Author: Denis Avetisyan
Researchers have developed a compact language model that rivals larger systems in complex agent tasks, pushing the boundaries of edge intelligence.
![AgentCPM-Explore establishes a training framework wherein an agent iteratively refines its policy through exploration, leveraging a multi-stage process to maximize cumulative reward, formalized as <span class="katex-eq" data-katex-display="false"> \max_a \mathbb{E}_{\tau \sim p(\tau|a)} [R(\tau)] </span>, where τ represents a trajectory and <span class="katex-eq" data-katex-display="false"> R(\tau) </span> denotes the associated reward.](https://arxiv.org/html/2602.06485v1/x2.png)
AgentCPM-Explore leverages parameter-efficient techniques, reward denoising, and context refinement to achieve state-of-the-art performance with only 4 billion parameters.
Despite the promise of large language model (LLM)-based agents, realizing their full potential at the edge – with limited computational resources – remains a significant challenge. This paper introduces ‘AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents’ and presents a systematic investigation into training agentic models at the 4B-parameter scale, identifying and addressing key bottlenecks in catastrophic forgetting, reward signal noise, and long-context reasoning. Through parameter-space model fusion, reward denoising, and contextual refinement, AgentCPM-Explore achieves state-of-the-art performance comparable to, and even surpassing, much larger 8B+ parameter models. Does this work demonstrate that inference stability, rather than inherent capability, is the primary limiter for deploying powerful agents on edge devices?
The Limits of Conventional Reinforcement Learning
Conventional reinforcement learning (RL) systems, such as those employing the veRL framework, often encounter significant difficulties when tackling tasks that require foresight and strategic planning over extended periods. The core challenge lies in the ‘credit assignment’ problem – determining which actions, taken far in the past, ultimately contributed to a reward received much later. This becomes exponentially harder as the planning horizon increases, as the signal representing successful behavior weakens with each intervening step. Consequently, agents struggle to learn effective policies in scenarios demanding long-term dependencies, like intricate games or complex robotic manipulation, where immediate rewards are sparse and delayed gratification is the norm. The inability to effectively bridge the gap between action and distant consequence fundamentally limits the applicability of these systems to truly challenging, real-world problems.
The pursuit of increasingly intelligent agents reveals that simply increasing a model’s parameter count does not guarantee success in complex environments requiring long-term planning. Traditional approaches often falter when rewards are delayed and necessitate maintaining a coherent understanding of events unfolding over extended periods. AgentCPM-Explore offers a compelling solution by prioritizing robust contextual maintenance and efficient exploration strategies, enabling it to achieve state-of-the-art performance on challenging tasks. Remarkably, this is accomplished with a model size of only 4 billion parameters – a significant feat when compared to competing models requiring up to 30 billion parameters to reach similar levels of proficiency. This demonstrates that architectural innovation and strategic learning can yield substantial gains in capability, even with limited computational resources.
Architectural Efficiency: AgentCPM-Explore
AgentCPM-Explore is a 4 billion parameter agent model designed for operation in challenging, complex environments. This relatively small scale is achieved through engineering focused on maximizing capability density – the amount of functional ability packed into each parameter. The architecture prioritizes efficient execution, enabling effective performance with limited computational resources. This contrasts with larger models that rely on sheer scale for comparable results, and allows AgentCPM-Explore to be deployed in resource-constrained settings while maintaining a high level of functionality.
Parameter-space model merging, as implemented in AgentCPM-Explore, involves combining weights from multiple independently trained models into a single, unified model. This technique facilitates the acquisition of both broad, generalized capabilities and specific, specialized skills. Rather than relying on a single model to learn all tasks, distinct models are trained on diverse datasets or task distributions, and their parameters are then merged – typically through weighted averaging – to create a resultant model exhibiting a wider range of competencies. This approach improves performance by leveraging the strengths of each constituent model and mitigating the limitations inherent in single-model architectures, ultimately enhancing the agent’s adaptability and efficiency in complex environments.
