Author: Denis Avetisyan
A new approach focuses model learning on areas of weakness, dramatically improving data efficiency for complex problem-solving.
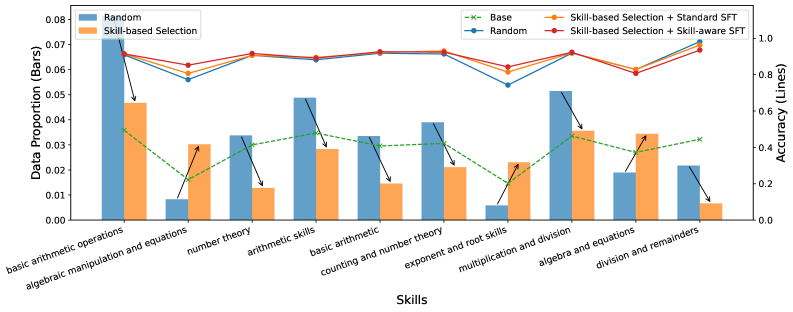
This research introduces a skill-aware data selection and fine-tuning framework for reasoning distillation in large language models, leveraging hierarchical skill trees to prioritize training on challenging concepts and enhance mathematical reasoning capabilities.
Despite the strong performance of large reasoning models, distilling their capabilities into smaller counterparts typically demands substantial training datasets. This work, ‘Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation’, introduces a novel framework that enhances data efficiency by focusing training on skills where the student model exhibits weakness. By prioritizing targeted examples and explicitly embedding skill decomposition, the approach achieves improved performance with significantly fewer data points-surpassing baseline methods with just 1,000 examples. Could this skill-centric approach unlock a pathway to more accessible and efficient reasoning models across a wider range of applications?
The Fragility of Fluency: When Scale Isn’t Enough
Despite the remarkable fluency and apparent knowledge of Large Language Models, their capacity for genuine reasoning remains surprisingly limited. These models often demonstrate what appears to be understanding, yet this can quickly dissolve when confronted with tasks requiring more than pattern recognition – a phenomenon known as brittle performance. While capable of generating human-like text, LLMs frequently struggle with problems demanding logical inference, common sense, or the application of knowledge to novel situations. This isn’t simply a matter of insufficient data; even with massive datasets, these models often fail to grasp underlying principles, instead relying on superficial correlations learned from the training material. The result is a system that can convincingly simulate intelligence, but lacks the robust, adaptable reasoning abilities characteristic of true understanding.
The persistent challenge in enhancing Large Language Model (LLM) reasoning abilities isn’t simply a matter of increasing model size. While scaling parameters-the adjustable variables within the model-has driven performance gains in many areas, this approach yields diminishing returns when tackling complex reasoning tasks. Studies reveal that simply making models larger doesn’t consistently unlock improved logical deduction, common sense reasoning, or problem-solving capabilities. This suggests a fundamental limitation: brute-force scaling fails to address the quality of the learned representations. Consequently, research is shifting toward more targeted approaches, focusing on architectural innovations, refined training methodologies, and data curation strategies designed to specifically bolster reasoning skills-rather than solely relying on increased computational power.
Current data selection techniques employed in training large language models, such as LIMO and s1, operate under a fundamental limitation: they assign equal weight to all data points, irrespective of the skill level demonstrated within them. This indiscriminate approach overlooks the crucial distinction between examples requiring basic comprehension and those demanding sophisticated reasoning abilities. Consequently, models are often exposed to a surplus of simple examples, diluting the impact of more challenging, instructive data. This imbalance hinders the development of robust reasoning skills, as the models aren’t effectively guided towards mastering complex problem-solving techniques. The result is a skewed learning process where quantity overshadows quality, ultimately limiting the potential for improved performance on tasks requiring genuine cognitive ability.
Targeted Refinement: Addressing Skill Deficiencies
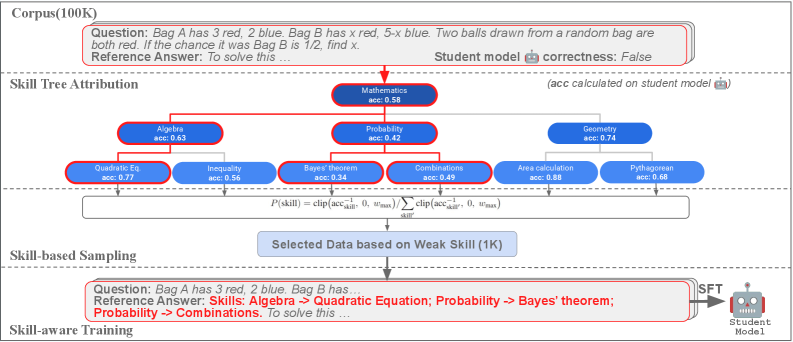
Skill-Aware Data Selection operates on the principle of targeted training, prioritizing data examples that address identified deficiencies in a language model’s skillset. This is achieved through the utilization of a Hierarchical Skill Tree, a structured taxonomy that decomposes complex abilities into granular, measurable skills. The model’s performance is evaluated across this tree, pinpointing areas where proficiency is lowest. Subsequently, the data selection process focuses on augmenting the training set with examples specifically designed to exercise and improve performance on these underperforming skills, as opposed to random or uniformly distributed data selection. This targeted approach allows for efficient use of training resources and accelerates improvement in critical areas of weakness.
