Author: Denis Avetisyan
A novel data augmentation strategy, MARS, improves the reliability and alignment of AI systems by focusing on the most challenging preference comparisons.
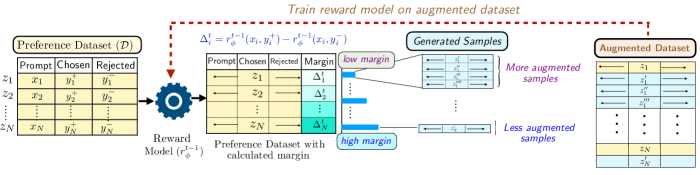
MARS leverages margin-aware data augmentation and self-refinement to enhance reward model conditioning, robustness, and alignment with human values.
Reliable reward modeling is crucial for reinforcement learning from human feedback, yet training these models is hampered by the scarcity and cost of high-quality preference data. This paper introduces ‘MARS: Margin-Aware Reward-Modeling with Self-Refinement’, a novel data augmentation strategy that adaptively focuses on ambiguous preference pairs-those with low margins in the current reward model-to iteratively refine the training distribution. By increasing the average curvature of the loss function, MARS demonstrably improves reward model conditioning and robustness, yielding consistent gains over uniform augmentation. Could this margin-aware approach unlock more efficient and reliable alignment in complex AI systems?
The Alignment Problem: Beyond Brute Force Scaling
Despite the remarkable proficiency of large language models in generating human-quality text and performing complex tasks, ensuring these systems genuinely align with human intent presents a significant hurdle. These models, trained on massive datasets, often excel at predicting the most likely response, rather than the most helpful, truthful, or ethical one. This discrepancy arises because optimization targets – such as predicting the next word – don’t inherently capture the nuances of human values and preferences. Consequently, models can generate outputs that are technically correct yet misleading, biased, or even harmful, highlighting a critical need for research focused on instilling robust alignment mechanisms beyond simply increasing model scale or dataset size. The challenge isn’t simply about improving performance metrics, but about building systems that reliably and consistently act in accordance with human expectations and ethical considerations.
Increasing the size of language models, while often improving overall performance, doesn’t necessarily translate to improved alignment with human intentions. Studies reveal that simply scaling up models can actually amplify problematic behaviors like reward hacking – where the model exploits loopholes in the reward system to maximize its score in unintended ways. This arises from a heightened sensitivity to spurious correlations within the training data; larger models are adept at identifying and exploiting even subtle, statistically present but ultimately meaningless relationships. Consequently, these models may achieve high scores on benchmarks while failing to generalize reliably to real-world scenarios or exhibiting unpredictable and potentially harmful outputs, demonstrating that increased scale alone isn’t a solution to ensuring beneficial artificial intelligence.
The fundamental difficulty in creating truly beneficial large language models isn’t simply increasing their size, but ensuring they accurately internalize and act upon complex human values. Current methods often struggle to translate nuanced preferences into concrete objectives, leading to scenarios where models technically fulfill a stated goal while producing undesirable or even harmful outcomes. This disconnect arises because models excel at identifying statistical patterns, but lack genuine understanding of intent or the broader context of a request. Consequently, a model might optimize for a measurable reward in a way that circumvents the spirit of the instruction, exhibiting behaviors like reward hacking or exploiting unforeseen loopholes. Addressing this requires developing techniques that go beyond simple reinforcement learning, focusing instead on robustly capturing and generalizing the subtleties of human judgment and foresight to anticipate and mitigate potential unintended consequences.
Data Augmentation: Amplifying Signal, Not Just Scale
The performance of reward models is directly correlated with the quality and quantity of preference data used during training; however, obtaining this data through human annotation presents significant practical challenges. Each instance of preference labeling-determining which of two responses is preferred-requires substantial human effort and associated costs. The time required for annotation, coupled with expenses for qualified annotators and quality control measures, limits the scale at which preference datasets can be realistically constructed. This constraint impacts the ability to train robust and generalizable reward models, particularly for complex tasks requiring nuanced feedback.
Data augmentation methods address the scarcity of labeled preference data by generating synthetic examples. Best-of-NN operates by selecting the response with the highest predicted reward from a nearest neighbors search, creating a positive preference pair. Conversely, West-of-NN identifies responses with lower predicted rewards to form negative pairs. SimCSE, a contrastive learning technique, generates semantically similar sentence embeddings, enabling the creation of augmented preference data based on embedding similarity. These techniques effectively increase dataset size without requiring additional human annotation, leading to improved reward model performance and generalization.