AgentCPM-Explore utilizes asynchronous training methodologies to enhance both learning speed and sample efficiency. This approach allows for parallelized experience gathering and model updates, significantly reducing the time required to achieve optimal performance. Evaluations on the GAIA benchmark demonstrate that AgentCPM-Explore surpasses the performance of the WebDancer (QWQ-32B) model by 12.4 percentage points, indicating a substantial improvement in task completion and overall agent capability achieved through this training paradigm.
Mitigating Noise: Robust Reward Signal Processing
AgentCPM-Explore addresses the challenges posed by real-world environments through a dedicated reward signal denoising pipeline. This pipeline is designed to improve agent performance in scenarios where reward signals are either noisy or inaccurate due to imperfections in the environment or the reward function itself. By actively identifying and mitigating these spurious signals, the system enhances the reliability of the reinforcement learning process and enables more robust decision-making. The denoising process doesn’t attempt to correct inaccurate rewards, but rather to filter out signals that are demonstrably erroneous or irrelevant to the task at hand, thereby preventing the agent from learning suboptimal policies based on flawed data.
The AgentCPM-Explore system employs a multi-stage filtering pipeline to address inaccuracies in reward signals. Extreme trajectory filtering identifies and removes implausible or physically impossible agent paths that could generate erroneous rewards. Environmental noise filtering reduces the impact of stochasticity and irrelevant variations within the simulated environment. Finally, format error filtering corrects inconsistencies or invalid data structures in the reward signal itself, ensuring that the agent receives consistently interpretable feedback. This combined approach proactively mitigates spurious signals before they influence the agent’s learning process.
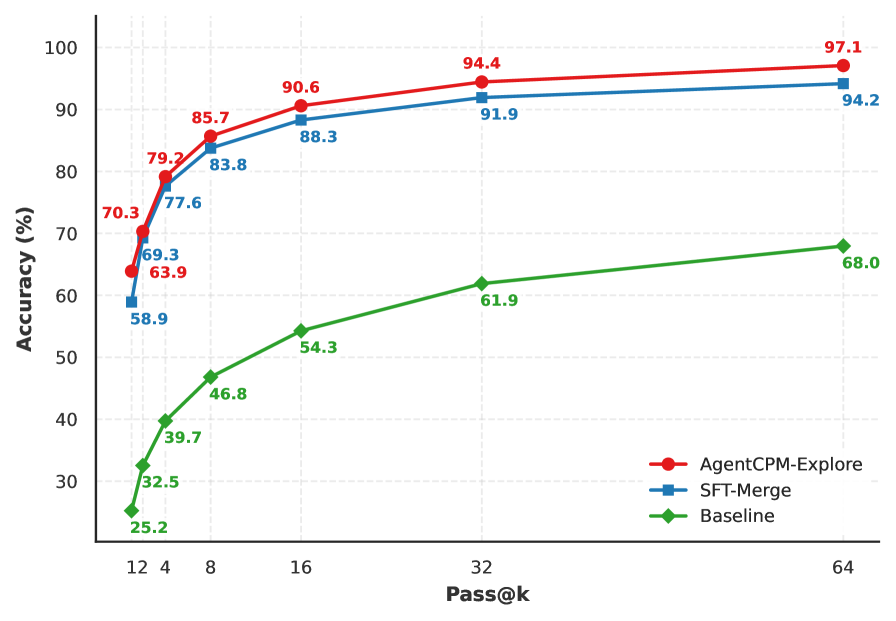
Context information refinement within AgentCPM-Explore focuses on improving the quality of input data to enhance the agent’s environmental understanding. This process directly contributes to a 97.09% accuracy rate on the GAIA benchmark, specifically when utilizing Pass@64 sampling. Pass@64 assesses an agent’s success rate by allowing 64 attempts to complete a task, providing a robust measure of performance despite potential individual failures. The refinement process prepares and structures environmental data, enabling the agent to more reliably interpret its surroundings and execute appropriate actions within the GAIA testing framework.
