Author: Denis Avetisyan
A new approach leverages immediate feedback and informed constraints to dramatically improve policy exploitation in online reinforcement learning environments.
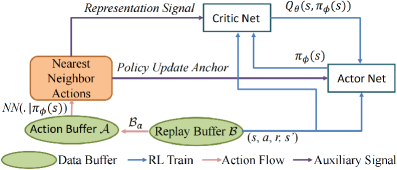
This paper introduces the Instant Retrospect Action (IRA) algorithm, integrating representation learning, policy constraints, and instant updates to enhance value-based reinforcement learning.
Value-based reinforcement learning algorithms often struggle with efficient policy exploitation due to delayed updates and suboptimal exploration. This paper introduces the ‘Improving Policy Exploitation in Online Reinforcement Learning with Instant Retrospect Action’ (IRA) algorithm, which addresses these limitations through a novel approach to learning. IRA enhances policy exploitation by leveraging Q-representation discrepancy evolution for improved state-action representation, incorporating greedy action guidance via historical backtracking, and implementing an instant policy update mechanism. By providing accurate k-nearest-neighbor action value estimates and adaptive policy constraints, can IRA unlock more robust and efficient online learning in complex control tasks?
The Inevitable Struggle for Exploration
Reinforcement learning agents, designed to learn through trial and error, frequently encounter difficulties when tasked with efficiently exploring complex environments, especially those involving continuous control – think of a robot learning to walk or a vehicle navigating a dynamic course. This struggle arises because, in vast state spaces, random exploration becomes incredibly inefficient; the agent spends most of its time experiencing irrelevant states without discovering rewarding actions. Unlike discrete environments where every possible action can be tested, continuous control necessitates navigating an infinite range of possibilities, demanding more sophisticated strategies than simple random actions. Consequently, agents often get stuck in suboptimal policies, failing to discover truly effective solutions due to an inability to adequately sample and learn from the most promising areas of the state space, hindering their overall learning process and performance.
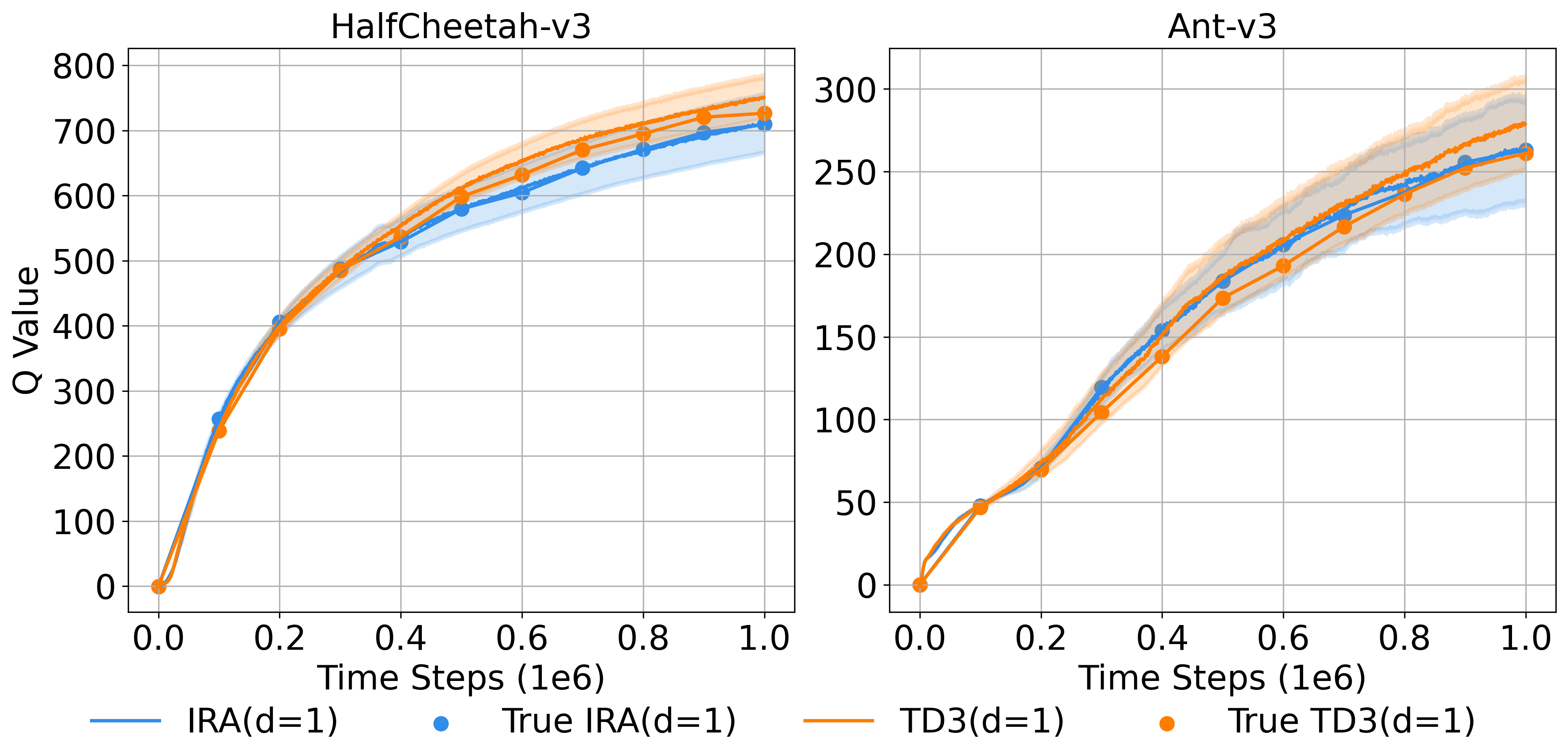