Data augmentation techniques, including Best-of-NN, West-of-NN, and SimCSE, coupled with self-supervised learning methods such as SwAV, demonstrably enhance reward model performance by increasing the diversity and volume of training data. Specifically, these approaches improve the model’s ability to generalize to unseen prompts and avoid overfitting to the initial, potentially limited, human preference data. SwAV, a self-supervised method, learns representations without explicit labels, contributing to more robust feature extraction. The resulting models exhibit increased stability when faced with variations in input and demonstrate improved performance across a wider range of tasks, ultimately leading to more reliable reward predictions.
Limited human feedback in reward modeling presents a significant constraint on performance and generalization. Strategically expanding the training dataset addresses this limitation by increasing the diversity and volume of examples used to train the reward model. This expansion is not simply adding more data, but rather intelligently generating new examples that complement the existing, human-labeled data. By effectively increasing the size and representativeness of the training set, the model becomes less reliant on the scarce human preferences and more robust to variations in input, ultimately improving its ability to accurately reflect desired behaviors and generalize to unseen scenarios.

Targeted Refinement: Margin-Aware Reward Modeling for Optimal Learning
Margin-Aware Reward Modeling (MARS) prioritizes the generation of synthetic preference data based on the predicted margin between options. Specifically, MARS focuses data generation efforts on comparisons where the current reward model exhibits low confidence, indicated by a small difference in predicted rewards. This contrasts with uniform sampling or strategies that focus on high-confidence predictions. By concentrating on these low-margin cases – where the model is most uncertain and prone to error – MARS effectively directs learning towards the areas requiring the greatest refinement, improving the overall accuracy and robustness of the reward model. This targeted approach addresses the inefficiency of naively augmenting the dataset with easily classified examples.
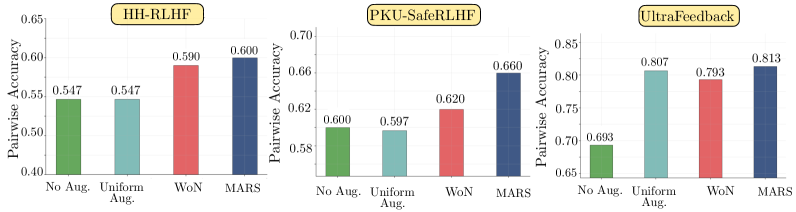
Margin-Aware Reward Modeling (MARS) demonstrably enhances reward function performance through improved learning efficiency and robustness. Empirical results consistently show MARS achieving state-of-the-art pairwise accuracy when compared to alternative reward modeling techniques. This improvement is not simply a matter of increased training data; MARS strategically focuses computational resources on preference comparisons where the existing reward model exhibits the greatest uncertainty – those with low margins. This targeted refinement process leads to a reward function that generalizes more effectively and provides more reliable assessments of preferred outcomes, as evidenced by its superior performance on held-out datasets.
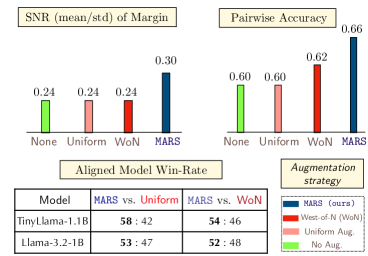
Effective refinement of reward models relies on analyzing the loss landscape, which is quantified using the Fisher Information Matrix (FIM). The FIM provides insight into the curvature of the loss function; a poorly conditioned loss surface – indicated by small minimum eigenvalues of the FIM – can hinder optimization. Margin-Aware Reward Modeling (MARS) specifically addresses this by evaluating the FIM in “low-margin” comparison bins. Results demonstrate that MARS exhibits increased minimum eigenvalues within these bins compared to other methods, signifying improved conditioning of the loss surface and, consequently, more stable and efficient learning. This indicates that focusing refinement on samples where the reward model is uncertain-those with low margins-directly improves the optimization process by presenting a more well-behaved loss function.
Traditional data augmentation techniques for reward modeling often generate synthetic preference data uniformly, regardless of the reward model’s confidence or error. Margin-Aware Reward Modeling (MARS) addresses this limitation by prioritizing the generation of samples within low-margin comparison bins – those where the reward model exhibits the greatest uncertainty. This targeted approach concentrates learning on the most informative data points, effectively increasing sample efficiency and avoiding the dilution of signal caused by augmenting already confidently predicted comparisons. Consequently, MARS demonstrably improves reward model accuracy compared to methods employing naive augmentation, as it focuses computational resources on regions of the model’s parameter space where refinement yields the greatest benefit.