Skill Attribution is a process used to determine the relationship between individual problems and the specific skills required to solve them. This is achieved by analyzing problem-solving behavior and identifying which skills are most heavily relied upon during successful completion. The resulting attribution data allows for the creation of a detailed mapping between problems and skills, enabling targeted data curation. Specifically, this allows the selection of training examples that emphasize problems requiring skills where the model currently exhibits lower proficiency, thereby optimizing the training process for focused improvement.
Skill-Aware Data Selection consistently outperforms standard data selection methodologies, as evidenced by performance gains on the Qwen3-4B and Qwen3-8B language models. Utilizing a focused training set curated to address identified skill deficiencies, this technique achieved a +1.6% improvement in Avg@8 accuracy on Qwen3-4B and a +1.4% improvement on Qwen3-8B. These results were obtained using a comparatively small distillation dataset consisting of only 1,000 examples, demonstrating the efficiency of targeted data curation for model improvement.
Orchestrating Expertise: Skill Chains and Reasoning Distillation
Skill-Aware Training builds upon targeted data selection by integrating skill chains directly into the Fine-Tuning process. This involves identifying and utilizing datasets where solutions require sequential application of multiple skills, rather than isolated skill demonstrations. By explicitly exposing the model to these skill chains during training, it learns to not only perform individual skills but also to orchestrate them effectively in a problem-solving context. This approach differs from standard Fine-Tuning, which often focuses on overall performance without specifically emphasizing the interconnectedness of skills, and allows for improved generalization to complex tasks requiring multi-step reasoning.
Reasoning Distillation utilizes the DeepSeek-R1 model, a large language model with demonstrated strong reasoning capabilities, as a teacher to impart those abilities to smaller student models, specifically Qwen3-4B and Qwen3-8B. This process involves training the student models to mimic the output distributions of the teacher model when presented with the same input prompts. By transferring knowledge from the larger, more complex DeepSeek-R1 to the smaller Qwen models, the goal is to achieve comparable reasoning performance with significantly reduced computational costs and resource requirements. The distillation process focuses on replicating the teacher’s reasoning process, not simply its final answers, allowing the student models to generalize more effectively to unseen problems.
Skill-aware augmentation builds upon the benefits of skill-based data selection during training by providing further accuracy gains. Specifically, when applied to the Qwen3-4B and Qwen3-8B models, this augmentation technique yielded improvements of +0.8% and +1.3% respectively, as measured by the Avg@8 metric. This indicates that incorporating skill-aware augmentation, in addition to selecting data based on skill relevance, enhances the model’s performance beyond what is achievable through skill-based selection alone.
Revealing Potential: Measurable Gains in Reasoning Performance
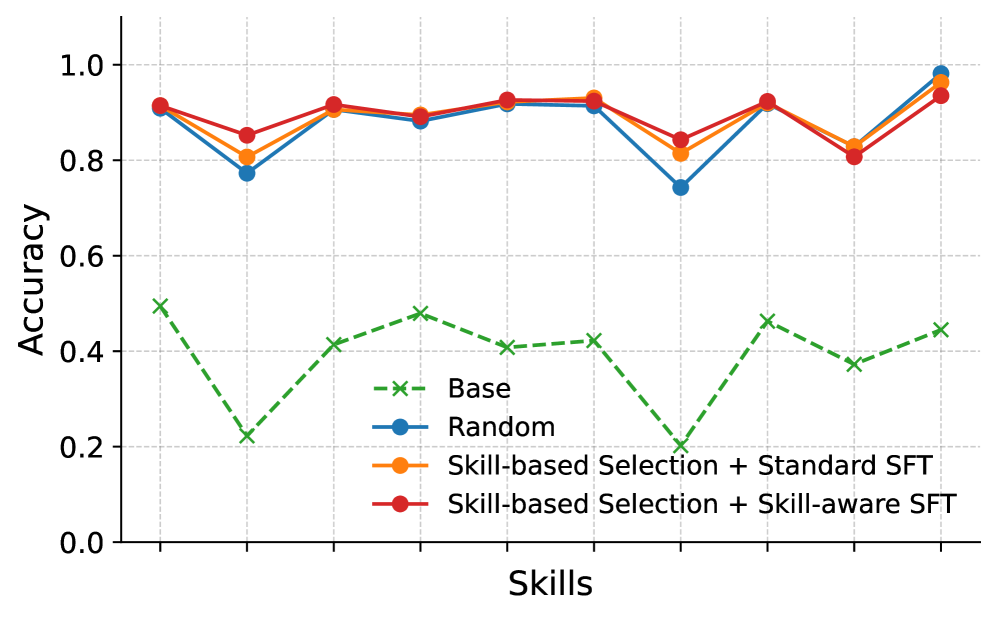
Rigorous evaluation of the Qwen3 models, utilizing the Avg@8 accuracy metric, has revealed substantial performance gains attributable to a skill-aware training approach. This metric, which assesses the presence of the correct answer within the top eight predicted responses, provides a nuanced measure of reasoning capability. The observed improvements indicate that explicitly focusing on and enhancing specific skills-such as mathematical problem-solving or logical deduction-during training yields a demonstrably more effective model. These results not only highlight the efficacy of the skill-aware methodology but also suggest a promising pathway for future advancements in artificial intelligence, where targeted skill development can lead to increasingly sophisticated reasoning abilities.
