize beyond the specific scenarios they were trained on, resulting in brittle automation that requires constant manual adjustments. This data scarcity effectively caps the potential of mobile GUI automation, preventing the development of systems capable of autonomously handling the intricate and ever-evolving landscape of modern mobile applications and user interfaces.
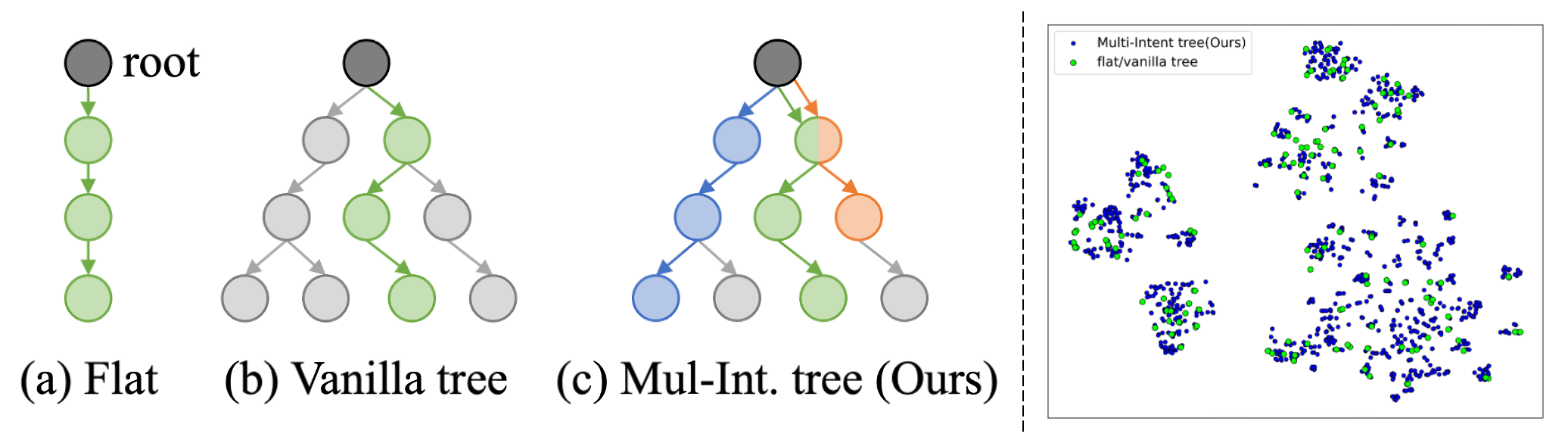
M2-Miner: Harvesting Interactions from the Machine
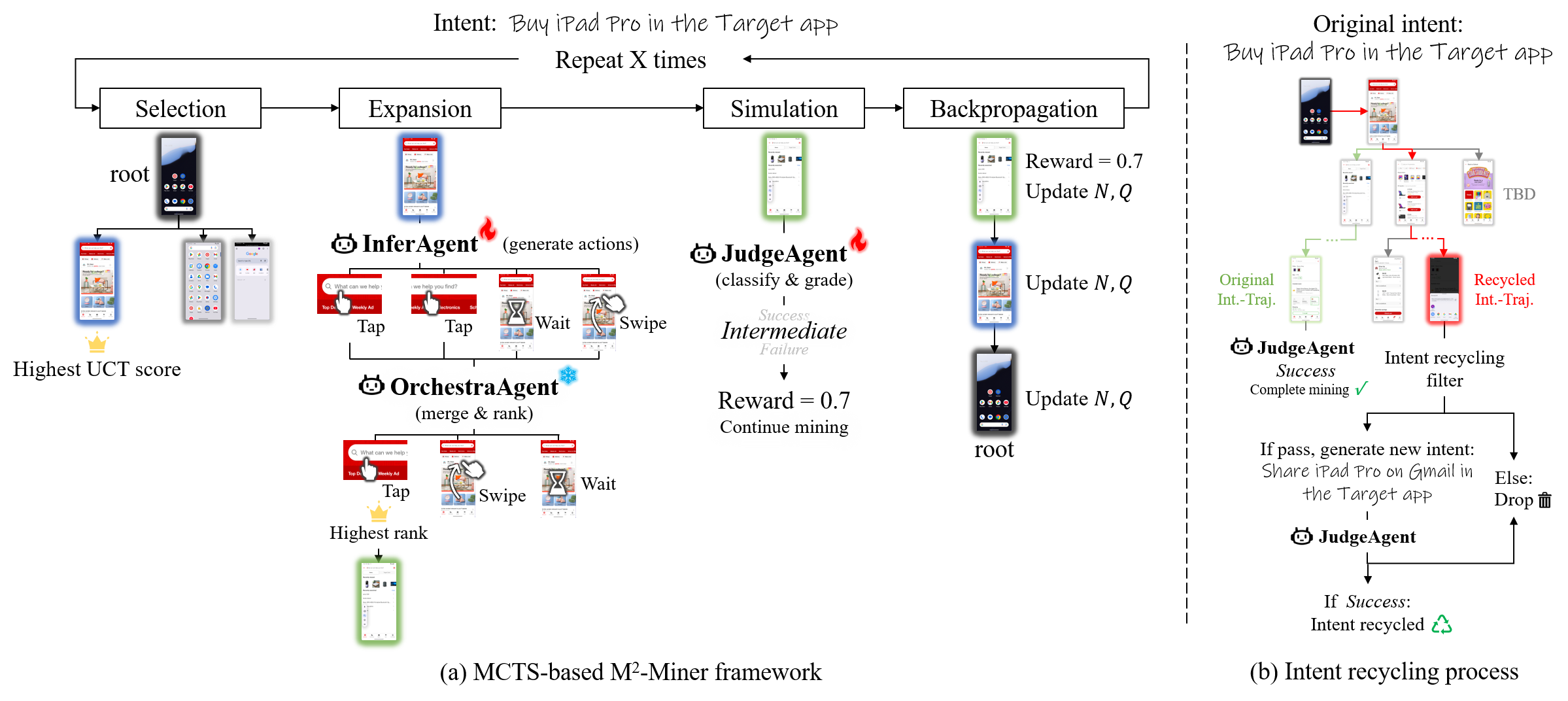
Monte Carlo Tree Search (MCTS) serves as the foundational algorithm within M2-Miner, addressing the challenge of efficiently navigating the extensive combinatorial space of potential interactions within mobile Graphical User Interfaces (GUIs). MCTS operates by constructing a search tree, iteratively expanding promising paths based on simulations. In the context of M2-Miner, each node in the tree represents a specific state of the mobile GUI, and edges represent possible user actions. The algorithm balances exploration – investigating less-traveled paths to discover potentially optimal sequences – with exploitation – focusing on paths that have previously yielded positive results. This probabilistic approach allows M2-Miner to systematically explore a large number of interaction sequences without exhaustively testing every possibility, making it suitable for automated data mining in complex mobile applications.
The Collaborative Multi-Agent Framework within M2-Miner is designed to optimize the Monte Carlo Tree Search (MCTS) algorithm during GUI automation. This framework consists of three distinct agents: InferAgent, which utilizes the Qwen2.5-VL large multimodal model to generate potential GUI interaction actions; OrchestraAgent, responsible for filtering and refining these proposed actions to ensure relevance and feasibility within the current application state; and JudgeAgent, which evaluates the outcomes of simulated actions during the MCTS simulation phase, providing feedback to guide the search process. By distributing the tasks of action proposal, refinement, and evaluation across these specialized agents, the framework significantly improves both the expansion and simulation stages of MCTS, enabling more efficient exploration of the GUI interaction space.