Operational Efficiency and Validation: A Holistic System
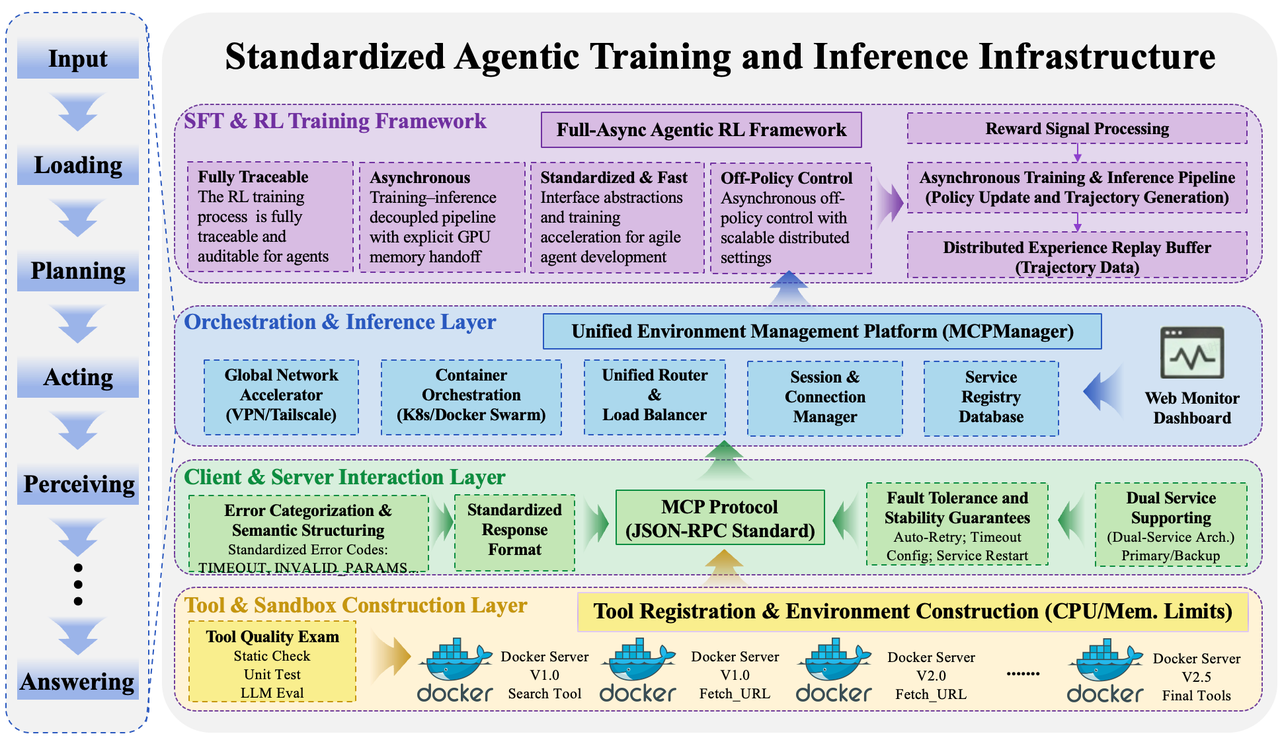
AgentCPM-Explore’s efficient deployment relies on AgentDock, a robust infrastructure designed to manage the complexities of container orchestration, request routing, and tool execution. This system streamlines the process of launching and scaling the agent, ensuring consistent performance across various computational environments. By automating these crucial operational aspects, AgentDock allows researchers and developers to focus on refining the agent’s core reasoning capabilities rather than grappling with infrastructure management. The unified routing capabilities intelligently direct requests to the appropriate tools, while container orchestration ensures optimal resource allocation, leading to a more stable and scalable deployment of AgentCPM-Explore for complex tasks.