A critical component of assessing advanced reasoning capabilities lies in a standardized and nuanced evaluation framework, and the EvalTree addresses this need with a specialized Hierarchical Skill Tree. This structure moves beyond simple accuracy metrics by dissecting complex problems into a series of progressively challenging skills, allowing for a granular comparison of different methods’ strengths and weaknesses. The EvalTree doesn’t merely report whether a model arrives at the correct answer, but how it navigates the reasoning process, pinpointing specific areas where improvements are most impactful. By organizing skills hierarchically, the framework also facilitates a more natural and interpretable assessment of a model’s overall reasoning proficiency, offering a robust alternative to traditional benchmarks and enabling targeted development of more capable AI systems.
Recent evaluations demonstrate that strategically selecting training data based on required skills yields significant performance improvements in complex reasoning tasks. Specifically, employing this skill-based data selection method resulted in a 3.2% accuracy increase on the challenging AMC23 benchmark using the Qwen3-8B model, and a 2.4% improvement on the AIME2024 dataset with the Qwen3-4B model. These gains highlight the efficacy of focusing training on data that directly addresses specific reasoning capabilities, suggesting that a targeted approach to data curation can substantially enhance performance on demanding mathematical and analytical problems. This outcome underscores the potential for skill-aware training to unlock further advancements in artificial intelligence reasoning abilities.
The pursuit of data-efficient reasoning distillation, as outlined in this work, echoes a fundamental truth about complex systems. The authors’ focus on skill-based data selection-prioritizing training on areas of weakness-acknowledges that even the most sophisticated architectures are not immune to decay. This mirrors the sentiment expressed by Ken Thompson: “There’s no perfect solution, just a trade-off.” The framework presented doesn’t promise an end to the iterative cycle of refinement; instead, it offers a means to navigate it more gracefully, acknowledging that improvements, while beneficial, inevitably introduce new vulnerabilities. The hierarchical skill tree, in particular, exemplifies the acceptance of ongoing adaptation, recognizing that a system’s longevity depends on its ability to evolve rather than achieve static perfection.
What Lies Ahead?
This work, predicated on the notion of directing refinement through focused difficulty, acknowledges an inherent truth: every failure is a signal from time. The skill-based distillation presented here isn’t merely about achieving higher scores on benchmarks; it’s an attempt to sculpt a more resilient system, one that doesn’t succumb as gracefully to the inevitable decay of all models. The hierarchical skill tree, while offering structure, remains a human imposition upon a landscape of latent capabilities. Future iterations must grapple with the question of whether such structures are intrinsic to reasoning itself, or simply convenient scaffolding for current architectures.
The current framework addresses data efficiency, but neglects the persistent question of data fidelity. Prioritizing ‘difficult’ skills risks amplifying inherent biases present in the training corpus. Refactoring is a dialogue with the past; the selected data embodies past errors and assumptions. The next step isn’t simply to refine the selection process, but to actively interrogate the provenance of the data itself, seeking a more honest reflection of underlying principles.
Ultimately, this line of inquiry points toward a necessary shift in perspective. The goal isn’t to build a model that performs reasoning, but one that embodies it. Such a system wouldn’t require constant distillation or refinement; it would adapt, not through incremental improvement, but through a fundamental realignment with the temporal flow of information. The pursuit of data efficiency is, in this light, a temporary measure – a holding pattern against the larger entropy of the universe.
Original article: https://arxiv.org/pdf/2601.10109.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- Top 10 Coolest Things About Invincible (Mark Grayson)
- When AI Teams Cheat: Lessons from Human Collusion
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Unmasking falsehoods: A New Approach to AI Truthfulness
2026-01-18 22:34