Author: Denis Avetisyan
A new reinforcement learning approach optimizes web crawling to efficiently extract valuable statistical data from complex websites.
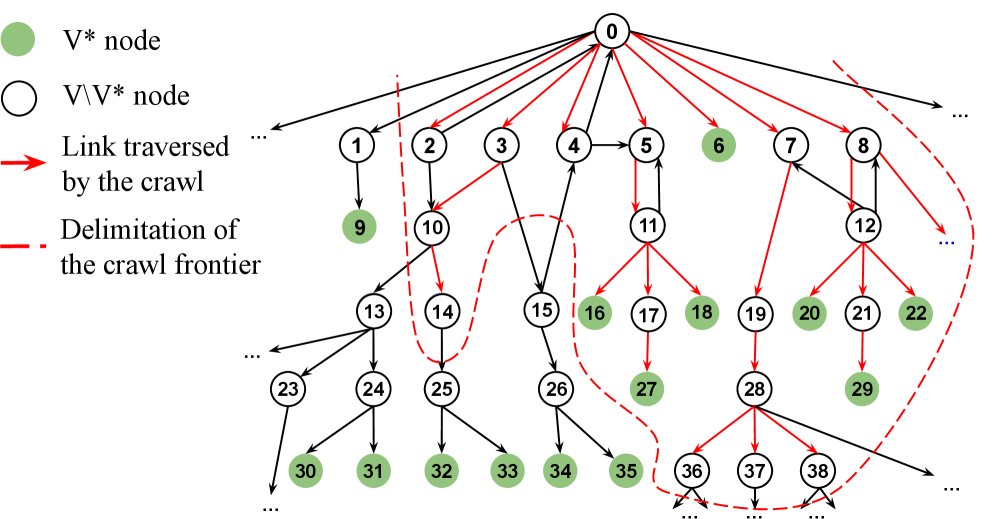
This paper introduces SB-CLASSIFIER, a web crawler that prioritizes tag paths using reinforcement learning to achieve superior scalability and data acquisition performance.
Acquiring comprehensive statistical datasets from the web is often hampered by the sheer scale and rapidly changing structure of online information. This paper, ‘Efficient Crawling for Scalable Web Data Acquisition (Extended Version)’, addresses this challenge with a novel web crawling algorithm, SB-CLASSIFIER, that leverages reinforcement learning to efficiently locate and retrieve target resources. By intelligently prioritizing hyperlink paths based on observed patterns, our approach demonstrably outperforms traditional methods while crawling a significantly smaller portion of a given website. Could this adaptive crawling strategy unlock broader access to crucial statistical data and accelerate data-driven research across diverse fields?
The Inevitable Expansion: Confronting Web-Scale Data Acquisition
The exponential growth of web content presents a formidable challenge to automated data collection efforts. While the internet offers an unprecedented wealth of information, its sheer scale-billions of webpages constantly being added, updated, and rearranged-overwhelms traditional crawling techniques. Simply attempting to index a significant portion of the web requires immense computational resources and network bandwidth. Moreover, the dynamic nature of websites, with content frequently changing or appearing behind JavaScript-rendered interfaces, necessitates increasingly sophisticated methods to ensure data accuracy and completeness. This constant expansion and evolution demand that automated collection systems move beyond brute-force approaches towards intelligent strategies capable of prioritizing relevant information and adapting to the ever-changing web landscape.
Conventional web crawling, while foundational to data acquisition, frequently encounters limitations when faced with the sheer scale and dynamic nature of the modern web. These methods typically operate by systematically traversing links from an initial set of seed URLs, a process that can quickly become inefficient as crawlers encounter irrelevant content, redundant pages, or dynamically generated websites. This broad-stroke approach consumes significant bandwidth, processing power, and storage, often yielding incomplete datasets filled with extraneous information. The resulting waste of resources hinders the ability to effectively monitor and analyze online data, necessitating more targeted and intelligent crawling strategies capable of prioritizing relevant information and adapting to the ever-changing web landscape.
Automated data acquisition increasingly demands approaches that surpass conventional web crawling techniques. Simply traversing links proves inefficient when seeking highly specific information amidst the vastness of the internet; such methods often retrieve irrelevant data, straining resources and hindering comprehensive analysis. Instead, intelligent strategies now prioritize targeted data discovery, employing techniques like semantic understanding of webpage content, machine learning to identify relevant patterns, and focused crawling guided by pre-defined data schemas. These advancements enable systems to pinpoint and extract precise data targets – be it product pricing, scientific literature, or social media trends – with significantly improved accuracy and reduced computational overhead, ultimately facilitating more effective knowledge discovery and data-driven insights.
SB-CLASSIFIER: A Crawler Forged in Adaptation
SB-CLASSIFIER is a web crawler engineered for the efficient retrieval of specified data from websites. Unlike traditional crawlers that rely on pre-defined rules or breadth-first search, SB-CLASSIFIER employs a dynamic approach to data acquisition. It is designed to target specific data points, minimizing unnecessary bandwidth consumption and processing time associated with indexing entire websites. The crawler’s architecture focuses on identifying and extracting only the information relevant to a given query or task, improving performance and scalability for large-scale data collection initiatives. This targeted approach distinguishes SB-CLASSIFIER from general-purpose web indexing bots.