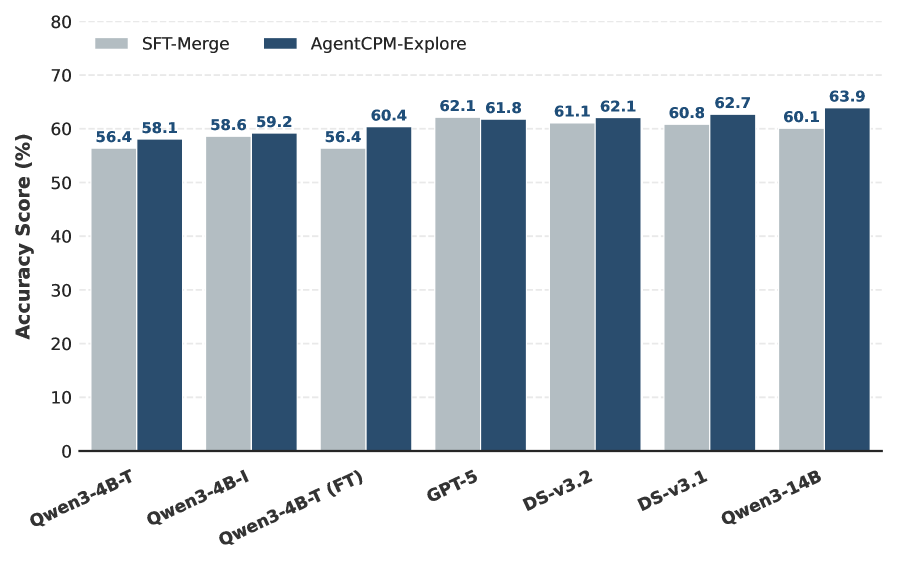
Rigorous evaluation of AgentCPM-Explore, conducted using the GAIA and HLE benchmarks, reveals its proficiency in tackling complex reasoning challenges that demand processing of extensive contextual information. Notably, the agent achieved an 82.7% success rate on the FRAMES benchmark, a demanding test of multi-step reasoning and knowledge integration. This performance demonstrably exceeds that of competing models, with AgentCPM-Explore surpassing ASearcher-32B by a significant 8.2 percentage points and outperforming IterResearch-30B by an even larger margin of 11.7 percentage points, highlighting its advanced capabilities in long-context understanding and problem-solving.
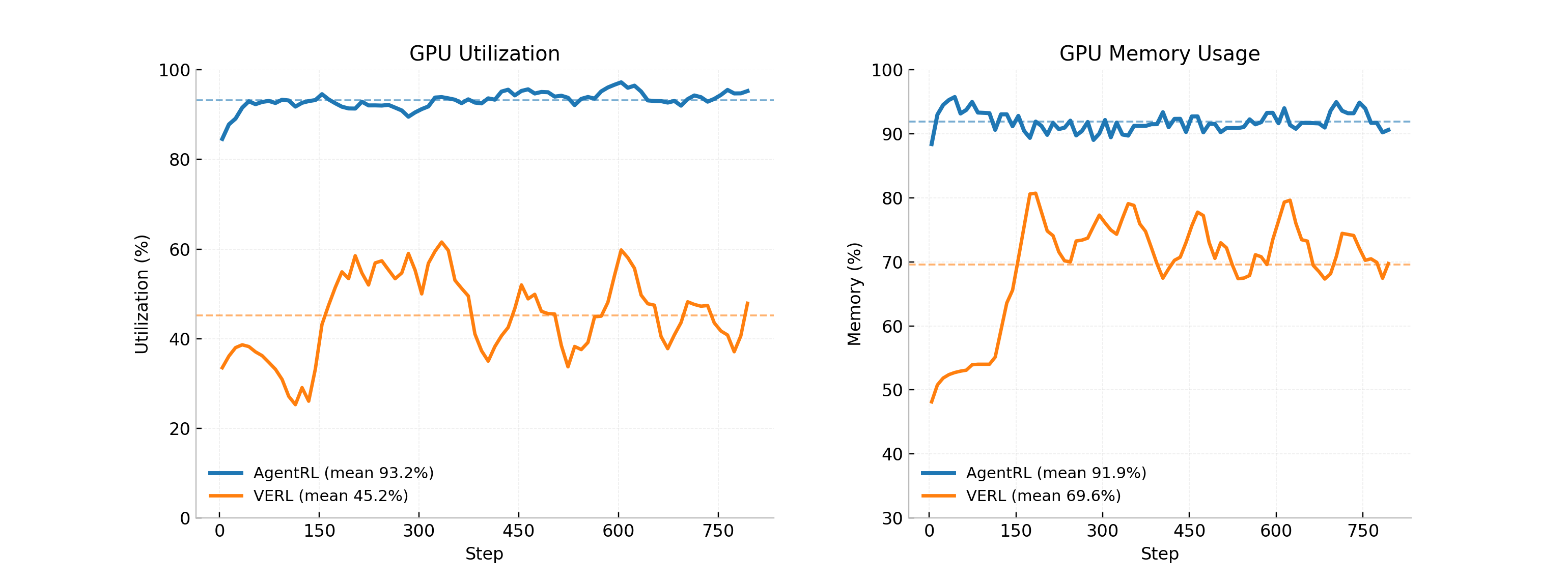
AgentCPM-Explore’s performance benefits significantly from the AgentRL framework, a system engineered for efficient training and resource allocation. By employing asynchronous training methods, the framework maximizes the utilization of available GPU resources, achieving a remarkable 93.2% GPU utilization rate. This represents a substantial improvement over alternative reinforcement learning systems like veRL, which demonstrated only 45.2% GPU utilization. Furthermore, AgentRL exhibits superior GPU memory management, reaching 91.9% utilization compared to veRL’s 69.6%. These advancements in resource efficiency not only accelerate the training process but also enable the development of more complex and capable agents, ultimately contributing to improved performance in challenging reasoning tasks.
AgentCPM-Explore demonstrates a commitment to foundational principles, mirroring the sentiment expressed by Robert Tarjan: “A good algorithm must be correct, and it must be efficient.” The paper’s focus on parameter-efficient model merging and reward signal denoising isn’t simply about achieving strong empirical results; it’s about constructing a robust and mathematically sound agent. By refining context information and