Value-based reinforcement learning, despite its successes in mastering complex environments, frequently encounters a critical flaw: the tendency to overestimate the value of certain actions. This overestimation arises from the inherent challenges in accurately predicting long-term rewards, especially when dealing with limited data or stochastic environments. Consequently, the agent may prioritize suboptimal actions that appear promising due to inflated value predictions, effectively hindering policy improvement. The effect is a self-perpetuating cycle where exaggerated values drive exploration towards less fruitful paths, slowing down learning and potentially preventing the discovery of truly optimal strategies. Addressing this bias is therefore paramount to unlocking the full potential of value-based methods and achieving robust, efficient control.
The pursuit of robust control policies in reinforcement learning is frequently hampered by a critical interplay between overestimation bias and sluggish policy exploitation. Value-based methods, while capable of achieving impressive results, often inflate the estimated value of certain actions, leading the agent to prioritize suboptimal strategies. This exaggeration isn’t merely a numerical quirk; it actively obstructs learning by masking genuinely beneficial options. Compounding this issue is the slow pace at which the agent commits to and refines its chosen actions – a cautious approach that prevents rapid discovery of optimal behaviors. Consequently, the agent remains trapped in a cycle of inflated estimates and hesitant execution, severely limiting its ability to adapt to complex environments and achieve consistently reliable performance. Addressing this bottleneck is therefore paramount to unlocking the full potential of reinforcement learning in real-world applications.
Accelerating Adaptation Through Immediate Feedback
Instant Policy Update addresses slow policy exploitation by increasing the frequency with which the actor network’s parameters are adjusted during reinforcement learning. Traditional methods often update the actor network less frequently, relying on accumulated experience before making adjustments; this can lead to delayed adaptation to changing environments or newly discovered optimal actions. By updating the actor network after each, or nearly each, interaction with the environment, the policy can be refined more rapidly. This allows the agent to immediately leverage new information and accelerate the learning process, potentially leading to improved performance and faster convergence compared to less frequent update schedules. The increased update rate directly combats the issue of the policy lagging behind the optimal behavior as indicated by the critic network.