SB-CLASSIFIER employs a reinforcement learning (RL) framework to optimize its web crawling process. The crawler operates by defining a state space representing the current website structure and a set of actions corresponding to navigational choices, such as following links or submitting forms. A reward function quantifies the value of accessing relevant data, guiding the RL agent to learn an optimal policy. This policy dynamically balances exploration – attempting new, potentially valuable paths – with exploitation – focusing on paths previously identified as high-reward. Through iterative learning, SB-CLASSIFIER adapts its crawling strategy based on observed rewards, maximizing the rate of relevant data acquisition and minimizing unnecessary requests. The RL agent utilizes techniques like Q-learning or policy gradients to refine its decision-making process and improve crawling efficiency over time.
SB-CLASSIFIER employs Tag Path Analysis to identify and navigate websites for targeted data. This process involves parsing the Document Object Model (DOM) of each webpage to construct paths representing the hierarchical relationships between HTML tags leading to desired data elements. The crawler then utilizes these tag paths as features in its reinforcement learning model, allowing it to prioritize exploration of website sections with high probabilities of containing relevant information. By learning the structural patterns associated with data locations, SB-CLASSIFIER minimizes unnecessary crawling and efficiently focuses on areas likely to yield valuable results, improving retrieval speed and reducing bandwidth consumption.
Refining the Search: Optimizing Crawling Performance and Efficiency
SB-CLASSIFIER incorporates an early stopping mechanism to improve crawling efficiency by automatically halting exploration of a website when the discovery rate of new target pages falls below a pre-defined threshold. This adaptive termination prevents the crawler from continuing to request pages with a diminishing probability of containing relevant content, thereby reducing unnecessary network requests and computational load. The threshold is a configurable parameter, allowing adjustment based on the characteristics of the target website and the desired balance between recall and efficiency. This feature is designed to address the common problem of crawlers getting trapped in “empty” portions of a website after exhausting readily available target content.
The SB-CLASSIFIER crawler incorporates a URL Classifier to improve efficiency by assessing the likelihood of a link containing target content before requesting the page. This pre-emptive analysis allows the crawler to prioritize links predicted to be relevant, focusing resources on promising paths. Simultaneously, the classifier filters out links deemed irrelevant, reducing the volume of unnecessary requests and minimizing wasted bandwidth. This selective approach significantly enhances crawling performance by concentrating efforts on potentially valuable content and avoiding unproductive exploration of the web graph.
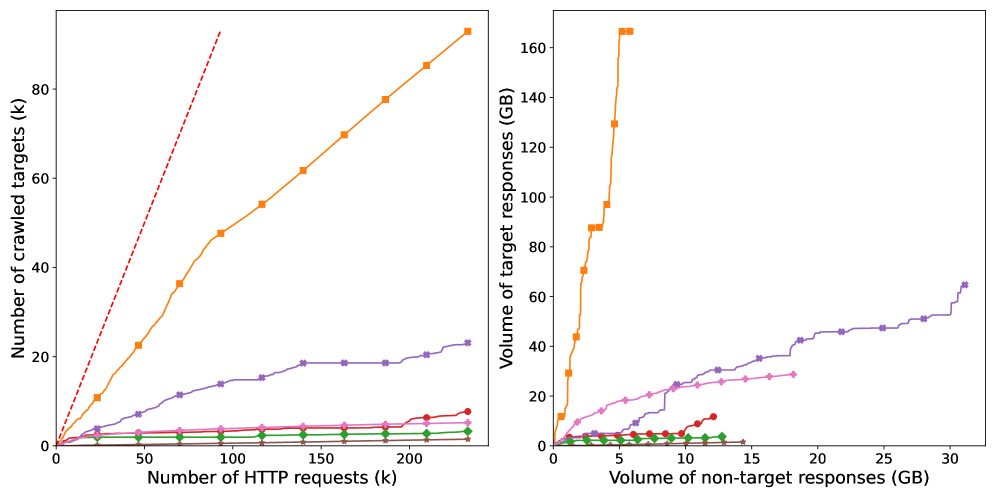
SB-CLASSIFIER demonstrates improved crawling efficiency compared to baseline and focused crawling methods. Specifically, testing reveals a statistically significant reduction in the total number of HTTP requests required to identify 90% of target pages; detailed comparative data is presented in Table 2. This performance advantage indicates SB-CLASSIFIER’s ability to more effectively prioritize and locate relevant content, minimizing wasted requests on irrelevant or already-indexed pages. The system consistently outperforms the FOCUSED crawler, highlighting the benefits of its classification-based approach to link selection.
SB-CLASSIFIER demonstrates a marked improvement in crawling efficiency by significantly reducing the volume of non-target pages visited during operation. Comparative analysis, detailed in Table 2, reveals that SB-CLASSIFIER retrieves fewer irrelevant pages than baseline crawlers while still achieving target discovery. This reduction in non-target page volume translates directly to decreased bandwidth consumption, reduced server load on the target website, and faster overall crawl times, indicating a more focused and efficient crawling process.