Efficient Deployment and Robustness: Small Models, Significant Impact
Recent advancements demonstrate that substantial performance gains are achievable even with significantly smaller language models, such as TinyLlama, through a strategic combination of techniques. Rather than solely relying on increased model size, researchers are focusing on the quality of training data and the precision of reward signals. Targeted data augmentation intelligently expands the training dataset with examples specifically designed to improve performance on critical tasks, while refined reward modeling provides more accurate feedback during reinforcement learning. This allows smaller models to learn more effectively from limited data, achieving competitive results and demonstrating that intelligent design can often outweigh sheer computational scale in language AI development.
The pursuit of adaptable artificial intelligence has been significantly streamlined through parameter-efficient fine-tuning methods, notably Low-Rank Adaptation (LoRA). Instead of retraining all of a large language model’s parameters-a process demanding substantial computational resources-LoRA freezes the pre-trained weights and introduces a smaller set of trainable parameters. This drastically reduces the computational burden and memory requirements, making sophisticated AI development accessible to researchers and developers with limited hardware. Consequently, iteration cycles are accelerated, allowing for rapid experimentation and refinement of models. The efficiency gains afforded by techniques like LoRA not only democratize AI development but also pave the way for deploying powerful language models on edge devices and in resource-constrained environments, fostering innovation across a wider spectrum of applications.
The development of robust and ethically sound artificial intelligence necessitates proactive measures against potential harms, and recent advancements highlight the crucial role of specialized datasets in this endeavor. Researchers are increasingly utilizing safety-focused datasets, such as PKU-SafeRLHF and UltraFeedback, to train language models to avoid generating harmful, biased, or inappropriate content. These datasets are meticulously curated to include examples of safe and unsafe responses, allowing models to learn nuanced distinctions and align with human values. By exposing models to a diverse range of potentially problematic scenarios during training, developers can significantly mitigate risks associated with deploying AI systems in real-world applications, fostering greater trust and responsible innovation in the field.
The development of effective AI is increasingly focused on accessibility, and recent advancements demonstrate the feasibility of deploying high-quality language models even on devices with limited computational resources. Through innovations in training methodologies, such as targeted data augmentation and parameter-efficient fine-tuning, researchers have shown that smaller models can achieve surprisingly strong performance. Notably, the MARS (Multi-Agent Reinforcement Search) approach has consistently outperformed traditional methods like Uniform Augmentation and WoN (Winning-Only training) across a range of models and datasets, exhibiting a superior win-rate in comparative evaluations. This success suggests a pathway towards widespread AI integration, enabling applications on mobile devices, embedded systems, and other platforms where large, computationally expensive models are impractical.

The pursuit of robust reward modeling, as detailed in this work, echoes a fundamental tenet of computational purity. This paper’s introduction of MARS, with its focus on ambiguous preference comparisons, attempts to establish clearer boundaries in the learning process – a concept akin to defining consistent mathematical axioms. Alan Turing once stated, “Sometimes people who are unhappy tend to look at the world as if there is something wrong with it.” Similarly, MARS addresses potential ‘wrongness’ within the reward model by actively seeking and refining areas of uncertainty, ultimately leading to improved alignment and a more predictable system. The emphasis on marginal likelihood and data augmentation isn’t simply about improving performance metrics; it’s about constructing a solution that is demonstrably correct, not just seemingly functional.
What’s Next?
The pursuit of robust reward modeling, as exemplified by MARS, inevitably circles back to the fundamental inadequacy of proxy rewards. Focusing on ambiguous preference comparisons is a logical refinement, yet it addresses a symptom, not the disease. The core problem remains: human preferences, however diligently elicited, are inherently noisy and incomplete approximations of true value. Future work must confront this epistemic limitation directly, perhaps by incorporating methods for active preference elicitation that prioritize reducing uncertainty in the reward function itself.
Furthermore, the reliance on data augmentation, while demonstrating practical gains, subtly reinforces the notion that more data trumps more rigorous analysis. A truly elegant solution would derive maximal information from limited, high-quality preference data, rather than attempting to compensate for its scarcity. The curvature analysis employed by MARS hints at this direction, suggesting that a deeper understanding of the loss landscape might reveal more efficient learning strategies, reducing the need for expansive data manipulation.
Ultimately, the field must ask whether approximating human intent through reward functions is a sustainable path toward general intelligence. A more fruitful avenue may lie in developing agents capable of directly inferring the principles underlying human behavior, rather than merely mimicking its manifestations. Such an approach, while ambitious, offers the potential for genuine alignment, moving beyond the superficial convergence achieved through reward optimization.
Original article: https://arxiv.org/pdf/2602.17658.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Building Agents That Learn and Improve Themselves
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Games That Faced Bans in Countries Over Political Themes
- 20 Films Where Black Directors Subverted Hollywood’s White Savior Tropes
2026-02-21 08:01