The InferAgent component within M2-Miner utilizes the Qwen2.5-VL large multimodal model to generate potential GUI interaction actions. These proposed actions are then passed to the OrchestraAgent, which performs refinement based on contextual relevance to the current state of the application under test. This collaborative process ensures that the Monte Carlo Tree Search (MCTS) algorithm explores a more focused and pertinent action space, improving the efficiency of automated GUI testing and data mining. The OrchestraAgent’s refinement stage filters and prioritizes actions, mitigating the impact of potentially irrelevant or redundant suggestions from the InferAgent.
Empirical Validation: Mining for Reliable Interactions
M2-Miner’s performance is quantitatively assessed using two primary metrics: Mining Success Ratio (MSR) and Data Quality Accuracy (DQA). MSR measures the proportion of initiated mining attempts that successfully generate complete, valid interaction trajectories. Data Quality Accuracy (DQA) represents the percentage of trajectories that adhere to predefined validity criteria, assessed through manual verification. High scores in both MSR and DQA indicate M2-Miner’s capability to consistently produce a large volume of usable interaction data, essential for training and evaluating reinforcement learning agents. These metrics collectively demonstrate the system’s effectiveness in automated data generation.
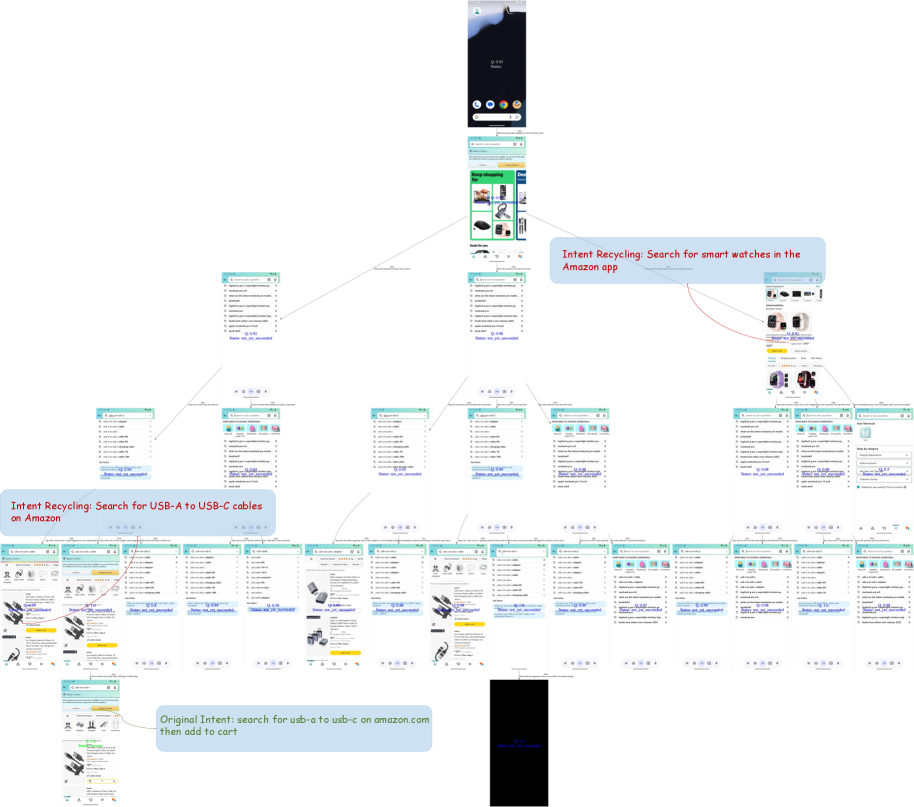
The Intent Recycling Strategy enhances data diversity within M2-Miner by systematically re-utilizing existing intent-trajectory trees. Rather than discarding trees after initial trajectory generation, the strategy identifies and extracts alternative, valid trajectories branching from the same intent node. This process effectively amplifies the number of unique trajectories generated from a given computational effort. By exploring multiple paths within established intent-trajectory trees, the strategy generates additional data points without requiring entirely new Monte Carlo Tree Search (MCTS) simulations, thereby increasing the overall diversity of the mined dataset.