tackling the challenges of training smaller models, the researchers prioritize a provable approach to long-horizon task completion. This echoes a belief in elegance derived from mathematical purity, ensuring the agent’s actions are not merely successful on a given test, but fundamentally correct in its approach to problem-solving.
What Remains to be Proven?
The demonstration that reasonable agency can emerge from a model of merely four billion parameters is… intriguing. It suggests the pursuit of scale, while perhaps aesthetically displeasing to those valuing elegance, is not the only path forward. However, the techniques employed – context refinement, reward denoising, and model merging – are, fundamentally, heuristics. They work, undoubtedly, but lack the axiomatic foundation one desires. A rigorous proof that these methods consistently improve convergence, rather than merely mitigating the effects of insufficient capacity, remains elusive. The current work represents an empirical victory, not a mathematical one.
Future efforts should not focus on achieving marginally better performance on existing benchmarks. The true challenge lies in formalizing the principles of efficient reinforcement learning. Can a provably optimal exploration strategy be devised, independent of model size? Can reward functions be constructed such that their gradients are inherently stable, eliminating the need for ‘denoising’? These are the questions that will separate transient improvements from lasting contributions.
The practical implications for edge intelligence are clear, but the underlying theory requires further scrutiny. The current approach addresses the symptoms of small model limitations; a truly elegant solution will address the cause. The pursuit of such a solution, while potentially arduous, is the only path towards a genuinely robust and predictable agent.
Original article: https://arxiv.org/pdf/2602.06485.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-02-10 01:10