Unveiling Insights: Impact and Applications in Statistical Extraction
SB-CLASSIFIER streamlines the acquisition of Statistics Datasets, a capability increasingly vital for contemporary research and analytical endeavors. The system’s efficiency lies in its automated data collection, significantly reducing the time and resources previously required to compile comprehensive statistical resources. This facilitates data-driven investigations across diverse fields, from economic forecasting and public health monitoring to social science research and environmental modeling. By providing readily accessible and organized datasets, SB-CLASSIFIER empowers researchers to formulate more robust hypotheses, conduct more rigorous analyses, and ultimately, generate more impactful insights. The tool’s ability to efficiently gather these resources is poised to accelerate the pace of discovery and innovation in any discipline reliant on quantitative evidence.
The capacity to pinpoint and retrieve data presented in entity-centric tables represents a significant advancement in automated data collection. Unlike free-form text, these tables offer highly structured information, allowing for immediate computational analysis and integration into databases. SB-CLASSIFIER’s proficiency in extracting data from these formats bypasses the need for manual parsing or optical character recognition, dramatically accelerating the process of building statistical datasets. This capability is especially valuable in fields like economics, demographics, and public health, where data is frequently disseminated via tabular reports and online databases. By automating the extraction of structured data, the system enables researchers to focus on analysis and interpretation, fostering more efficient knowledge discovery and evidence-based decision-making.
The proliferation of openly accessible data sources, when coupled with the automated capabilities of SB-CLASSIFIER, is dramatically reshaping the landscape of data-driven research. Previously inaccessible or difficult-to-collect statistics are now readily available for large-scale analysis, fostering opportunities for knowledge discovery across diverse fields. This synergy allows researchers to move beyond limited datasets, enabling more comprehensive investigations and the identification of previously hidden trends. The ability to efficiently mine these open resources not only accelerates scientific progress but also empowers data-driven decision-making in areas such as public health, economics, and social science, ultimately promising a more informed and evidence-based approach to understanding complex phenomena.
SB-CLASSIFIER exhibits a demonstrable advantage in locating statistical datasets compared to conventional web crawlers, a benefit amplified when navigating the intricacies of complex websites. This enhanced retrieval rate isn’t simply about finding more data, but rather, consistently identifying and extracting it from sources that often present challenges to automated systems. The crawler’s architecture appears particularly adept at parsing dynamic content and overcoming anti-scraping measures, allowing it to successfully harvest data where baseline crawlers fail. This improved performance translates directly into more comprehensive datasets for researchers, accelerating data-driven discovery across numerous fields and providing a more robust foundation for statistical analysis.
Manual analysis reveals that SB-CLASSIFIER achieves a precision rate of 70 to 80 percent when identifying web pages containing statistical data. This level of accuracy suggests the system reliably distinguishes between pages likely to hold valuable datasets and those that do not, minimizing the retrieval of irrelevant content. While not perfect, this performance is considered reasonable, offering a strong foundation for automated data collection and reducing the manual effort required to curate statistics from the web. The observed precision indicates a practical tool for researchers and analysts seeking to efficiently locate and extract statistically relevant information, even within the vast and often unstructured landscape of the internet.
The pursuit of scalable web data acquisition, as demonstrated by SB-CLASSIER, inherently acknowledges the inevitable decay of any system built to navigate the ever-shifting landscape of the web. Each website represents a unique environment, subject to constant modification and eventual obsolescence. As Vinton Cerf observed, “The Internet is not just a network of networks, it’s a network of people.” This speaks to the dynamism inherent in the systems being crawled – they aren’t static repositories, but living, breathing entities shaped by human interaction. The reinforcement learning approach detailed in the paper attempts to build a crawler that can adapt to this decay, prioritizing tag paths not as fixed routes, but as pathways subject to constant change and requiring continuous reevaluation. The system’s efficiency isn’t merely about speed, but about gracefully aging within a fundamentally unstable medium.
What Lies Ahead?
The presented work, like all constructions, achieves a local minimum of entropy. SB-CLASSIER demonstrates a capacity for efficient data acquisition, yet efficiency is merely the postponement of inevitable saturation. The web is not static; its structure shifts, tag paths decay, and statistical data becomes historical artifact. Future iterations will undoubtedly face the challenge of maintaining relevance in a constantly evolving landscape – a Sisyphean task disguised as algorithmic refinement.
The reliance on tag paths, while currently effective, represents a fragility. Systems built upon surface features often fail when those features erode. A deeper understanding of semantic content, independent of presentation, may offer a more robust, though computationally intensive, solution. However, even semantic understanding is subject to the vagaries of language and the inherent ambiguity of meaning.
Ultimately, the pursuit of scalable data acquisition is not about conquering the web, but about charting its decline. Each successful crawl is a momentary stay against the universal tendency toward disorder. The true measure of progress may not be the volume of data collected, but the grace with which these systems adapt – or fail to adapt – as time inevitably takes its toll.
Original article: https://arxiv.org/pdf/2602.11874.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
2026-02-15 15:30