M2-Miner demonstrates a 64x increase in data mining efficiency at a task length of 9 when contrasted with standard Monte Carlo Tree Search (MCTS). This efficiency gain translates directly into reduced data collection timelines. Furthermore, manual verification processes confirm that the interaction trajectories generated by M2-Miner exhibit a superior Data Quality Accuracy (DQA) compared to existing, publicly available datasets. This indicates not only a faster rate of data generation but also an improvement in the quality and validity of the mined data.
Broadening the Scope: Generalization and Economic Impact
M2-Miner exhibits robust performance across a spectrum of challenging mobile GUI automation benchmarks – including AndroidControl, AITZ, GUI Odyssey, and CAGUI – demonstrating a significant capacity for generalization. This adaptability stems from its automated data mining approach, allowing it to efficiently acquire diverse and representative training data. Successful navigation of these varied environments-from complex Android applications to visually rich GUI tasks-underscores the model’s ability to transcend the limitations of datasets tailored to specific applications. The consistent high performance across these benchmarks suggests M2-Miner isn’t simply memorizing solutions, but rather learning underlying principles of GUI interaction, making it a promising solution for broader mobile automation challenges.
M2-Miner exhibits exceptional performance in automated GUI control, achieving a remarkable 97.5% Step Success Rate (SR) on the challenging AndroidControl-High benchmark, surpassing the capabilities of existing methods. This success extends to the CAGUI dataset, where models trained using data mined by M2-Miner attain a 70.2% Step Success Rate, demonstrating the quality and usability of the generated training data. These results highlight M2-Miner’s ability to not only automate the data mining process, but also to facilitate the creation of highly effective GUI automation agents across diverse mobile platforms and applications.
The development of robust mobile GUI agents traditionally demands substantial investment in data collection and annotation; however, M2-Miner streamlines this process through automation, yielding significant reductions in both time and financial resources. By autonomously mining relevant data, the system alleviates the need for extensive manual inspection, resulting in a cost saving of $196. Furthermore, the computational efficiency of M2-Miner’s automated approach diminishes expenses related to data generation by $270. This culminates in a total cost reduction of $466 for dataset construction, demonstrating the potential for more accessible and efficient development of agents capable of interacting with mobile graphical user interfaces.
The pursuit of robust GUI automation, as detailed in this exploration of M$^2$-Miner, mirrors a natural system’s evolution. The framework doesn’t build automation agents so much as cultivate them through iterative refinement – a multi-agent system learning from experience. This resonates with the observation of Donald Davies: ‘Everything built will one day start fixing itself.’ The M$^2$-Miner’s capacity to optimize data collection and enhance agent training isn’t about imposing control, but facilitating a self-correcting cycle. The framework, much like a resilient ecosystem, anticipates and adapts to the inherent unpredictability of user interfaces, acknowledging that even the most meticulously planned system will inevitably require ongoing, emergent repair.
What Lies Ahead?
The pursuit of automated GUI interaction, as exemplified by M$^2$-Miner, inevitably bumps against the inherent unpredictability of user interfaces. This isn’t a limitation of the algorithm, but a consequence of building systems atop shifting sands. The framework efficiently navigates a known search space, yet each application update, each design iteration, redraws the map. A guarantee of continued performance is merely a contract with probability; the collected data, while valuable, possesses a half-life dictated by software evolution.
Future work will likely focus on meta-learning strategies-teaching the system how to learn new interfaces, rather than exhaustively mining each one. But even that is a temporary reprieve. Stability is merely an illusion that caches well. The true challenge isn’t minimizing data collection costs, but embracing the chaos. The framework isn’t a tool for control, but a sensor for adaptation.
The trajectory optimization and intent recognition components, while sophisticated, remain fundamentally reactive. The next iteration won’t be about finding the optimal path, but about anticipating the user’s next move-a move predicated on a logic that, by definition, remains opaque. Chaos isn’t failure-it’s nature’s syntax.
Original article: https://arxiv.org/pdf/2602.05429.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-08 17:02