Increased update frequency allows the agent to modify its control strategy more rapidly in response to incoming experience data. This accelerated refinement process contrasts with traditional methods where policy updates are delayed, potentially leading to suboptimal behavior during extended periods of experience accumulation. By quickly integrating new information into the policy network, the agent minimizes the latency between observation and behavioral adjustment, enabling a more precise and efficient adaptation to the environment’s dynamics and reward structure. This capability is particularly beneficial in non-stationary environments where optimal strategies evolve over time, allowing the agent to track and exploit changing conditions more effectively.
Policy Constraint Algorithms enhance reinforcement learning by restricting the agent’s policy to actions deemed more likely to yield positive outcomes, thereby mitigating the impact of random or ineffective exploration. These algorithms operate by defining constraints on the policy distribution, effectively narrowing the search space and focusing learning on promising areas of the action space. This constrained exploration reduces the time spent on suboptimal strategies, leading to faster convergence and improved sample efficiency. The implementation typically involves adding penalty terms to the reward function or directly modifying the policy update rule to favor actions that satisfy predefined criteria, ultimately accelerating the learning process and enhancing overall performance.
Validation Across the Landscape of Continuous Control
The Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm has been validated across a suite of MuJoCo continuous control environments, demonstrating its efficacy in complex robotic control tasks. These environments include physically demanding simulations such as HalfCheetah, Hopper, Walker2d, Ant, and the more complex Humanoid, as well as simpler balancing tasks like Reacher, InvertedPendulum, and InvertedDoublePendulum. Successful application to this diverse benchmark set indicates TD3’s robustness and adaptability to varying degrees of task difficulty and dimensionality within the continuous control domain.
The Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm has been tested and validated on a suite of complex MuJoCo continuous control tasks, including HalfCheetah, Hopper, Walker2d, Ant, Humanoid, and Reacher. These environments present significant challenges to reinforcement learning agents due to their high dimensionality, continuous action spaces, and the need for precise control to achieve successful locomotion or manipulation. Performance on these benchmarks demonstrates the algorithm’s ability to learn effective policies in scenarios requiring complex motor skills and adaptation to dynamic environments.
The Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm exhibits robust performance not only on complex locomotion tasks but also on benchmark problems with reduced dimensionality, specifically the InvertedPendulum and InvertedDoublePendulum environments. Successful implementation on these simpler tasks demonstrates the algorithm’s adaptability and confirms its ability to effectively learn control policies across a spectrum of problem difficulties. This versatility suggests that the core principles of TD3, including clipped double Q-learning and delayed policy updates, are generally applicable and do not rely on the complexities of high-dimensional state and action spaces.
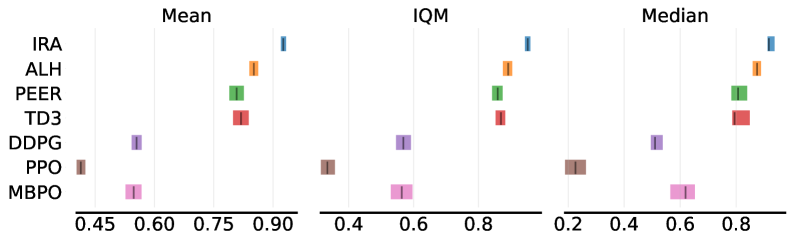
The Instant Retrospect Action (IRA) algorithm achieved a mean performance improvement of 36.9% when tested across a suite of MuJoCo continuous control tasks, including HalfCheetah, Hopper, Walker2d, Ant, Humanoid, and Reacher, relative to the baseline Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. This performance gain was calculated as the average percentage increase in cumulative reward obtained by IRA compared to TD3 across multiple training runs and environments. The observed improvement indicates a substantial advancement in policy optimization and control performance within the tested MuJoCo benchmarks.
The Instant Retrospect Action (IRA) algorithm exhibits significant performance gains when benchmarked against existing reinforcement learning methods on continuous control tasks. Specifically, IRA achieves a 21.4% relative improvement over the Actor-Critic with Hindsight (ALH) algorithm, a 35.6% improvement over PEER, a 135.6% improvement over Deep Deterministic Policy Gradient (DDPG), a 304.5% improvement over Proximal Policy Optimization (PPO), and a 194.6% improvement over Model-Based Policy Optimization (MBPO). These results indicate a substantial advancement in performance relative to these established algorithms across the tested MuJoCo environments.

Towards Systems That Adapt, Not Just React
The consistent performance of algorithms like Twin Delayed Deep Deterministic Policy Gradient (TD3) highlights a fundamental principle in reinforcement learning: the critical role of efficient exploration. Unlike methods that rely on random actions or simplistic strategies, TD3 and its contemporaries actively seek to improve how an agent interacts with its environment to gather informative data. This is achieved through techniques like clipped double Q-learning and delayed policy updates, which reduce overestimation bias and stabilize learning. Consequently, agents can more reliably discover optimal policies, even in complex and stochastic environments where sparse rewards or deceptive local optima might otherwise hinder progress. The success of these methods demonstrates that prioritizing intelligent data collection is paramount for building robust and adaptable learning systems, moving beyond mere exploitation of known rewards to proactively seek out new knowledge.
Recent advancements in reinforcement learning demonstrate that enhanced exploration strategies are critical for accelerating and stabilizing the learning process. Techniques such as instant policy updates allow agents to rapidly incorporate new information from their environment, bypassing the delays inherent in batch-based methods and leading to faster convergence. Simultaneously, constrained algorithms introduce safeguards during exploration, preventing agents from undertaking potentially detrimental actions that could hinder learning or compromise safety. This combination of speed and reliability is particularly valuable in complex environments where sparse rewards or deceptive local optima can easily derail traditional reinforcement learning approaches, ultimately fostering the development of agents capable of consistently achieving optimal performance.
The recent progress in reinforcement learning, driven by techniques that enhance exploration and learning efficiency, signifies a crucial step toward creating agents capable of operating reliably in unpredictable environments. These advancements aren’t merely incremental improvements; they represent a foundational shift, allowing agents to move beyond simulated scenarios and address the inherent complexities of real-world applications. Consider the challenges of robotics, autonomous driving, or resource management – domains characterized by incomplete information, delayed rewards, and constantly changing conditions. The development of robust and generalizable RL agents offers the potential to navigate these uncertainties, adapting to novel situations and consistently achieving desired outcomes without requiring extensive retraining or human intervention. This capability promises to unlock the full potential of artificial intelligence, extending its reach into areas previously considered intractable and fostering a new era of intelligent automation.
The pursuit of robust systems, as demonstrated by this work on Instant Retrospect Action, echoes a fundamental truth: order is merely a temporary reprieve. The algorithm’s focus on representation-guided signals and instant policy updates isn’t about building a perfect policy, but cultivating one resilient enough to navigate inevitable entropy. It acknowledges that even with constraints based on optimal actions, the environment will ultimately reveal the limits of any design. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This work doesn’t seek to create intelligence, but to refine the system’s capacity to learn and adapt within the bounds of its initial programming – a sophisticated form of guided survival.
What Lies Ahead?
The Instant Retrospect Action algorithm, as presented, addresses a predictable failing: the lag between valuation and action in value-based reinforcement learning. It’s a bracing of the system, not a redesign. Each constraint introduced, each action buffered for immediate replay, is an admission that the underlying ecosystem will inevitably attempt to optimize itself into local optima – and that prediction will come true. The question isn’t whether it will fail, but where and when.
Future work will likely focus on the refinement of these predictive braces. More sophisticated representation learning will offer finer-grained control, but will also reveal ever more subtle failure modes. Attempts to build truly general policy constraints seem… optimistic. The real challenge isn’t to prevent failure, but to design systems that fail gracefully, that reveal their internal contradictions through their collapses. Perhaps the metric for success won’t be reward maximized, but predictability of failure.
One wonders if the pursuit of ‘exploitation’ isn’t a misdirection. The system doesn’t need to exploit a learned value function; it needs to survive the inevitable divergence between the map and the territory. Perhaps a focus on resilience – on the capacity to absorb and adapt to unforeseen states – will yield more fruitful results than chasing increasingly precise, yet ultimately fragile, optima.
Original article: https://arxiv.org/pdf/2601.19720.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-01-29 01:08